КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Аксиоматические методы. 4 страница
|
|
|
|
Это минимальное количество информации I=1, получило название «бит» (от английских слов binary digit – двоичный знак). Если в (1) использовать натуральные логарифмы, то единица информации называется «нат». Между битами и натами существуют соотношения:
1 бит = 1.44 ната;
1 нат = 0.69 бита.
Поскольку в компьютере, калькуляторе содержится стандартная функция для вычисления натуральных логарифмов, то в практическом плане удобнее сначала вычислить количество информации в натах, а затем перевести в биты, умножив на 1.44.
Рассмотрим иную ситуацию – выбор варианта (напомним, что в системном анализе варианты называются альтернативами).
Если делаем выбор одного из n возможных вариантов (с известными вероятностями этих вариантов pi, i= 1;2;…n) то количество информации, то количество информации определяется по формуле:
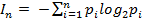
| (2) |
Если все варианты равновероятны: 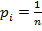 , тогда формула (2) принимает вид:
, тогда формула (2) принимает вид:

| (3) |
Это исторически первая формула теории вероятностей, формула Хартли.
В частном случае бинарного алфавита (M=2; 0 и 1) число вариантов равно 2N; pi = E-N; log2pi = -N; I=N.
Это совпадает с (1) при бинарном равновероятном алфавите и N символах в сообщении.
Формулы (1) и (2) отражают количество информации, но не ее ценность. Количество информации в сообщении, определяемое формулой Шеннона, не зависит от сочетания букв: переставив (случайным образом или кодированием) буквы мы можем делать сообщение бессмысленным. Количество информации по Шеннону сохранится, а ценность информации может исчезнуть.
Эта информация (по Шеннону) полезна в статистической теории связи, но бесполезна в системном анализе и других дисциплинах, занимающихся знаниями.
Количество и ценность информации – разные понятия и не стоит подменять одно другим.
Допустим, что любое сочетание букв в тексте является ценным. В этом умозрительном, нереальном случае количество ценной информации совпадает с полным количеством, определяемым формулой (2) и не может превышать его. По жизни ценной информации в тексте меньше, иногда её нет вообще. Поэтому максимальное количество информации в (2) названо информационной тарой [Корогодин]. Это понятие играет существенную роль при рецепции (приеме/ передаче) информации и при ее перекодировке.
Текст на русском языке содержит Nr букв кириллицы (алфавит содержит 32 буквы; Mr =32;). Английский перевод содержит Na букв; Ma=26; Русский текст – результат выбора определенного варианта из Na = 32Na возможных. Английский перевод – выбор (преопределенный русским текстом) одного варианта из Na = 26 Na возможных. Если смысл не искажён, то количество ценной информации одинаково, а количество информации по Шеннону различно. Процессы генерации, рецепции обработки сопровождаются «переливаем» информации из одной тары в другую. При этом, как правило, количество информации по Шеннону уменьшается, а количество ценной информации сохраняется и, даже, возрастает.
Таким образом, информационная тара – это мощность множества, из которого могут быть выбраны варианты (алфавит, слова, тексты). Информационная емкость – свойство информационных систем (например, информационная емкость компакт-диска равна 720 МБ).
Ценность информации
Создатель классической теории информации К. Шеннон отметил, что смысл (т.е. семантика) сообщений не имеет никакого отношения к его теории информации и занимающегося текстовыми сообщениями. Но возможность точного измерения информации в сообщениях, созданная теорией информации Шеннона, наводила на мысль о возможности существования способов измерения информации более общего вида – макроинформации Кастлера и Чернавского и семантической информации, содержащейся в предложениях естественного или (хотя бы) формализованного языка.
Эта задача далека от своего решения, но имеет всё возрастающее теоретическое и практическое значение.
Понятия ценности, осмысленности информации – центральные в современной информатике, системном анализе. Ценностью информации, смыслом сообщений занимается семантическая теория информации.
Основные положения семантической теории информации.
1. Ценность информации зависит от цели.
Если цель достижима, то ценность информации может быть определена по уменьшению затрат на её достижение.
Если достижение цели – не обязательно то ценность информации V по Бонгарду и Харкевичу равна:
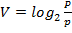
| (5) |
p - вероятность достижения цели до получения информации (она в знаменателе формулы);
P - вероятность достижения после получения информации (она в числителе);
Априорная вероятность p зависит от информационной тары, от полного количества информации I, определяемого по формуле (2): p=2-I.
