КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Общие принципы использования избыточности
|
|
|
|
Разновидности помехоустойчивых кодов
Коды, которые обеспечивают возможность обнаружения и исправления ошибки, называют помехоустойчивыми.
Эти коды используют для:
1) исправления ошибок – корректирующие коды;
2) обнаружения ошибок.
Корректирующие коды основаны на введении избыточности.
У подавляющего большинства помехоустойчивых кодов помехоустойчивость обеспечивается их алгебраической структурой. Поэтому их называют алгебраическими кодами.
Алгебраические коды подразделяются на два класса:
1) блоковые;
2) непрерывные.
В случае блоковых кодов процедура кодирования заключается в сопоставлении каждой букве сообщения (или последовательности из k символов, соответствующей этой букве) блока из n символов. В операциях по преобразованию принимают участие только указанные k символов, и выходная последовательность не зависит от других символов в передаваемом сообщении.
Блоковый код называют равномерным, если n остается постоянным для всех букв сообщения.
Различают разделимые и неразделимые блоковые коды. При кодировании разделимыми кодами выходные последовательности состоят из символов, роль которых может быть отчетливо разграничена. Это информационные символы, совпадающие с символами последовательности, поступающей на вход кодера канала, и избыточные (проверочные) символы, вводимые в исходную последовательность кодером канала и служащие для обнаружения и исправления ошибок.
При кодировании неразделимыми кодами разделить символы входной последовательности на информационные и проверочные невозможно.
Непрерывными (древовидными) называют такие коды, в которых введение избыточных символов в кодируемую последовательность информационных символов осуществляется непрерывно, без разделения ее на независимые блоки. Непрерывные коды также могут быть разделимыми и неразделимыми.
Способность кода обнаруживать и исправлять ошибки обусловлена наличием в нем избыточных символов.
На вход кодирующего устройства поступает последовательность из k информационных двоичных символов. На выходе ей соответствует последовательность из n двоичных символов, причем n>k.
Всего может быть 2k различных входных и 2n различных выходных последовательностей.
Из общего числа 2n выходных последовательностей только 2k последовательностей соответствуют входным. Их называют разрешенными кодовыми комбинациями.
Остальные 2n-2k возможных выходных последовательностей для передачи не используются. Их называют запрещенными кодовыми комбинациями.
Искажения информации в процессе передачи сводятся к тому, что некоторые из передаваемых символов заменяются другими – неверными.
Так как каждая из 2k разрешенных комбинаций в результате действия помех может трансформироваться в любую другую, то всегда имеется 2k*2n возможных случаев передачи. В это число входят:
1) 2k случаев безошибочной передачи;
2) 2k(2k –1) случаев перехода в другие разрешенные комбинации, что соответствует необнаруженным ошибкам;
3) 2k(2n – 2k) случаев перехода в неразрешенные комбинации, которые могут быть обнаружены.
Следовательно, часть обнаруживаемых ошибочных кодовых комбинаций от общего числа возможных случаев передачи составляет
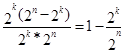 .
.
Пример22: Определить обнаруживающую способность кода, каждая комбинация которого содержит всего один избыточный символ (n=k+1).
Решение: 1. Общее число выходных последовательностей составляет 2k+1, т.е. вдвое больше общего числа кодируемых входных последовательностей.
2. За подмножество разрешенных кодовых комбинаций можно принять, например, подмножество 2k комбинаций, содержащих четное число единиц (или нулей).
3. При кодировании к каждой последовательности из k информационных символов добавляют один символ (0 или 1), такой, чтобы число единиц в кодовой комбинации было четным. Исполнение любого нечетного числа символов переводит разрешенную кодовую комбинацию в подмножество запрещенных комбинаций, что обнаруживается на приемной стороне по нечетности числа единиц. Часть опознанных ошибок составляет
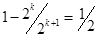 .
.
Любой метод декодирования можно рассматривать как правило разбиения всего множества запрещенных кодовых комбинаций на 2k пересекающихся подмножеств Mi, каждая из которых ставится в соответствие одной из разрешенных комбинаций. При получении запрещенной комбинации, принадлежащей подмножеству Mi, принимают решение, что передавалась запрещенная комбинация Ai. Ошибка будет исправлена в тех случаях, когда полученная комбинация действительно образовалась из Ai, т.е. 2n-2k cлучаях.
Всего случаев перехода в неразрешенные комбинации 2k(2n – 2k). Таким образом, при наличии избыточности любой код способен исправлять ошибки.
