КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Эффективное кодирование
|
|
|
|
Дополнительные настройки при создании PDF-файла
Кликают по значку принтера Adobe PDF правой кнопкой мыши и выбирают Настройку печати. Все самое полезное размещено на вкладке Adobe PDF Settings.Можно выбрать шаблон, по которому будут создаваться файлы: High Quality (для создания PDF с высоким разрешением и повышенным качеством) или Smallest file size (для уменьшения объема файла). А можно создать собственные шаблоны, нажав на кнопку Edit.
Здесь же можно задать настройки безопасности. Можно установить отсутствие защиты (None) или предписать программе спрашивать об опциях безопасности при каждом создании PDF (Reconfirm security for each job) — в этом случае необходимо нажать расположенную рядом кнопку Edit и задать пароль, которым будет блокироваться доступ к новым файлам. Там же скрываются такие полезные функции, как парольный запрет некоторых возможностей работы с файлом: можно разрешить открытие файла, но запретить его печать или сохранение в др
При кодировании каждая буква исходного алфавита представляется различными последовательностями, состоящими из кодовых букв (цифр).
Если исходный алфавит содержит m букв, то для построения равномерного кода с использованием k кодовых букв необходимо удовлетворить соотношение m £ kq, где q - количество элементов в кодовой последовательности.
Поэтому
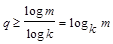
Для построения равномерного кода достаточно пронумеровать буквы исходного алфавита и записать их коды как q - разрядные числа в k-ичной системе счисления.
Например, при двоичном кодировании 32 букв русского алфавита используется q = log232 = 5 разрядов, на чем и основывается телетайпный код.
Кроме двоичных кодов, наибольшее распространение получили восьмеричные коды.
Пусть, например, необходимо закодировать алфавит, состоящий из 64 букв. Для этого потребуется q = log264 = 6 двоичных разрядов или q = log864 = 2 восьмеричных разрядов. При этом буква с номером 13 при двоичном кодировании получает код 001101, а при восьмеричном кодировании 15.
Обще признанным в настоящее время является позиционный принцип образования системы счисления. Значение каждого символа (цифры) зависит от его положения - позиции в ряду символов, представляющих число.
Единица каждого следующего разряда больше единицы предыдущего разряда в m раз, где m - основание системы счисления. Полное число получают, суммируя значения по разрядам:
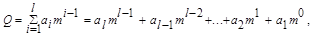
где i - номер разряда данного числа; l - количество рядов; аi - множитель, принимающий любые целочисленные значения в пределах от 0 до m-1 и показывающий, сколько единиц i - ого ряда содержится в числе.
Часто используются двоично-десятичные коды, в которых цифры десятичного номера буквы представляются двоичными кодами. Так, например, для рассматриваемого примера буква с номером 13 кодируется как 0001 0011. Ясно, что при различной вероятности появления букв исходного алфавита равномерный код является избыточным, т.к. его энтропия (полученная при условии, что все буквы его алфавита равновероятны): logkm = H0
всегда больше энтропии H = log m данного алфавита (полученной с учетом неравномерности появления различных букв алфавита, т.е. информационные возможности данного кода используются не полностью).
Например, для телетайпного кода Н0 = logk m = log232 = 5 бит, а с учетом неравномерности появления различных букв исходного алфавита Н» 4,35 бит. Устранение избыточности достигается применением неравномерных кодов, в которых буквы, имеющие наибольшую вероятность, кодируются наиболее короткими кодовыми последовательностями, а более длинные комбинации присваиваются редким буквам. Если i-я буква, вероятность которой Рi, получает кодовую комбинацию длины qi, то средняя длина комбинации
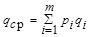
Считая кодовые буквы равномерными, определяем наибольшую энтропию закодированного алфавита как qср log m, которая не может быть меньше энтропии исходного алфавита Н, т.е. qср log m ³ Н.
Отсюда имеем
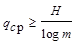
При двоичном кодировании (m=2) приходим к соотношению qср ³ Н, или
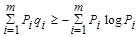
Чем ближе значение qср к энтропии Н, тем более эффективно кодирование. В идеальном случае, когда qср» Н, код называют эффективным.
Эффективное кодирование устраняет избыточность, приводит к сокращению длины сообщений, а значит, позволяет уменьшить время передачи или объем памяти, необходимой для их хранения.
При построении неравномерных кодов необходимо обеспечить возможность их однозначной расшифровки. В равномерных кодах такая проблема не возникает, т.к. при расшифровке достаточно кодовую последовательность разделить на группы, каждая из которых состоит из q элементов. В неравномерных кодах можно использовать разделительный символ между буквами алфавита (так поступают, например, при передаче сообщений с помощью азбуки Морзе).
Если же отказаться от разделительных символов, то следует запретить такие кодовые комбинации, начальные части которых уже использованы в качестве самостоятельной комбинации. Например, если 101 означает код какой-то буквы, то нельзя использовать комбинации 1, 10 или 10101.