Так если все варианты равновероятны то p=1/n; I=log2n;
Апостериорную вероятность P может быть как больше, так и меньше p; тогда (P < p). Это – дезинформация. При изменении апостериорной вероятности P в пределах 0<P<1, ценность информации по Бонгарду и Харкевичу изменяется в пределах -∞<V<Vmax;
Ценность информации по Корогодину даётся формулой:
V= 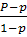
| (6) |
Она изменяется в пределах V ≤ V≤ 1.
2. Ценность информации зависит от величины p, от так называемого тезауруса (предварительной информации).
Если предварительной информации нет, то p=  ;
;
а если p=1 то ценность V=Vmax = log2n; т.е. совпадает с максимальным количеством информации в данном множестве символов (в данной информационной таре).
Это совпадение не случайно, именно для этого была выбрана формула (5) для определения ценности информации– при этом ценность информации можно понимать как количество ценной информации.
В формуле (6) при
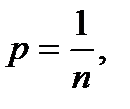 P = 1 получаем:
P = 1 получаем: 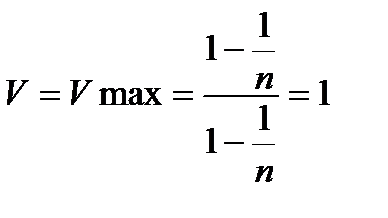 .
.
Итак, по Бонгарду-Харкевичу:
-∞ < V ≤ log2n.
По Корогодину (здесь нет понятия дезинформации)
0 ≤ V ≤ 1.
3. Количество информации, имеющей нулевую ценность, как правило, не мало с количеством информации, имеющем хоть какую-то ценность для реципиента (получателя).
Понятно, что ценность информации субъективна – она зависит от целей и тезауруса реципиента.
Бессмысленная информация – это информация, не имеющая ценности ни для кого из тех, кого интересует смысл текста. Соответственно, как противоположность, возникает понятие осмысленной информации.
Объективность понятия «осмысленная информация» основана на следующем утверждении: в информационной таре, куда может быть помещена данная информация, можно выделить определенное количество информации, которая ни для кого, ни для каких дел не понадобится. Это – бессмысленная информация, все остальное – осмысленная. Но! Осмысленность текста зависит от тезауруса. Для человека, не знающего иероглифов, любой текст, составленный из них – текст бессмысленный.
Итак, различение понятий «количество информации», «ценность информации», «осмысленность информации» очень важно.
Во-первых, в традиционной информатике, основанной на классической теории информации (названной автором, Шенноном «математической теорией связи»), не существуют и не обсуждаются вопросы о ценной информации, её возникновении и эволюции. Ценность рассматривается в предположении, что цель задана извне. Вопрос о спонтанном возникновении цели внутри системы не рассматривается.
С точки зрения теории систем, здесь рассматриваются процессы в связях, а системному анализу нужны и связи, и элементы. И понятие цели играет в системном анализе основополагающую роль, поскольку он занимается целенаправленными системами.
В синергетике где также исследуются эти проблемы, показано [Чернавский], что ценность информации способна эволюционировать: неценная информация становится ценной, а бессмысленная – осмысленной, и наоборот. Цели системы могут возникать, меняться и исчезать в процессе развития.
Во-вторых, отождествление понятий просто информации, ценной информации, осмысленной информации приводит к недоразумениям. Для них невозможно дать единое объективное (воспринимаемое всеми) и конструктивное (полезное для развития науки и практики) определение. Напротив, разделив эти понятия можно дать конструктивное определение каждому из них, оговорить меру условности и субъективности.
Вот еще две меры, связанные с истинностью информации [Лидовский].
Первая:
inf(s) = -log2 p(s) = -1.44 ln p(s)
где s – предложение, смысл которого измеряется;
p(s) – вероятность того, что предложение S – истинно.
Понятно, что эта мера подходит только для простых предложений. Но тем не менее.
Некоторые свойства функции inf(s):
1) inf(s) ≥ 0 поскольку 0 ≤ p(s) ≤ 1;
2) при p(s) = 1, inf(s) = 0 (в тривиальном (истинном) предложении никакой информации не содержится);
3) при p(s) → 0, inf(s) → ∞ – чем неожиданнее сообщение, тем больше информации в нём содержится.