Отношение числа исправляемых кодом ошибочных кодовых комбинаций к числу обнаруживаемых ошибочных комбинаций равно
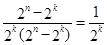 .
.
Способ разбиения на подмножества зависит от того, какие ошибки должны направляться конкретным кодом.
Большинство разработанных кодов предназначено для корректирования взаимно независимых ошибок определенной кратности и пачек (пакетов) ошибок.
Взаимно независимыми ошибками называют такие искажения в передаваемой последовательности символов, при которых вероятность появления любой комбинации искаженных символов зависит только от числа искаженных символов r и вероятности искажения обычного символа p.
При взаимно независимых ошибках вероятность искажения любых r символов в n-разрядной кодовой комбинации:
 ,
,
где p – вероятность искажения одного символа;
r – число искаженных символов;
n – число двоичных символов на входе кодирующего устройства;
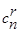 – число ошибок порядка r.
– число ошибок порядка r.
Если учесть, что p<<1, то в этом случае наиболее вероятны ошибки низшей кратности. Их следует обнаруживать и исправлять в первую очередь.
4.3 Связь корректирующей способности кода с кодовым расстоянием
При взаимно независимых ошибках наиболее вероятен переход в кодовую комбинацию, отличающуюся от данной в наименьшем числе символов.
Степень отличия любых двух кодовых комбинаций характеризуется расстоянием между ними в смысле Хэмминга или просто кодовым расстоянием.
Кодовое расстояние выражается числом символов, в которых комбинации отличаются одна от другой, и обозначается через d.
|

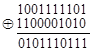
(Сложение ”по модулю 2”: y= х1 Å х2, сумма равна 1 тогда и только тогда, когда х1 и x2 не совпадают).
Минимальное расстояние, взятое по всем парам кодовых разрешенных комбинаций кода, называют минимальным кодовым расстоянием.
Более полное представление о свойствах кода дает матрица расстояний D, элементы которой dij (i,j = 1,2,…,m) равны расстояниям между каждой парой из всех m разрешенных комбинаций.
Пример23: Представить симметричной матрицей расстояний код х1 = 000; х2 = 001; х3 = 010; х4 = 111.
Решение. 1. Минимальное кодовое расстояние для кода d=1.
2. Симметричная матрица четвертого порядка для кода
Таблица 4.1.
| x1 | x2 | x3 | x4 | ||
| x1 | |||||
| x2 | |||||
| x3 | |||||
| x4 |
Декодирование после приема производится таким образом, что принятая кодовая комбинация отождествляется с той разрешенной, которая находится от нее на наименьшем кодовом расстоянии.
Такое декодирование называется декодированием по методу максимального правдоподобия.
Очевидно, что при кодовом расстоянии d=1 все кодовые комбинации являются разрешенными.
Например, при n=3 разрешенные комбинации образуют следующее множество: 000, 001, 010, 011, 100, 101, 110, 111.
Любая одиночная ошибка трансформирует данную комбинацию в другую разрешенную комбинацию. Это случай безызбыточного кода, не обладающего корректирующей способностью.
Если d = 2, то ни одна из разрешенных кодовых комбинаций при одиночной ошибке не переходит в другую разрешенную комбинацию. Например, подмножество разрешенных кодовых комбинаций может быть образовано по принципу четности в нем числа единиц. Например, для n=3:
000, 011, 101, 110 – разрешенные комбинации;
001, 010, 100, 111 – запрещенные комбинации.
Код обнаруживает одиночные ошибки, а также другие ошибки нечетной кратности (при n=3 тройные).
В общем случае при необходимости обнаруживать ошибки кратности до r включительно минимальное хэммингово расстояние между разрешенными кодовыми комбинациями должно быть по крайней мере на единицу больше r, т.е d0 min³r+1.
Действительно, в этом случае ошибка, кратность которой не превышает r, не в состоянии перевести одну разрешенную кодовую комбинацию в другую.
Для исправления одиночной ошибки кодовой комбинации необходимо сопоставить подмножество запрещенных кодовых комбинаций.
Чтобы эти подмножества не пересекались, хэммингово расстояние между разрешенными кодовыми комбинациями должно быть не менее трех. При n=3 за разрешенные кодовые комбинации можно, например, принять 000 и 111. Тогда разрешенной комбинации 000 необходимо приписать подмножество запрещенных кодовых комбинаций 001, 010, 100, образующихся в результате двоичной ошибки в комбинации 000.
