КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Алгоритмы планирования
|
|
|
|
Существует достаточно большой набор разнообразных алгоритмов планирования, которые предназначены для достижения различных целей. Ниже перечислены некоторые наиболее употребительные алгоритмы применительно к процессу кратковременного планирования.
1.Алгоритм FCFS. Простейшим алгоритмом планирования является алгоритм First-Come, First-Served, FCFS – первым пришел, первым обслужен. Когда процесс переходит в состояние готовность, то ссылка на его РСВ помещается в конец очереди. Выбор нового процесса для исполнения осуществляется из начала очереди с удалением оттуда ссылки на его РСВ. Очередь подобного типа имеет в программировании специальное наименование – First In, First Out (FIFO), первым вошел, первым вышел. Данный алгоритм выбора процесса осуществляет невытесняющее планирование. Процесс, получивший в свое распоряжение процессор, занимает его до истечения текущего CPU burst (промежуток времени непрерывного использования процессора). После этого для выполнения выбирается новый процесс из начала очереди. Преимуществом алгоритма FCFS является легкость реализации, но в то же время он имеет и много недостатков. Так как среднее время ожидания и среднее полное время выполнения для этого алгоритма существенно зависят от порядка расположения процессов в очереди, то процессы, перешедшие в состояние готовность, будут долго ждать начала выполнения. Поэтому алгоритм неприменим для систем разделения времени.
2.Алгоритм RR (циклическое планирование). Модификацией алгоритма FCFS является алгоритм Round Robin, RR (вид детской карусели в США). Этот алгоритм реализован в режиме вытесняющего планирования. Готовые к исполнению процессы организованны циклически и вращаются так, чтобы каждый процесс находился около процессора небольшой фиксированный квант времени, обычно 10 – 100 миллисекунд. Пока процесс находится рядом с процессором, он получает процессор в свое распоряжение и может исполняться. Реализуется алгоритм так же, как и предыдущий, с помощью организации процессов, находящихся в состоянии готовность, в очередь FIFO. Планировщик выбирает для очередного исполнения процесс, расположенный в начале очереди, и устанавливает таймер для генерации прерывания по истечении определенного кванта времени. При выполнении процесса возможны два варианта:
- CPU burst меньше или равно продолжительности кванта времени; в этом случае процесс по своей воле освобождает процессор до истечения кванта времени, на исполнение поступает новый процесс из начала очереди и таймер начинает отсчет кванта заново;
- CPU burst процесса больше выделенного кванта времени; в этом случае по истечении кванта процесс прерывается таймером и помещается в конец очереди процессов, готовых к исполнению, а процессор выделяется для использования процессу, находящемуся в ее начале.
На производительность алгоритма RR влияет величина кванта времени. При больших величинах кванта времени, когда каждый процесс успевает завершить свой CPU burst до возникновения прерывания по времени, алгоритм RR преобразуется в алгоритм FCFS. При малых величинах – создается иллюзия, что каждый из n процессов работает на собственном виртуальном процессоре с производительностью ~ 1/n от производительности реального процессора. Кроме того, при частом переключении контекста накладные расходы на переключение резко снижают производительность системы. Алгоритмы FCFS и RR зависят от порядка расположения в очереди процессов, готовых к исполнению. Если короткие задачи расположены в очереди ближе к ее началу, то общая производительность этих алгоритмов значительно возрастает.
3.Алгоритм SJF. Алгоритм краткосрочного планирования Shortest-Job-First, SJF (кратчайшая работа первой) может быть как вытесняющим, так и невытесняющим. При невытесняющем SJF -планировании процессор предоставляется избранному процессу на все необходимое ему время, независимо от событий, происходящих в вычислительной системе. При вытесняющем SJF -планировании учитывается появление новых процессов в очереди готовых к исполнению (из числа вновь родившихся или разблокированных) во время работы выбранного процесса. Если CPU burst нового процесса меньше, чем остаток CPU burst у исполняющегося процесса, то исполняющийся процесс вытесняется новым процессом. Основную сложность при реализации алгоритма SJF представляет невозможность точного знания времени очередного CPU burst для исполняющихся процессов. В пакетных системах количество процессорного времени, необходимое заданию для выполнения, указывает пользователь при формировании задания. Если пользователь укажет больше времени, то он будет ждать результата дольше, если меньшее – то задача может не досчитаться до конца.
4.Алгоритм гарантированного планирования. При интерактивной работе n пользователей в вычислительной системе можно использовать алгоритм планирования, который гарантирует, что каждый из пользователей будет иметь в своем распоряжении ~1/ n часть процессорного времени. Для каждого пользователя используется две величины: Ti – время нахождения пользователя в системе; ti - суммарное процессорное время уже выделенное всем процессам пользователя в течение сеанса работы.