Из свойств (2) и (3) следует, что p(s) совпадает с априорной информацией р в формулах Бонгарда и Корогодина.
Но здесь это «внешняя» информация, находящаяся в сообщении, а там – «внутренняя», определяемая также и тезаурусом получателя.
4) если s1 → s2 (из s1 следует s2) истинна, то inf(s1) ≥ inf(s2);
5) условия независимости: inf(s1s2) = inf(s1) + inf(s2) ↔ p(s1) * p(s2) = p(s1*s2).
Значение функции-меры inf(s) больше для предложений, исключающих большое количество возможностей. Пример: из s1: “a > 3” из s2: “а = 7”, следует, что s1 → s2 и inf(s2) > inf(s1). Ясно, что s2 исключает больше возможностей, чем s1.
Вторая:
cont(s) = 1 - p(s).
Связь между этими мерами даётся формулами:
cont(s) = 1 – 2-inf(s)= 1 – e-0.69 inf(s);
inf(s) = -log2(1 - cont(s)) = -0.69ln(1 – inf(s))
Контрольные вопросы
1) Фундаментальность понятия «информация», основное отличие информации от материи и энергии.
2) Формула Шеннона для сообщения, единицы измерения информации.
3) Формула Шеннона для выбора, связь с системным анализом.
4) Формула Хартли, единицы измерения информации.
5) Основные информационные процессы и системный анализ.
6) Значение и недостаточность классической теории информации для системного анализа.
7) Роль информации в живой природе и технике.
8) Какие вопросы изучает теория информации – «классическая» и семантическая.
9) Дайте собственное определение понятию «информация».
10) Что называют сигналом, для чего служат сигналы? Типы сигналов.
11) Соотношения между единицами информации: бит, байт, килобайт, нат. Сколько битов и натов содержится в 1 Мб?
12) Связь между понятиями «энтропия» и «информация» в теории информации.
13) В алфавите 10 символов, вероятности их появления в сообщении равны. Найти количество информации по Шеннону (в битах и натах) в сообщении из 10+n символов, где n – Ваш номер в списке группы.
14) В алфавите 4 символа, вероятности их появления в сообщении возрастают по линейному закону начиная с p1=0.1. Найти количество информации по Шеннону (в битах и натах) в сообщении из 12+2n символов, где n – Ваш номер в списке группы.
15) Определение информации по Кастлеру и Чернавскому.
16) Понятия «ценная информация», «осмысленная информация», «тезаурус».
17) Понятия «информационный объём» и «информационная тара».
18) Какие характеристики информации сохраняются, а какие нет при переводе информации из одной информационной тары в другую?
19) Мера ценности информации по Бонгарду-Харкевичу.
20) Мера ценности информации по Корогодину.
21) Вероятностные меры семантики высказываний.
22) Сравнить классический и семантический подходы к информации для задач системного анализа.
23) Основные информационные процессы. Рецепция и генерация ценной информации.
24) За счёт каких процессов может возрастать количество ценной информации в системе?
25) Найти ценность информации по Бонгарду-Харкевичу, если после её получения вероятность достижения цели увеличилась в 4 раза.
26) Найти апостериорную вероятность достижения цели, если после получения сообщения ценность информации по Бонгарду-Харкевичу составила V=3. Априорная вероятность равна 1/(10+n), где n – Ваш номер в списке группы.
27) Найти ценность информации по Корогодину, если после её получения вероятность достижения цели увеличилась в e раз.
28) Найти апостериорную вероятность достижения цели, если после получения некоторого сообщения ценность информации по Корогодину составила V =0.99. Априорная вероятность равна 1/(10+n), где n – Ваш номер в списке группы.
2.3.2. Вербальный анализ решений
Основой вербального анализа решений (ВАР) является качественное (вербальное, то есть словесное) описание проблемы, которое сохраняется (без перевода ее в числовую форму) на всех этапах анализа.
Теоретическое обоснование. Методологически ВАР опирается на психологические модели человеческой системы переработки информации, теории поведения индивида при решении многокритериальных задач.