Подобным же образом разрешенной комбинации 111 необходимо приписать подмножество запрещенных кодовых комбинаций: 110, 011, 101, образующихся в результате возникновения единичной ошибки в комбинации 111:
|
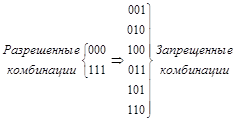
Рис. 4.1.
В общем случае для обеспечения возможности исправления всех ошибок кратности до s включительно при декодировании по методу максимального правдоподобия, каждая из ошибок должна приводить к запрещенной комбинации, относящейся к подмножеству исходной разрешенной кодовой комбинации.
Любая n-разрядная двоичная кодовая комбинация может быть интерпретирована как вершина m-мерного единичного куба, т.е. куба с длиной ребра, равной 1.
При n=2 кодовые комбинации располагаются в вершинах квадрата:
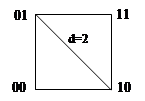
Рис. 4.2.
При n=3 кодовые комбинации располагаются в вершинах единичного куба:
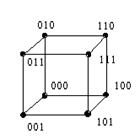
Рис. 4.3.
В общем случае n-мерный единичный куб имеет 2n вершин, что равно наибольшему возможному числу кодовых комбинаций.
Такая модель дает простую геометрическую интерпретацию и кодовому расстоянию между отдельными кодовыми комбинациями. Оно соответствует наименьшему числу ребер единичного куба, которые необходимо пройти, чтобы попасть от одной комбинации к другой.
Ошибка будет не только обнаружена, но и исправлена, если искаженная комбинация остается ближе к первоначальной, чем к любой другой разрешенной комбинации, то есть должно быть:  или
или 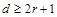
В общем случае для того, чтобы код позволял обнаруживать все ошибки кратности r и исправлять все ошибки кратности s (r>s), его кодовое расстояние должно удовлетворять неравенству d ³ r+s+1 (r³s).
Метод декодирования при исправлении одиночных независимых ошибок можно пояснить следующим образом. В подмножество каждой разрешенной комбинации относят все вершины, лежащие в сфере с радиусом (d-1)/2 и центром в вершине, соответствующей данной разрешенной кодовой комбинации. Если в результате действия помехи комбинация переходит в точку, находящуюся внутри сферы (d-1)/2, то такая ошибка может быть исправлена.
Если помеха смещает точку разрешенной комбинации на границу двух сфер (расстояние d/2) или больше (но не в точку, соответствующую другой разрешенной комбинации), то такое искажение может быть обнаружено.
Для кодов с независимым искажением символов лучшие корректирующие коды – это такие, у которых точки, соответствующие разрешенным кодовым комбинациям, расположены в пространстве равномерно.
Проиллюстрируем построение корректирующего кода на следующем примере. Пусть исходный алфавит, состоящий из четырех букв, закодирован двоичным кодом: х1 = 00; х2 = 01; х3 = 10; х4 = 11. Этот код использует все возможные комбинации длины 2, и поэтому не может обнаруживать ошибки (так как d=1).
Припишем к каждой кодовой комбинации один элемент 0 или 1 так, чтобы число единиц в нем было четное, то есть х1 = 000; х2 = 011; х3 = 101; х4 = 110.
Для этого кода d=2, и, следовательно, он способен обнаруживать все однократные ошибки. Так как любая запрещенная комбинация содержит нечетное число единиц, то для обнаружения ошибки достаточно проверить комбинацию на четность (например, суммированием по модулю 2 цифр кодовой комбинации). Если число единиц в слове четное, то сумма по модулю 2 его разрядов будет 0, если нечетное – то 1. Признаком четности называют инверсию этой суммы.
Рассмотрим общую схему организации контроля по четности (контроль по нечетности, parity check – контроль по паритету).
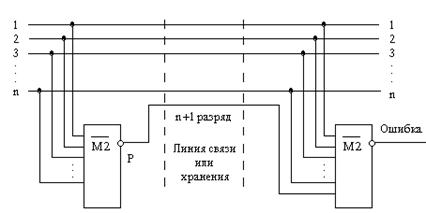
Рис. 4.4.
На n-входовом элементе  формируется признак четности Р числа, который в качестве дополнительного, (n+1)-го контрольного разряда (parity bit) отправляется вместе с передаваемым словом в линию связи или запоминающее устройство. Передаваемое (n+1)-разрядное слово имеет всегда нечетное число единиц. Если в исходном слове оно было нечетным, то инверсия функции М2 от такого слова равна 0, и нулевое значение контрольного разряда не меняет число единиц при передаче слова. Если же число единиц в исходном слове было четным, то контрольный разряд Р для такого числа будет равен 1, и результирующее число единиц в передаваемом (n+1)-разрядном слове станет нечетным. Вид контроля, когда по линии передается нечетное число единиц, по строгой терминологии называют контролем по нечетности.
