КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Обнаружение одиночных ошибок в устройствах хранения и передачи информации
|
|
|
|
Для дальнейшего изложения потребуется понятие кодовое расстояние по Хеммингу. Для двух двоичных слов кодовое расстояние по Хеммингу есть число разрядов, в которых разнятся эти слова. Так, для слов 11011 и 10110 кодовое расстояние d = 3, так как эти слова различаются в трех разрядах (первом, третьем и четвертом).
Пусть используемые слова имеют m разрядов. Для представления информации можно использовать все 2 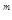 возможных комбинаций от 00... 0 до 11... 1. Тогда для каждого слова найдутся другие такие слова, которые отличаются от данного не более чем в одном разряде. Например, для некоторого слова 1101 можно найти следующие слова: 0101, отличающиеся только в четвертом разряде; 1001, отличающееся только в третьем разряде, и т.д. Таким образом, минимальное кодовое расстояние d
возможных комбинаций от 00... 0 до 11... 1. Тогда для каждого слова найдутся другие такие слова, которые отличаются от данного не более чем в одном разряде. Например, для некоторого слова 1101 можно найти следующие слова: 0101, отличающиеся только в четвертом разряде; 1001, отличающееся только в третьем разряде, и т.д. Таким образом, минимальное кодовое расстояние d 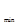 = 1. Обнаружить ошибки в таких словах невозможно. Например, если передавалось слово N
= 1. Обнаружить ошибки в таких словах невозможно. Например, если передавалось слово N  = 1101, а принято N
= 1101, а принято N 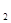 = 0101, то в принятом слове невозможно обнаружить никаких признаков наличия ошибки (ведь могло бы быть передано и слово N = 0101). Для того чтобы можно было обнаружить одиночные ошибки (ошибки, возникающие не более чем в одном из разрядов слова), минимальное кодовое расстояние должно удовлетворять условию d
= 0101, то в принятом слове невозможно обнаружить никаких признаков наличия ошибки (ведь могло бы быть передано и слово N = 0101). Для того чтобы можно было обнаружить одиночные ошибки (ошибки, возникающие не более чем в одном из разрядов слова), минимальное кодовое расстояние должно удовлетворять условию d 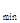 ≥ 2. Это условие требует, чтобы любая пара используемых слов отличалась друг от друга не менее чем в двух разрядах. При этом, если возникает ошибка, она образует такую комбинацию цифр, которая не используется для представления слов, т.е. образует так называемую запрещенную комбинацию.
≥ 2. Это условие требует, чтобы любая пара используемых слов отличалась друг от друга не менее чем в двух разрядах. При этом, если возникает ошибка, она образует такую комбинацию цифр, которая не используется для представления слов, т.е. образует так называемую запрещенную комбинацию.
Для получения d = 2 достаточно к словам, использующим любые комбинации из m информационных двоичных разрядов, добавить один дополнительный разряд, называемый контрольным. При этом значение цифры контрольного разряда выбирают таким, чтобы общее число единиц в слове было четным. Например:

В первом из приведенных примеров число единиц информационной части четно (8), поэтому контрольный разряд должен содержать 0. Во втором примере число единиц в информационной части слова нечетно (7), и для того, чтобы общее число единиц в слове было четным, контрольный разряд должен содержать единицу. Таким способом во все слова вводится определенный признак — четность числа единиц. Принятые слова проверяются на наличие в них этого признака, и, если он оказывается нарушенным (т.е. обнаруживается, что число содержащихся в разрядах слова единиц нечетно), принимается решение, что слово содержит ошибку.
Этот метод позволяет обнаруживать ошибку. Но с его помощью нельзя определить, в каком разряде слова содержится ошибка, т.е. нельзя исправить ее. Кроме того, при этом методе не могут обнаруживаться ошибки четной кратности, т.е. ошибки одновременно в двух, четырех и т.д. разрядах, так как при таком четном числе ошибок не нарушается четность числа единиц в разрядах слова. Однако наряду с одиночными ошибками могут обнаруживаться ошибки, возникающие одновременно в любом нечетном числе разрядов.
На практике часто вместо признака четности используется признак нечетности, т.е. цифра контрольного разряда выбирается такой, чтобы общее число единиц в разрядах слова было нечетным. При этом, если имеет место, например, обрыв линии связи, это обнаруживается, так как принимаемые слова будут иметь 0 во всех разрядах и нарушится принцип нечетности числа единиц.