Подход ВАР позволяет постепенно разработать решающее правило методом "проб и ошибок", характерным для поведения человека. Предусмотрена возможность получения для ЛПР объяснений результатов анализа в виде, понятном для ЛПР. Подход ВАР опирается на некоторые результаты многокритериальной теории полезности, связанные с выполнением условий независимости. Эти результаты используются при вербальных оценках.
Измерения. В рамках подхода ВАР большое значение уделяется проблемам получения информации от ЛПР и экспертов. В качестве языка описания (структуризации) решаемой проблемы используется естественный язык, привычный для ЛПР и экспертов. Разрабатываются порядковые шкалы оценок по критериям с вербальными оценками. Далее осуществляются логические операции преобразования вербальной информации. Все процедуры получения информации от ЛПР основаны на использовании вербальных оценок качества по отдельным критериям.
В отличие от подхода количественного анализа решений (КАР), где информация берется "одномоментно" в полном виде, в подходе ВАР получение информации ЛПР - поэтапное.
Пример. Рассмотрим пример описания проблемы и выбора варианта решения двумя подходами - КАР и ВАР.
Пусть имеется проблема выбора наилучшего проекта на конкурсе проектов решения крупной социально-технической задачи (например, предотвращение наводнений в крупном городе, постройка завода по переработке отходов и т.д.). Предположим, что конкурсная комиссия подготовила следующий список критериев для оценки проектов.
А. Эффективность проекта.
Б. Воздействие на окружающую среду.
В. Стоимость реализации.
Г. Шансы на реализацию в намеченный срок.
Пусть на конкурс поступило три проекта.
Рассмотрим, как задача выбора наилучшего проекта может быть решена методом КАР. ЛПР (конкурсная комиссия) и эксперты, оценивают проекты по приведенным выше критериям.
Пусть по каждому критерию имеется количественная шкала оценок от 0 (худшая) до 100 (лучшая). Далее назначается самый важный критерий. Предположим, что это – эффективность проекта. Она изображается графически в виде столбика (рис. 2.3). Эксперта просят графически определить оценки по другим критериям, сравнивая их с высотой столбика, соответствующего эффективности. Кроме того, ЛПР определяет сопоставимую важность (веса) критериев в виде столбиков различной высоты.
