КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Обработка и анализ результатов исследований
|
|
|
|
Основные этапы обработки первичной информации следующие.
Первый этап. Разрабатывается логическая схема обработки и анализа получаемых данных.
Второй этап. В случае обработки данных компьютерными методами осуществляется разработка математического обеспечения, выясняется, какие необходимы программы для обработки материалов исследования, иногда разрабатывается новое программное обеспечение.
Третий этап. Подготовка данных первичной социологической информации к обработке. Работа эта очень трудоемка. Так, при обработке данных анкетирования открытые вопросы анкет «закрывают» - классифицируют по определенным признакам, систематизируют и кодируют в соответствии с классификацией. Осуществляют проверку анкет на качество заполнения. Эта проверка включает три момента:
- на полноту заполнения;
- на надежность (определяется отклонение от репрезентативной выборки, с помощью контрольных и фильтрующих вопросов проверяется качество информации, устраняются противоречивые ответы, умышленно недостоверные, отфильтровываются ответы или анкеты лиц, некомпетентных в исследуемых вопросах и т.д.);
- на технологичность (удобство обработки). Все ответы необходимо привести к виду, дающему возможность легко перенести информацию на машинный носитель для обработки.
Далее подсчитывают все документы, входящие в обрабатываемый массив информации, каждому присваивается порядковый номер. Информация кодируется, т.е. категориям документа присваиваются условные обозначения (шифр, код).
Четвертый этап. Обработка информации (расчет средних величин, установление корреляционных связей, составление группировок, таблиц, графиков и пр.).
Рассмотрим некоторые из перечисленных методов.
1. Простые вариационные ряды. Пусть варьируемый признак (варианта) Хi – стаж. Объем анализируемой совокупности – 8 чел. Тогда частота проявления признака – ni, т.е. количество человек из данной совокупности с данным стажем. Вариационный ряд будет выглядеть так:
Таблица 3.1 – Вариационный ряд
| Хi (стаж, лет) | ||||||
| ni (чел.) |
Помимо частоты распределения варьируемого признака, можно определить его частость (mi), т.е. долю частоты в общем объеме совокупности. Так, частость 6-й варианты (стаж 10 лет) составит:
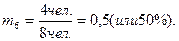
2. Интервальные вариационные ряды. Пример интервального вариационного ряда:
Таблица 3.2 – Вариационный ряд
| Хi (стаж, лет) | До 1 года | Свыше 1 до 5 лет | Свыше 5 до 8 лет | Свыше 8 до 12 лет | и т.д. |
| mi (%) | 20,7 | 10,5 | 8,4 | 15,2 | и т.д. |
Здесь важно выбрать оптимальную величину интервала (более 20 группировочных интервалов делать не рекомендуется). Величина интервала определяется по формуле:
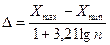 , (3.1)
, (3.1)
где Хmax, Xmin – соответственно максимальное и минимальное значения вариантов в исследуемой совокупности;
n – величина анализируемой совокупности;
lg – десятичный логарифм;
Δ – величина интервала.
Пример. Численность работников составляет 1000 чел., максимальный стаж работы на данном предприятии – 40 лет, минимальный – 1 год,
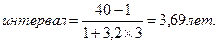
Тогда интервалы могут быть установлены следующим образом:
до 1 года;
1+3,69=4,69≈5 лет;
4,69+3,69=8,38≈8 лет;
8,38+3,69=12,07≈12 лет и т.д.
Могут применяться как равные, так и неравные интервалы.
3. Расчет средних величин. Средняя величина представляет собой абстрактную характеристику всей анализируемой совокупности.
а) Среднеарифметическая величина рассчитывается по формуле:
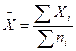 , (3.2)
, (3.2)
где ∑Xi – сумма значений варьируемого признака;
∑ni – сумма всех членов совокупности.
Пример. Если взять за основу данные приведенного выше простого вариационного ряда, то среднеарифметический стаж составит:
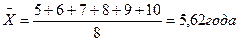 .
.
б) Среднеарифметическая взвешенная величина учитывает частоту проявления признака, последняя выступает в качестве весов. Расчет ведется по формуле:
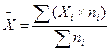 . (3.3)
. (3.3)
Пример. В нашем случае среднеарифметическая взвешенная стажа составит:
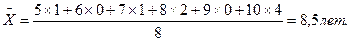
в) Для расчета величин по коэффициентам используется среднегеометрическая величина, рассчитываемая как корень n-й степени из произведения n коэффициентов.
