КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Реализация процессов в многопроцессорных системах
Многопроцессорные системы (мультипроцессор) представляют собой компьютерную систему, в которой два или более центральных процессоров делят полный доступ к общей оперативной памяти. В большинстве случаев мультипроцессорные операционные системы представляют собой классические операционные системы, которые обрабатывают системные вызовы, предоставляют службы файловой системы, управляют памятью и устройствами ввода-вывода. В тоже время они обладают уникальными свойствами в таких областях, как синхронизация процессов, планирование, управление ресурсами. По характеру доступа к оперативной памяти мультипроцессорные системы подразделяются на два класса.
1. Симметричные мультипроцессоры UMA (Uniform Memory Access – однородный доступ к памяти) с общей шиной. В основе простейшей архитектуры лежит идея общей шины. Несколько процессоров и несколько модулей памяти одновременно используют одну и ту же шину для общения друг с другом. При обращении к данным, находящимся в памяти, процессор вначале проверяет занятость шины. Если шина свободна, то центральный процессор выставляет на нее адрес данных и несколько управляющих сигналов и ожидает выставление от памяти запрошенных данных на шину. Если шина занята, центральный процессор ожидает ее освобождения.
Решение проблемы простоя процессора заключается в добавлении к центральному процессору кэша и локальной собственной памяти. Но даже при оптимальном использовании кэша наличие одной общей шины ограничивает число UMA -мультипроцессоров (32 или 64). Для преодоления ограничения используются схемы соединения в виде координатного коммутатора 2Х2 (рис.3. 13.) или многоступенчатые коммутаторные сети. Координатный коммутатор имеет два входа и два выхода. Сообщения, поступающие на входную линию (А или В), могут переключаться на любую выходную линию (X или Y). Сообщения состоят из четырех частей (рис. 3.14.). Поле Модуль указывает модуль памяти. Поле Адрес указывает адрес внутри модуля памяти. Поле Код операции указывает операцию (Read или Write – чтение или запись). Необязательное поле Значение может содержать операнд (например, 32-разрядное слово, которое должно быть записано операцией Write) по значению которого коммутатор определяет по какой линии (X или Y) следует отправить сообщение. На основе коммутатора строят многоступенчатые коммутаторные сети.
 |
2. Мультипроцессоры NUMA (Non Uniform Memory Access – неоднородный доступ к памяти). Применяются для создания мультипроцессора с числом центральных процессоров более 100. Ключевые характеристики, отличающие мультипроцессоры NUMA от других мультипроцессоров:
- для всех центральных процессоров имеется единое адресное пространство;
- доступ к удаленным модулям памяти осуществляется при помощи специальных команд процессора Load и Store;
- доступ к удаленным модулям памяти медленнее, чем к локальной памяти.
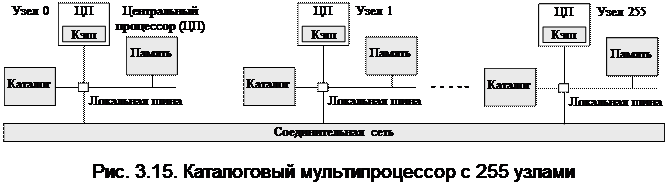
В случае если доступ к удаленной памяти не является скрытым (кэширование не применяется), система называется NC - NUMA (No Cachihg NUMA – система NUMA без кэширования). При наличии когерентных кэш-модулей система называется CC- NUMA (Cache-Coherent NUMA – система NUMA с когерентным кэшированием). Наиболее популярным подходом при построении больших мультипроцессоров CC- NUMA является каталоговый мультипроцессор (рис. 3.15.). Его идея заключается в поддержании базы данных, в которой содержится информация о том, где располагается каждая строка кэша и ее состояние. При обращении к строке кэша база данных получает запрос на поиск этой строки и выдает ее состояние (полная или пустая). Запросы к этой базе данных направляются при каждой команде процессора, обращающейся к памяти.
В ранних вычислительных системах каждый центральный процессор имел свою операционную систему. Простейший способ организации мультипроцессорных операционных систем заключался в статическом разделении оперативной памяти по числу центральных процессоров и предоставлении каждому центральному процессору собственной памяти с собственной копией операционной системы. Данная модель предоставляла возможность центральным процессорам работать по принципу независимых компьютеров, в результате чего имела ряд существенных недостатков.
 |
Вторая модель (рис. 3.16.) заключалась в использовании одной копии операционной системы на одном из центральных процессоров (например, № 1) и все системные вызовы перенаправлялись для обработки на этот центральный процессор (№1). Центральный процессор № 1, если у него оставалась время, выполнял также процессы пользователя. Такая схема называлась «хозяин – подчиненный». В этой модели использовалась единая структура данных (например, один общий список или набор приоритетных списков), учитывающая готовые процессы. При переходе центрального процессора в состояние простоя, он запрашивал у операционной системы процесс, который можно было обрабатывать; при наличии готовых процессов операционная система посылала ему процесс. При такой схеме нагрузка равномерно распределялась на все центральные процессоры и страницы памяти динамически предоставлялись всем процессам. Кроме того в вычислительной системе имелся один общий буферный кэш блочных устройств, поэтому дискам не грозила порча данных. Недостаток данной модели проявлялся в том, что при большом количестве центральных процессоров ведущий компьютер («хозяин») мог быть перегружен системными вызовами от других центральных процессоров.