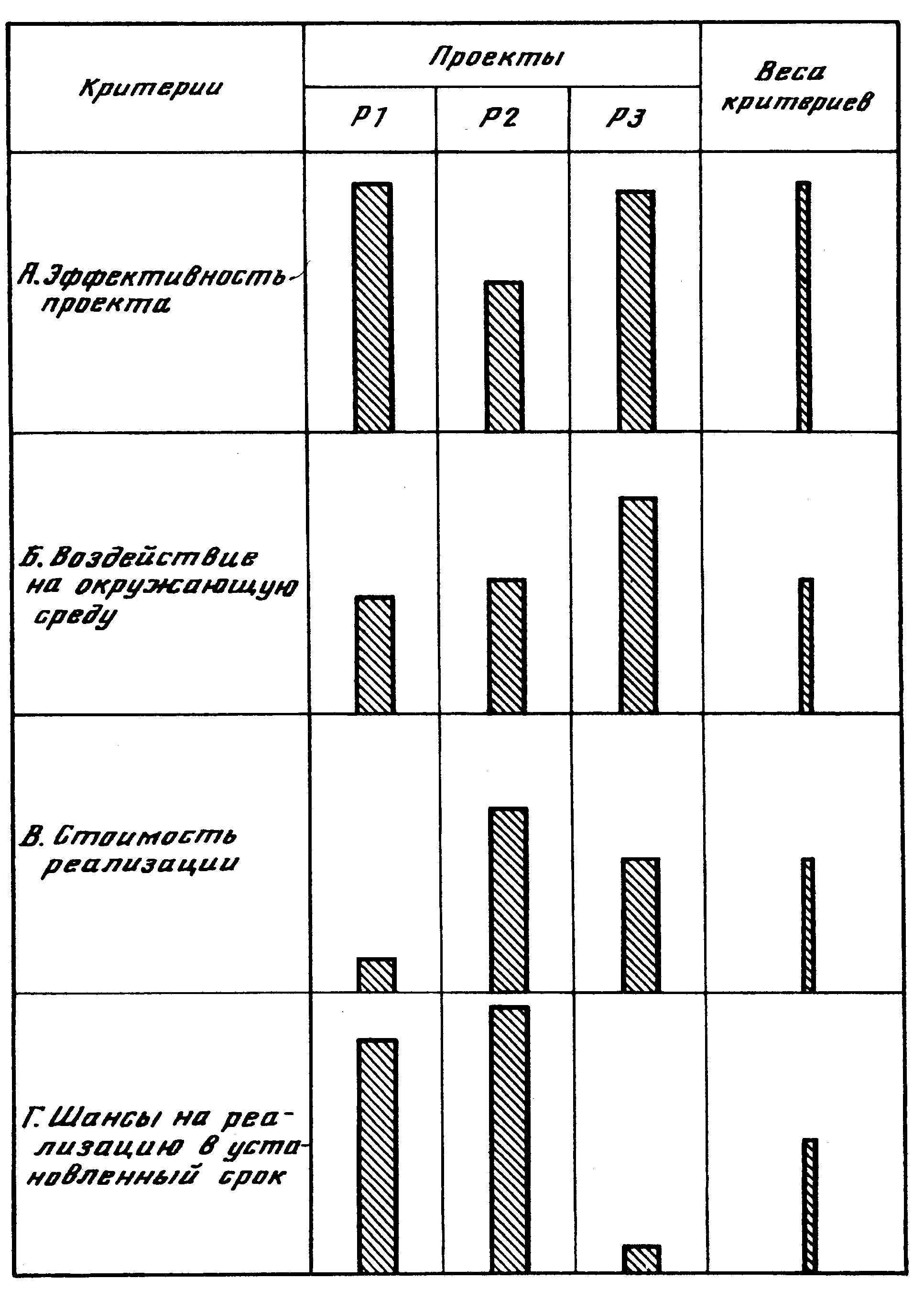
Рисунок 2.3 – Графическое представление оценок проектов при подходе КАР
Измеряя высоту столбиков на рисунке 2.3, получим численные значения оценок и весов критериев, представленные в таблице 2.6.
Таблица 2.6 – Численное представление оценок проектов при подходе КАР
| Критерии | Проекты | Веса критериев | ||
| Р 1 | Р 2 | Р 3 | ||
| А | 0,4 | |||
| Б | 0,2 | |||
| В | 0,2 | |||
| Г | 0,2 |
Далее применяем формулу взвешенных сумм оценок критериев:

где Uj- полезность проекта j, j = 1, 2, 3; Wi – вес критерия i, i = 1,... 4; Х ij - оценка проекта у по критерию i; N – количество критериев.
Используя эту формулу, получим: U 1 = 62,8; U 2 = 63,8; U 3 = 63,6.
Из анализа следует, что полезности проектов Р2 и Р3 мало различаются, но Р2 немного лучше и должен быть выбран конкурсной комиссией.
Приведем теперь способ описания и решения этого гипотетического примера на основе подхода ВАР. Прежде всего, в качестве средства измерения оценок проекта по критериям используются порядковые шкалы с вербальными оценками, приведенные ниже.
А. Эффективность проекта.
1. Полностью удовлетворяет требованиям.
2. Удовлетворяет основным требованиям.
3. Не удовлетворяет основным требованиям.
Б. Воздействие на окружающую среду.
1. Нет заметного отрицательного воздействия.
2. Сравнительно небольшое и допустимое воздействие.
3. Заметное отрицательное воздействие.
В. Стоимость реализации проекта.
1. Не превышает реальные возможности финансирования.
2. Незначительно превышает возможные расходы.
3. Проект заметно дороже, чем первоначально ожидалось.
Г. Шансы реализации в срок.
1. Хорошие.
2. Средние.
3. Небольшие.
Приведенные описания представляют собой язык, принятый ЛПР и экспертами. В табл. 2.7 представлены оценки проектов.
Таблица 2.7 – Оценки проектов при подходе ВАР
| Критерии | Проекты | ||
| П1 | П2 | П3 | |
| А | А1 | А2 | А1 |
| Б | Б2 | Б2 | Б1 |
| В | В3 | В2 | В2 |
| Г | Г2 | Г1 | Г3 |
Поясним таблицу. Запись А1 в клетке на пересечении строки матрицы "Критерий А" (эффективность проекта) и столбца П1 (проект №1) – это значит, что проект №1 по критерию эффективности полностью удовлетворяет требованиям. И так по всем клеткам матрицы.