Справедливым для пользователя будет получение Ti / n процессорного времени. Если ti << Ti / n, то i – тый пользователь обделен процессорным временем, если ti >> Ti / n, то i – тый пользователь получает больше расчетного времени процессора. Поэтому для каждого пользовательского процесса вводится значение коэффициента справедливости ti n / Ti и процессу с наименьшей величиной коэффициента предоставляется очередной квант времени. Недостатком алгоритма является невозможность предугадать поведение пользователей. Если пользователь некоторое время не работает с системой, то по возвращению к работе его процессы будут получать неоправданно много процессорного времени.
5.Алгоритм приоритетного планирования. Алгоритмы SJF и гарантированного планирования представляют собой частные случаи приоритетного планирования. При приоритетном планировании каждому процессу присваивается определенное числовое значение – приоритет, в соответствии с которым ему выделяется процессор. Процессы с одинаковыми приоритетами планируются в порядке FCFS. Для алгоритма SJF в качестве такого приоритета выступает оценка продолжительности следующего CPU burst. Чем меньше значение этой оценки, тем более высокий приоритет имеет процесс. Для алгоритма гарантированного планирования приоритетом служит вычисленный коэффициент справедливости. Чем он меньше, тем больше у процесса приоритет. Принципы назначения приоритетов могут опираться:
- на внутренние критерии, которые используют различные количественные и качественные характеристики процесса для вычисления его приоритета: определенные ограничения по времени использования процессора; требования к размеру памяти; число открытых файлов и используемых устройств ввода-вывода; отношение средних продолжительностей I/O burst к CPU burst и др.;
- на внешние критерии, к которым относятся: параметры важности процесса для достижения каких-либо целей; параметры стоимости оплаченного процессорного времени и др.
Приоритетное планирование может вытесняющим и невытесняющим. При вытесняющем планировании процесс с более высоким приоритетом, появившийся в очереди готовых процессов, вытесняет исполняющийся процесс с более низким приоритетом. В случае невытесняющего планирования он становится в начало очереди готовых процессов.
Приоритеты процессов, которые с течением времени не изменялись, называются статическими приоритетами. Механизмы статической приоритетности легко реализовать, однако статические приоритеты не реагируют на изменения ситуации в вычислительной системе. Более гибкими являются динамические приоритеты процессов, изменяющие свои значения по ходу исполнения процессов. Начальное значение динамического приоритета, присвоенное процессу, действует в течение короткого периода времени, после чего ему назначается новое значение. Как правило, изменение приоритета процессов проводится согласованно с совершением каких-либо других операций: при рождении нового процесса, при разблокировке или блокировании процесса, по истечении определенного кванта времени или по завершении процесса. Примерами алгоритмов с динамическими приоритетами являются алгоритм SJF и алгоритм гарантированного планирования.
Главная проблема приоритетного планирования заключается в том, что при неправильном выборе механизма назначения и изменения приоритетов низкоприоритетные процессы могут не запускаться долгое время. Решение этой проблемы может быть достигнуто с помощью увеличения со временем значения приоритета процесса, находящегося в состоянии готовность. Каждый раз по истечении определенного промежутка времени, значения приоритетов процессов, находящихся в состоянии готовность, уменьшаются на 1, а процессу, побывавшему в состоянии исполнение, присваивается первоначальное значение приоритета.
6.Алгоритм многоуровневые очереди (Multilevel Queue). Для систем, в которых процессы рассортированы по разным группам, разработаны алгоритмы планирования на основе очередей. Для каждой группы процессов создается очередь процессов, находящихся в состоянии готовность. Этим очередям приписываются фиксированные приоритеты. Например, приоритет очереди системных процессов устанавливается выше, чем приоритет очередей пользовательских процессов. Это означает, что ни один пользовательский процесс не будет выбран для исполнения, пока имеется хоть один готовый к исполнению системный процесс. Внутри очередей могут применяться разные алгоритмы планирования. Например, для больших счетных процессов, не требующих взаимодействия с пользователем, может использоваться алгоритм FCFS, для интерактивных процессов – алгоритм RR. Данный подход многоуровневых очередей повышает гибкость планирования, так как для процессов с различными характеристиками применяется наиболее подходящий им алгоритм.
7.Алгоритм многоуровневые очереди с обратной связью (Multilevel Feedback Queue). Дальнейшим развитием алгоритма многоуровневых очередей является добавление к нему механизма обратной связи, благодаря которому процесс может мигрировать из одной очереди в другую в зависимости от своего поведения. Планирование процессов между очередями осуществляется на основе вытесняющего приоритетного механизма. Процессы в очереди 1 не могут исполняться, если в очереди 0 есть хотя бы один процесс. Процессы в очереди 2 не будут выбраны для выполнения, пока есть хоть один процесс в очередях 0 и 1 и т.д. Если при работе процесса появляется другой процесс в более приоритетной очереди, исполняющийся процесс вытесняется новым. Планирование процессов внутри очередей 0 – 2 осуществляется с использованием алгоритма RR, в очереди 3 – алгоритма FCFS.