Практические методы оптимального кодирования просты и основаны на очевидных соображениях ( метод Шеннона – Фано).
Прежде всего, буквы (или любые сообщения, подлежащие кодированию) исходного алфавита записывают в порядке убывающей вероятности. Упорядоченное таким образом множество букв разбивают так, чтобы суммарные вероятности этих подмножеств были примерно равны. Всем знакам (буквам) верхней половины в качестве первого символа присваивают кодовый элемент 1, а всем нижним 0. Затем каждое подмножество снова разбивается на два подмножества с соблюдением того же условия равенства вероятностей и с тем же условием присваивания кодовых элементов в качестве второго символа. Такое разбиение продолжается до тех пор, пока в подмножестве не окажется только по одной букве кодируемого алфавита. При каждом разбиении буквам верхнего подмножества присваивается кодовый элемент 1, а буквам нижнего подмножества - 0.
Пример16: Провести эффективное кодирование ансамбля из восьми знаков:
Таблица 3.1.
| Буква (знак) xi | Вероят-ность Рi | Кодовые последовательности | Длина qi | рi qi | -рilog рi | ||||
| Номер разбиения | |||||||||
| x1 | 0,25 | 0,5 | 0,50 | ||||||
| x2 | 0,25 | 0,5 | 0,50 | ||||||
| x3 | 0,15 | 0,45 | 0,41 | ||||||
| x4 | 0,15 | 0,45 | 0,41 | ||||||
| x5 | 0,05 | 0,2 | 0,22 | ||||||
| x6 | 0,05 | 0,2 | 0,22 | ||||||
| x7 | 0,05 | 0,2 | 0,22 | ||||||
| x8 | 0,05 | 0,2 | 0,22 | ||||||
= 2,7
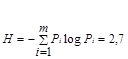
Как видно, qср = H, следовательно, полученный код является оптимальным.
Пример17: Построить код Шеннона - Фано, если известны вероятности: Р(x1) = 0,5; P(x2)= 0,25; P(x3) = 0,125; P(x4) = 0,125
Пример18: Провести эффективное кодирование ансамбля из восьми знаков (m=8), используя метод Шеннона - Фано.
Решение: При обычном (не учитывающем статистических характеристик) двоичном кодировании с использованием k=2 знаков при построении равномерного кода количество элементов в кодовой последовательности будет q ³ logk m = log2 8 = 3, т.е. для представления каждого знака использованного алфавита потребуется три двоичных символа.
Метод Шеннона - Фано позволяет построить кодовые комбинации, в которых знаки исходного ансамбля, имеющие наибольшую вероятность, кодируются наиболее короткими кодовыми последовательностями. Таким образом, устраняется избыточность обычного двоичного кодирования, информационные возможности которого используются не полностью.
Таблица 3.2.
| Знаки (буквы) xi | Вероятность Pi | Кодовые комбинации | |||||||
| номер разбиения | |||||||||
| x1 | 1/2 | ||||||||
| x2 | 1/4 | ||||||||
| x3 | 1/8 | ||||||||
| x4 | 1/16 | ||||||||
| x5 | 1/32 | ||||||||
| x6 | 1/64 | ||||||||
| x7 | 1/128 | ||||||||
| x8 | 1/128 | ||||||||
Так как вероятности знаков представляют собой отрицательные целочисленные степени двойки, то избыточность при кодировании устранена полностью.
Среднее число символов на знак в этом случае точно равно энтропии. В общем случае для алфавита из восьми знаков среднее число символов на знак будет меньше трех, но больше энтропии алфавита. Вычислим энтропию алфавита:
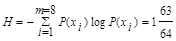
Вычислим среднее число символов на знак:
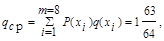
где q(xi) - число символов в кодовой комбинации, соответствующей знаку xi.
Пример19: Определить среднюю длину кодовой комбинации при эффективном кодировании по методу Шеннона - Фано ансамбля - из восьми знаков и энтропию алфавита.
Таблица 3.3.
| Знаки (буквы) xi | Вероятность Pi | Кодовые комбинации | ||||
| номер разбиения | ||||||
| x1 | 0,22 | |||||
| x2 | 0,20 | |||||
| x3 | 0,16 | |||||
| x4 | 0,16 | |||||
| x5 | 0,10 | |||||
| x6 | 0,10 | |||||
| x7 | 0,04 | |||||
| x8 | 0,02 |
Решение: 1. Средняя длина кодовых комбинаций
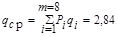
2. Энтропия алфавита
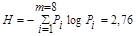
При кодировании по методу Шеннона - Фано некоторая избыточность в последовательностях символов, как правило, остается (qср > H).
|
|
|
|
|
Дата добавления: 2014-11-25; Просмотров: 1554; Нарушение авторских прав?; Мы поможем в написании вашей работы!