Рассмотрим схемы, выполняющие операцию проверки на четность (нечетность). Проверка на четность требует суммирования по модулю 2 цифр разрядов слова. Если а 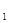 , а ,…, а
, а ,…, а  — цифры разрядов, результат проверки на четность определится выражением р = а ± а ± а
— цифры разрядов, результат проверки на четность определится выражением р = а ± а ± а 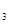 ±,…, ± а . Если р = 0, то число единиц в разрядах слова четно, в противном случае оно нечетно.
±,…, ± а . Если р = 0, то число единиц в разрядах слова четно, в противном случае оно нечетно.
Наиболее просто эта операция реализуется, когда контролируемое слово передается в последовательной форме. Суммирование в этом случае может быть выполнено в последовательности р =...((a ± а ) ± а ) ±... ± а . К результату суммирования р  первых разрядов прибавляется цифра очередного поступающего разряда (i + 1), находится результат суммирования (i + 1) разрядов p
первых разрядов прибавляется цифра очередного поступающего разряда (i + 1), находится результат суммирования (i + 1) разрядов p 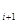 = p
= p 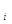 ± а , и так до тех пор, пока не будут просуммированы цифры всех разрядов.
± а , и так до тех пор, пока не будут просуммированы цифры всех разрядов.
Из таблицы истинности
Таблица 1

для операции p = p ± а (табл. 1) видно, что лог.0 не должен менять состояния устройства суммирования (p = p 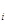 ), лог.1 переводит устройство в новое состояние (p =
), лог.1 переводит устройство в новое состояние (p = 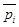 ). Эта логика соответствует работе триггера со счетным входом (рис.1).
). Эта логика соответствует работе триггера со счетным входом (рис.1).
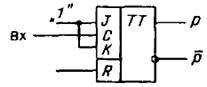
Рис.1. Триггер со счетным входом.
Действительно, пусть триггер был предварительно установлен в состояние 0, после чего на его синхронизирующий вход стали поступать логические уровни, соответствующие цифрам контролируемого слова. При этом первая лог.1 переведет триггер в состояние 1, вторая лог. 1 вернет триггер в состояние 0 и т.д. Следовательно, после подачи четного числа единиц триггер окажется в состоянии р = 0; при поступлении нечетного числа единиц — в состоянии р = 1.
Если разряды контролируемого слова передаются в параллельной форме, то последовательность действий при проверке на четность может быть следующая:
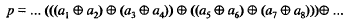
Согласно этому выражению для нахождения р вначале попарно суммируются по модулю 2 цифры разрядов контролируемого слова, далее полученные результаты также суммируются попарно и т.д.
Этот принцип вычисления р использован в схеме проверки на четность на рис.2.
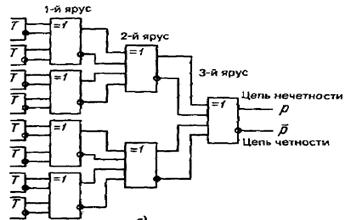
Рис.2. Схема проверки на четность.
Цифры разрядов (и их инверсии) поступают на входы элементов (на рис.2 обозначены =1) первого яруса схемы, в которых они попарно суммируются по модулю 2. Полученные результаты попарно суммируются в элементах второго яруса и т.д.
Результат проверки на четность образуется на выходе элемента старшего яруса. Каждый из элементов схемы реализует следующую логическую функцию:
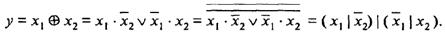
Построенная по данному выражению схема элемента, выполняющего операцию суммирования по модулю 2, приведена на рис.3.
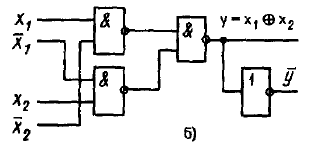
Рис.3.Схема элемента, выполняющего операцию суммирования по модулю 2.
Определим число ярусов и число элементов в этой схеме проверки на четность. Пусть число разрядов n контролируемого слова составляет целую степень двух. Число элементов в отдельных ярусах а  составляет геометрическую прогрессию 1,2,4,8,..., n /2, знаменатель которой q = 2. Для последнего k -то яруса а
составляет геометрическую прогрессию 1,2,4,8,..., n /2, знаменатель которой q = 2. Для последнего k -то яруса а 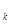 = 1, для первого яруса а = a q
= 1, для первого яруса а = a q 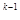 откуда 2 = n /2 или 2
откуда 2 = n /2 или 2 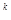 = n.
= n.
Из этого соотношения можно найти число ярусов k. Число суммирующих элементов в схеме равно сумме членов приведенной выше геометрической прогрессии:
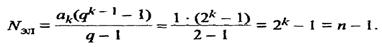
|
|
|
|
|
Дата добавления: 2014-11-25; Просмотров: 1073; Нарушение авторских прав?; Мы поможем в написании вашей работы!