Пример. Имеется 4 коэффициента, характеризующих текучесть кадров в четырех подразделениях предприятия: К1=0,85; К2=0,9; К3=0,4; К4=0,6. Тогда средний коэффициент по четырем подразделениям, рассчитанный как среднегеометрическая величина, составит: 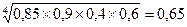
г) Определение медианы – значения признака у той единицы совокупности, которая расположена в середине упорядоченного ряда. Если число членов ряда четное, то медиана определяется как среднеарифметическое из двух серединных значений.
Пример. Имеется упорядоченный ряд:
Таблица 3.3 – Упорядоченный ряд
| № работника | ||||||||
| стаж |
Медиана равна: 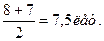

Если число членов ряда нечетное, то за медиану принимается значение признака у среднего члена ряда.
Пример. Если в рассмотренном простом вариационном ряду не было бы 8-го работника, медиана была бы равна значению величины стажа 4-го работника, т.е. 8 лет.
д) Определение моды – наиболее часто встречающегося значения признака (варианты с наибольшей частотой).
Пример. На основе приведенного выше простого вариационного ряда можно определить моду как 10 лет (численность работников с данным значением стажа в анализируемой группе наибольшая).
4. Расчет показателей вариации (колеблемости) признака, оценивающих «разброс» его значений в анализируемой совокупности.
а) Среднее линейное отклонение рассчитывается как средняя арифметическая величина из абсолютных величин отклонения значений признака от его среднеарифметического значения:
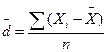 , (3.4)
, (3.4)
где Xi – величина i-го значения признака;
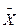 - среднеарифметическое значение признака;
- среднеарифметическое значение признака;
n – общее количество значений признака (единиц совокупности).
в) Коэффициенты вариации (степень рассеяния) признака рассчитываются как отношение среднего линейного или среднего квадратического (дисперсия) отклонения к средней арифметической величине его значения.
5. При анализе данных социологического исследования используются статистические таблицы на основе группировок. Здесь главное – правильный выбор группировочных признаков. Эти таблицы могут быть:
а) простые – перечень всех единиц совокупности с количественной или качественной характеристикой каждой;
б) групповые – единицы совокупности группируются по одному признаку;
в) комбинированные – единицы совокупности группируются по 2-м и более признакам.
6. В ходе анализа могут быть использованы графики, наглядно отражающие распределение исследуемых признаков. Это по существу графическое изображение интервального ряда.
а) Гистограмма на основе данных простого вариационного ряда
Рисунок 3.3 – Гистограмма на основе данных простого вариационного ряда
б) Гистограмма на основе интервального вариационного ряда (общее число единиц совокупности – работников со стажем, входящих в тот или иной интервал, характеризуется площадью прямоугольников).
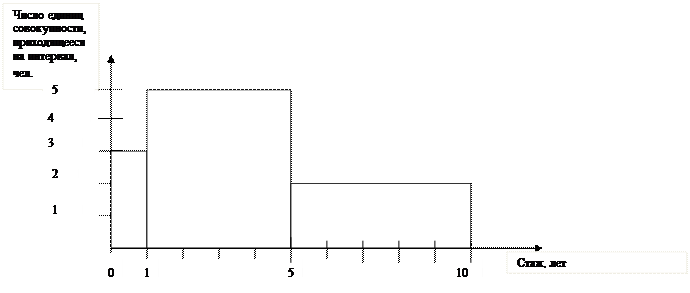
Рисунок 3.4 – Гистограмма на основе интервального вариационного ряда
в) Полигон распределение
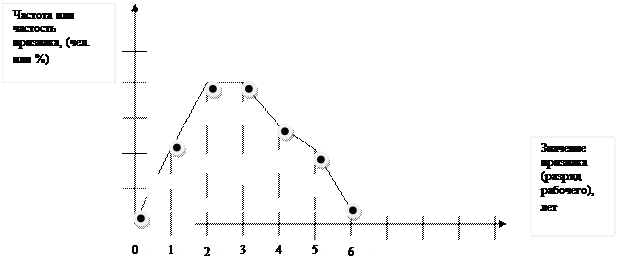
Рисунок 3.5 – Полигон распределения
7. Изучение статических зависимостей. Здесь применяется корреляционный анализ (установление формы, направления, плотности взаимосвязи нескольких признаков); регрессионный анализ (анализ изменения значений результирующего признака в зависимости от влияния на него признаков-факторов); факторный анализ (оценивает вариации признаков и внутренние взаимосвязи).
Помимо перечисленных методов статистического анализ, используются и иные методы. Функциональный анализ нацелен на выявление устойчивых взаимосвязей. Структурный анализ определяет внутренние элементы объекта исследования и их сочетания.
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 1624; Нарушение авторских прав?; Мы поможем в написании вашей работы!