формируется признак четности Р числа, который в качестве дополнительного, (n+1)-го контрольного разряда (parity bit) отправляется вместе с передаваемым словом в линию связи или запоминающее устройство. Передаваемое (n+1)-разрядное слово имеет всегда нечетное число единиц. Если в исходном слове оно было нечетным, то инверсия функции М2 от такого слова равна 0, и нулевое значение контрольного разряда не меняет число единиц при передаче слова. Если же число единиц в исходном слове было четным, то контрольный разряд Р для такого числа будет равен 1, и результирующее число единиц в передаваемом (n+1)-разрядном слове станет нечетным. Вид контроля, когда по линии передается нечетное число единиц, по строгой терминологии называют контролем по нечетности.
На приемном конце линии или из памяти от полученного (n+1)-разрядного слова снова берется свертка по четности, Если значение этой свертки равно 1, то или в передаваемом слове, или в контрольном разряде при передаче или хранении произошла ошибка. Столь простой контроль не позволяет исправить ошибку, но он, по крайней мере, дает возможность при обнаружении ошибки исключить неверные данные, затребовать повторную передачу и т.д.
Систему контроля можно построить на основе не только инверсии функции М2, но и прямой функции М2 (строго контроль по четности). Однако, в этом случае исходный код “все нули” будет иметь контрольный разряд, равный 0. В линию отправится посылка из сплошных нулей, и на приемном конце она будет неотличима от весьма опасной неисправности – полного пропадания связи. Поэтому контроль по четности в своем чистом виде почти никогда не применяют, контрольный разряд формируют как четности, и в нестрогой терминологии “контролем по четности” называют то, что, строго говоря, на самом деле является контролем по нечетности.
Контроль по четности основан на том, что одиночная ошибка (безразлично – пропадание единицы или появление линией) инвертирует признак четности. Однако две ошибки проинвертируют его дважды, то есть оставят без изменения, поэтому двойную ошибку контроль по четности не обнаруживает. Рассуждая аналогично, легко прийти к выводу, что контроль по четности обнаруживает все нечетные ошибки и не реагирует на любые четные. Пропуск четных ошибок – это не какой-либо дефект системы контроля. Это следствие предельно малой избыточности, равной всего одному разряду. Для более глубокого контроля требуется соответственно и большая избыточность. Если ошибки друг от друга не зависят, то из не обнаруживаемых чаще всего будет встречаться двойная ошибка, а при вероятности одиночной ошибки, равной Р, вероятность двойной будет Р2. Поскольку в нормальных цифровых устройствах P<<1, необнаруженные двойные ошибки встречаются значительно реже, чем обнаруженные одиночные. Поэтому далее при таком простом контроле качество работы устройства существенно возрастает. Это верно лишь для взаимно независимых ошибок.
Признаки четности можно использовать для контроля только неизменяемых данных. При выполнении над данными каких-либо логических операций признаки четности слов в общем изменяются, и попытки компенсировать эти изменения оказываются неэффективными. Счастливое исключение – операция арифметического сложения: сумма по модулю 2 признаков четности двоичных слагаемых и всех, возникших в процессе сложения переносов, равна признаку четности кода арифметической суммы этих слагаемых.
Контроль по четности – самый дешевый по аппаратурным затратам вид контроля, и применяется он очень широко. Практически любой канал передачи цифровых данных или запоминающее устройство, если они не имеют какого-либо более сильного метода контроля, защищены контролем по четности.
Продолжим рассмотрение примера построения корректирующего метода. Чтобы код был способен и исправлять однократные ошибки, необходимо добавить еще не менее двух разрядов. Это можно сделать различными способами, например, повторить первые две цифры:
х1 = 00000; х2 = 01101; х3 = 10110; х4 = 11011;
Матрица расстояний этого кода:
Таблица 4.2.
| x1 | x2 | x3 | x4 | ||
| D= | x1 | ||||
| x2 | |||||
| x3 | |||||
| x4 |
Видно, что d ³ 3, что отвечает неравенству (d ³ 2+3+1).
Пример23: Постройте корректирующий код для передачи двух сообщений:
1) обнаруживающий одну ошибку;
2) обнаруживающий и исправляющий одну ошибку;
3) обнаруживающий две и исправляющий одну ошибку.
|
|
|
|
|
Дата добавления: 2014-11-25; Просмотров: 1131; Нарушение авторских прав?; Мы поможем в написании вашей работы!