Наиболее современная третья модель (рис. 3.17.) представляет собой симметричные мультипроцессоры (SMP, Symmetric MultiProcessor) и позволяет устранить все недостатки предыдущих моделей. Как и во второй модели в памяти находится всего одна копия операционной системы, но исполнять ее может любой центральный процессор. При системном вызове на центральном процессоре, обратившемся к системе с системным вызовом, происходит прерывание с переходом в режим ядра и обработка системного вызова. Модель обеспечивает динамический баланс процессов и памяти, поскольку в ней имеется только один набор таблиц операционной системы и позволяет избежать простоя системы, связанного с перегрузкой центрального процессора («хозяина»).
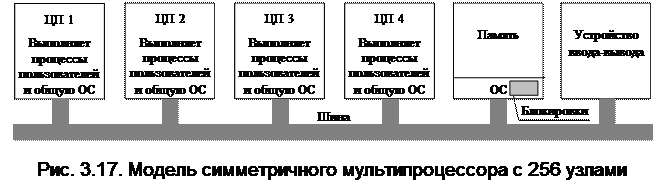
Третья модель так же имеет свои проблемы, например, если код операционной системы будет выполняться одновременно на нескольких центральных процессорах. Простейший способ разрешения этой проблемы заключается в связывании мьютекса (блокировки) с операционной системой, в результате чего вся система превращается в одну большую критическую область. Когда центральный процессор хочет выполнить код операционной системы, он должен вначале получить мьютекс. Если мьютекс заблокирован, процессор переходит в режим ожидания. Таким образом, любой центральный процессор может выполнить код операционной системы, но в определенный момент времени выполнять его будет только один процессор.
В мультипроцессорных системах для синхронизации центральных процессоров используется специальный мьютекс-протокол, который выполняется всеми центральными процессорами для того, чтобы гарантировать работу взаимного исключения. Основой мьютекс-протокола является команда TCL (Test and Set Lock – проверить и установить блокировку) для реализации критических областей. Команда TSL сначала блокирует шину (не допускает обращения к ней других центральных процессоров), затем выполняет обращение к памяти, после чего разблокирует шину.
Для блокировки шины вначале выполняется запрос шины по стандартному протоколу, затем устанавливается в 1 специальная линия шины, чтобы другой процессор не смог получить к ней доступ. Данный способ реализации взаимного исключения использует спин-блокировку [7] и является неэффективным, так как он может накладывать значительную нагрузку на шину или память, существенно снижая скорость работы всех остальных центральных процессоров, пытающихся выполнять свою работу. Проблема разрешается несколькими способами.
Способ 1: избавление от операций записи, вызванных командой TSL запрашивающей стороны. Запрашивающая сторона сначала выполняет простую операцию чтения, чтобы убедиться, что мьютекс свободен. Если мьютекс свободен, центральный процессор выполняет команду TSL, чтобы захватить его. В результате большинство операций опроса представляют собой операции чтения, а не операции записи. Когда мьютекс считан, владелец выполняет операцию записи, для чего требуется монопольный доступ.
Способ 2: использование алгоритма двоичного экспоненциального отката, применяемого в сети Ethernet. Вместо постоянного опроса между опросами вставляется цикл задержки. Вначале задержка представляет собой одну команду. Если мьютекс занят, задержка удваивается, учетверяется и т.д. до некоторого максимального уровня. При низком уровне задержки происходит быстрая реакция при освобождении мьютекса, но требуется больше обращений к шине для чтения блока кэша. Высокий максимальный уровень позволяет уменьшить число лишних обращений к шине за счет более медленной реакции программы на освобождение мьютекса. Использование алгоритма двоичного экспоненциального отката не зависит от применения операций чистого чтения перед командой TSL.
Способ 3: использование переменной блокировки. Каждому центральному процессору, желающему заполучить мьютекс, нужно опросить свою переменную блокировки. Во избежание конфликтов переменная располагается в неиспользуемом для других целей блоке кэша. Работа алгоритма состоит в том, что центральный процессор, которому не удается заполучить мьютекс, захватывает переменную блокировки и присоединяется к концу списка центральных процессоров, ожидающих освобождения мьютекса. Когда центральный процессор, удерживающий мьютекс, покидает критическую область, он освобождает приватную переменную, проверяемую первым центральным процессором в списке (в его собственном кэше). Тем самым следующий центральный процессор получает возможность войти в критическую область. Покинув критическую область, этот процессор освобождает переменную блокировки, тестируемую следующим процессором и т.д. Несмотря на сложность, протокол является эффективным.