При подходе ВАР информация ЛПР выявляется поэтапно и проекты сопоставляются попарно. При обсуждении проблемы уточняется, что небольшое воздействие на окружающую среду допустимо. При сопоставлении Р 1 и Р 2, задача сводится к сравнению пониженной эффективности проекта с существенно большей стоимостью. Пусть ЛПР выбирает Р 2.
При сопоставлении проектов Р 2 и Р 3 сравнивается пониженная эффективность с значительной задержкой реализации проекта. Предположим, что, будучи осторожным, ЛПР (конкурсная комиссия) выбирает Р 2.
Итак, получен тот же результат, но процесс решения был совершенно иной. В вербальном анализе мы использовали парные сравнения как в МАИ, но обошлись вообще без математических расчетов, даже таких простых, как в методе взвешенной суммы. Разработано немало методов вербального анализа решений [Ларичев, Мошкович].
Методы количественного анализа решений широко известны и применяются при решении самых разных задач. В то же время результаты психологических исследований убедительно демонстрируют возможности и ограничения системы переработки информации человеком. Поэтому заслуживают внимания методы вербального анализа решений. Многочисленные практические применения показали, что нет универсальных методов и метод должен соответствовать особенностям решаемой задачи.
Контрольные вопросы
1) Провести сравнение количественного и вербального анализа решений.
2) Основные идеи и особенности вербального анализа решений.
3) Сравнить процедуры измерений (оценок) в количественном и вербальном анализе решений.
4) Придумать пример задачи выбора для вербального анализа решений.
5) Построить систему критериев и оценок для вербального анализа решений.
6) Построить и объяснить матрицу вербального анализа решений.
7) Провести (показать на примере) сравнительный анализ альтернатив вербальной компенсацией.
8) Провести сравнение количественного и вербального подходов к анализу решений.
9) Графическое представление оценок в количественном и вербальном анализе решений.
10) Придумать и решить вербальным методом задачу выбора (2-3 альтернативы, 2-3 критерия, 3 уровня шкалы оценок).
2.4. Прикладной системный анализ
Из всех видов информационных процессов: передача, получение, хранение, обработка, анализ информации нам в нашем курсе, конечно же, наиболее интересен анализ. В этом разделе курса рассматриваются вопросы применения современных информационных технологий в прикладном системном анализе.
Вспомним, что термин «прикладной системный анализ» (сам системный анализ – прикладная наука) относится к системному анализу с использованием компьютеров и специального программного обеспечения.
Прикладной системный анализ сложных проблем на современном уровне невозможен без информационно-аналитической системы (ИАС) особого типа. Это - система поддержки принятия решений (СППР), использующая передовые информационные технологии. К таким технологиям сегодня следует отнести в первую очередь: хранилища данных (Data Warehouse), оперативный анализ данных (OLAP-технологии) [Барсегян и др.]) интеллектуальный анализ данных (Data Mining). [Дюк и Самойленко, Барсегян и др.].
При разработке таких систем используются СASE-технологии [Марка и Мак-Гоуэн], такие, как SADT (при структурном подходе к проектированию систем и программного обеспечения) и «унифицированный язык моделирования» UML (при объектно-ориентированном подходе)..
Технологии Data Mining («разработка данных») служат для обнаружения закономерностей в данных, взаимосвязей между данными, в общем – для интеллектуального анализа больших массивов данных [Дюк и Самойленко, Барсегян и др.]. Многокритериальные методы (часть 2) и технологии Data Mining - это основные современные инструменты прикладного системного анализа.
Эти технологии представляют собой «оболочку» СППР, «ядром» же являются методы системного анализа, в том числе – рассмотренные в предыдущем разделе. Любая СППР, независимо от методов и технологий, должна обеспечивать возможность оперативного диалога с исследователем (экспертом, аналитиком-консультантом или лицом, принимающим решение). То есть она должна быть интерактивной, или как говорили в прошлом веке, человеко-машинной.
Новые термины:
CASE –Computer Aided System/Software Engineering,
OLAP – On-Line Analytical Processing,
SADT – Structured Analysis and Design Technique,
UML – Unified Modeling Language.