Родившийся процесс поступает в очередь 0. При выборе на исполнение он получает в свое распоряжение квант времени, например, размером 8 единиц. Если продолжительность его CPU burst меньше этого кванта времени, процесс остается в очереди 0. В противном случае он переходит в очередь 1. Для процессов очереди 1 квант времени имеет величину 16. Если процесс не укладывается в это время, он переходит в очередь 2. В очереди 2 величина кванта времени составляет 32 единицы. Если для непрерывной работы процесса этого мало, процесс поступает в очередь 3, для которой квантование времени не применяется и, при отсутствии готовых процессов в других очередях, может исполняться до окончания своего CPU burst. Чем больше значение продолжительности CPU burst, тем в менее приоритетную очередь попадает процесс, но тем на большее процессорное время он может рассчитывать. Таким образом, процессы, требующие малого времени работы процессора, окажутся размещенными в высокоприоритетных очередях, а процессы, требующие большого времени работы процессора и с низкими запросами к времени отклика – в низкоприоритетных.
Миграция процессов в обратном направлении может осуществляться по различным принципам. Например, после завершения ожидания ввода с клавиатуры процессы из очередей 1, 2 и 3 могут помещаться в очередь 0, После завершения дисковых операций ввода-вывода процессы из очереди 3 могут помещаться в очередь 1, а после завершения ожидания всех событий – из очереди 3 в очередь 2. Перемещение процессов из низкоприоритетных очередей в высокоприоритетные позволяет более полно учитывать изменение поведения процессов с течением времени.
Многоуровневые очереди с обратной связью представляют собой наиболее общий подход к планированию процессов, они трудны в реализации, но обладают наибольшей гибкостью. Для полного описания их конкретного воплощения необходимо указать:
- количество очередей для процессов, находящихся в состоянии готовность.
- алгоритм планирования, действующий между очередями;
- алгоритмы планирования, действующие внутри очередей;
- правила помещения родившегося процесса в одну из очередей;
- правила перевода процессов из одной очереди в другую.
Изменяя какой-либо из перечисленных пунктов, можно существенно изменять поведение вычислительной системы.
8.Алгоритмы планирования потоков. Если в системе имеется несколько процессов, каждый из которых разделен на несколько потоков, реализуется два уровня параллелизма: на уровне потоков и на уровне процессов. Планирование в таких системах зависит от того, поддерживаются ли потоки на уровне пользователя, на уровне ядра или и те и другие.
В случае поддержки потоков на уровне пользователя ядро не знает о существовании потоков и выполняет обычное планирование, выбирая, например, процесс А и предоставляя ему квант времени. Внутри процесса А планировщик потоков выбирает поток, например А1. Так как в потоках нет прерывания по таймеру, выбранный поток будет исполняться, пока не завершит свою работу. Если поток А1 займет весь квант времени, выделенный процессу А, ядро передаст управление другому процессу, а при передачи управления снова процессу А, поток А1 продолжит использовать процессорное время до своего завершения. Поведение потока А1 не повлияет на другие процессы и они получат долю процессорного времени, которую планировщик считает справедливой, независимо от того, что происходит внутри процесса.
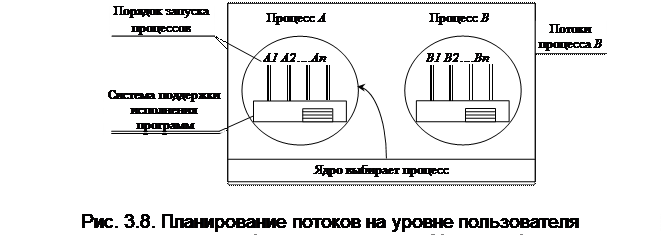
Если n потокам процесса А предоставить равное количество времени t / n из отведенного кванта времени процессу А, то каждый из них будет выполнять свою работу в течении времени t / n и возвращать процессор планировщику потоков. Это приведет к следующей цепочке: А1, А2, А3 … Аn; А1, А2, A3 … Аn, А1… Аn, после чего управление будет передано следующему процессу (рис 3.8.). В качестве алгоритма планирования наиболее часто используются алгоритмы циклического и приоритетного планирования. Единственной проблемой является отсутствие таймера, который прерывал бы затянувшуюся работу потока.
В случае поддержки потоков на уровне ядра, (рис. 3.9.) ядро выбирает следующий поток, не принимая во внимание, какой поток принадлежит какому процессу. Потоку предоставляется квант времени и по истечении этого кванта управление передается другому потоку. Например: А1, А2,…Аn; возможно: А1, В1, А2, В2, А3, В3,… Аn, Bn.
Основное различие между реализацией потоков на уровне пользователя и реализацией их на уровне ядра состоит в производительности. Для переключения потоков на уровне пользователя требуется выполнение нескольких машинных команд. Для переключения потоков на уровне ядра нужно выполнить полное переключение контекста с заменой карты памяти и аннулированием кэша, что выполняется медленнее. С другой стороны, при реализации потоков на уровне пользователя блокировка потока на устройстве ввода-вывода блокирует весь процесс, что не случается с потоками на уровне ядра.
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 21481; Нарушение авторских прав?; Мы поможем в написании вашей работы!