В мультипроцессорной системе планирование двумерно и отличается от одномерного планирования в однопроцессорной системе, так как планировщик должен решить какой процесс и на каком центральном процессоре запустить. Другой усложняющий фактор состоит в том, что в некоторых мультипроцессорных системах все процессы независимы[8], а в других системах они формируют группы[9].
Простейший алгоритм планирования независимых процессов или потоков состоит в поддержании единой структуры данных для готовых процессов, например списка или списков для процессов с различными приоритетами. Наличие единой структуры данных планирования, используемой всеми центральными процессорами, обеспечивает процессорам режим разделения времени по аналогии с однопроцессорной системой и позволяет автоматически балансировать нагрузку на центральные процессоры. Недостатки схемы:
- потенциальный рост конкуренции за структуру данных планирования по мере увеличения числа процессоров;
- накладные расходы на переключение контекста при блокировании процесса, ожидающего выполнения операции ввода-вывода.
Для разрешения проблем в некоторых системах используется умное планирование, в котором процесс, захватывающий спин-блокировку, устанавливает флаг, демонстрирующий, что он в данный момент обладает спин-блокировкой. Когда процесс освобождает блокировку, он также очищает и флаг. Таким образом, планировщик не останавливает процесс, удерживающий спин-блокировку, а, напротив, дает ему еще немного времени, чтобы тот завершил выполнение критической области и отпустил мьютекс.
Некоторые мультипроцессоры используют родственное планирование, идея которого состоит в приложении усилий для запуска процесса на том же центральном процессоре, что и в прошлый раз. Один из способов реализации этого метода состоит в использовании двухуровневого алгоритма планирования. В момент создания процесс назначается конкретному центральному процессору. Это назначение процессов процессорам представляет собой верхний уровень алгоритма. В результате каждый центральный процессор получает свой набор процессов. Действительное планирование процессов находится на нижнем уровне алгоритма и выполняется отдельно каждым центральным процессором при помощи приоритетов или других средств. Старания удерживать процессы на одном и том же центральном процессоре максимизируют родственность кэша. Однако если у какого-либо центрального процессора нет работы, у загруженного работой процессора отнимается процесс и отдается ему. Двухуровневое планирование обладает тремя преимуществами:
- равномерно распределяется нагрузка среди имеющихся центральных процессоров;
- используется преимущество родственности кэша;
- минимизируется конкуренция за списки свободных процессов, так как попытки использования списка другого процессора происходят относительно нечасто, поскольку у каждого центрального процессора есть свой собственный список свободных процессов.
Другой подход к планированию используется для процессов, связанных друг с другом. Планирование нескольких процессов или потоков на нескольких центральных процессорах называется совместным использованием пространства или разделением пространства.
Простейший алгоритм разделения пространства работает следующим образом. Предположим, что сразу создается целая группа связанных потоков. В момент их создания планировщик проверяет, есть ли свободные центральные процессоры по количеству создаваемых потоков. Если свободных процессоров достаточно, каждому потоку выделяется собственный центральный процессор и все потоки запускаются. Если процессоров недостаточно, ни один из потоков не запускается, пока не освободится достаточное количество центральных процессоров. Каждый поток выполняется на своем процессоре вплоть до завершения, после чего все центральные процессоры возвращаются в пул свободных процессоров. Если поток оказывается заблокированным операцией ввода-вывода, он продолжает удерживать центральный процессор, который простаивает до тех пор, пока поток не сможет продолжать свою работу. При появлении следующего пакета потоков применяется тот же алгоритм.
Преимущество подхода заключается в устранении многозадачности и снижении накладных расходов по переключению контекста. Недостаток состоит в потерях времени при блокировке центрального процессора. Решением данной проблемы является бригадное планирование, состоящее из трех частей:
- группы связанных потоков планируются как одно целое (бригада);
- все члены бригады запускаются одновременно на разных центральных процессорах с разделением времени;
- все члены бригады начинают и завершают свои временные интервалы вместе.
Бригадное планирование работает благодаря синхронности работы всех центральных процессоров. Время разделяется на дискретные кванты. В начале каждого нового кванта все центральные процессоры перепланируются заново, и на каждом процессоре запускается новый поток. В начале следующего кванта опять принимается решение о планировании. В середине кванта планирование не выполняется. Если какой-либо поток блокируется, его центральный процессор простаивает до конца кванта времени. Идея бригадного планирования состоит в том, чтобы все потоки процесса работали по возможности вместе, так, что если один из них посылает сообщение другому потоку, то второй поток получает сообщение практически мгновенно и может так же быстро на него ответить. Поскольку все потоки работают вместе в течение одного кванта времени, они могут отправлять и принимать большое количество сообщений за один квант времени.
|
|
Дата добавления: 2014-01-07; Просмотров: 1213; Нарушение авторских прав?; Мы поможем в написании вашей работы!