2.4.1. Информационно-аналитические системы и системы поддержки решений
Виды систем поддержки принятия решений
Основное требование к СППР - возможность не только оперативной (онлайновой) обработки накопленных данных, но и проведение аналитической обработки этих данных. То есть они должны обеспечить оперативное проведение системных исследований, работая с большими объёмами данных. Появление таких систем обусловлено достижениями в области технологий получения, хранения и распределенной обработки больших массивов информации.
СППР можно разделить на две группы:
- оперативные, предназначенные для немедленного реагирования на текущую ситуацию;
- стратегические, предназначенные для анализа большого количества информации из разных источников с привлечением знаний (методик расчётов, многокритериального и статистического анализа…), экспертных систем, аккумулирующих опыт решения проблем.
СППР первого типа по сути представляют собой генераторы отчетов, построенные на основании данных из специализированной базы данных (БД), в идеале адекватно отражающей в режиме реального времени все аспекты производственного цикла предприятия или работы организации. Для такой информационно-аналитической системы характерны следующие основные черты:
- отчеты, как правило, базируются на стандартных для организации запросах;
- система представляет отчеты в максимально удобном виде, включающем, наряду с таблицами, деловую графику, мультимедийные возможности и т. п.;
- как правило, эти системы ориентированы на конкретную сферу, например финансы, маркетинг, управление ресурсами, документооборот.
Чаще всего результаты работы этой ИАС доступны лишь тем подразделениям, в которых первичная информация собирается. Схема использования данных в таких системах следующая:
| «Специализированная БД -> Средство Анализа -> Отчёт» | (3.1) |
Развитие СППР второго типа, работающих с большими массивам информации, связано с появлением ряда новых концепций хранения и анализа корпоративных данных:
- хранилища данных (ХД, Data Warehouse) [Архипенков и др.];
- оперативная аналитическая обработка (On-Line Analytical Processing, OLAP) [Дюк и Самойленко, Барсегян и др.];
- интеллектуальный анализ данных -(Data Mining) [Дюк и Самойленко, Барсегян и др.].
В схеме (3.1) добавилось новое звено:
| «БД-> Хранилище Данных <-> Средство Анализа ->Аналитик-> Отчёт» | (3.2) |
Хранилища данных
Хранилища данных (Data Warehouse, информационные хранилища, склады данных) определяют как предметно ориентированные, интегрированные, неизменчивые, поддерживающие хронологию наборы данных, организованные для целей поддержки управления,обеспечивающего аналитиков достоверной информацией, необходимой для оперативного анализа и принятия решений.
Наличие ХД в схеме (3.2) вызвано появлением нерегламентированных запросов аналитиков, ориентированных на обработку не только количественных данных, а и важной информации, хранящейся в виде текстов (обзоры, статьи, нормативные акты, стандарты, приказы и т.п.).
Основные требования к ХД сводятся к следующему:
- поддержка высокой скорости получения данных из хранилища;
- поддержка внутренней непротиворечивости данных;
- возможность получения и сравнения так называемых срезов данных;
- наличие удобных утилит просмотра данных в хранилище;
- полнота и достоверность хранимых данных;
- поддержка качественного процесса пополнения данных.
Хранилищам данных присущи следующие свойства.
1 Предметная ориентация. В традиционной схеме реализации информационной системы источником данных для средств анализа являются общие БД, а сами данные ориентированы на обработку и функциональность систем сбора информации. В хранилищах данных данные ориентированы на решение задач системного анализа проблем. Как правило – в конкретной предметной области. Предметная ориентация является фундаментальным отличием БД от ХД. Именно это свойство позволяет конечному пользователю работать с данными, охватывающими предмет исследования в целом. Разные приложения в ХД могут описывать одну и ту же предметную область с разных точек зрения, поскольку решение, принятое на основе данных, отражающих только одну сторону вопроса, могут быть неэффективными, а то и неверными.
Предметная ориентация позволяет существенно ускорить доступ к данным за счет предварительной структуризации данных. Предметная ориентация позволяет также хранить в ХД только те данные, которые необходимы для средств анализа.
|
|
|
|
|
Дата добавления: 2014-11-18; Просмотров: 844; Нарушение авторских прав?; Мы поможем в написании вашей работы!