КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Чистый бинарный поиск
|
|
|
|
Поиск данного вида представляет собой обобщение двоичного поиска. Сформулируем задачу чистого бинарного поиска следующим образом.
Имеется таблица из N записей и задан некоторый аргумент поиска, причем заранее известно, что в таблице существует запись с ключом, равным аргументу поиска. Каждая запись таблицы имеет известную вероятность выбора pi и выполняется условие нормировки 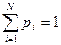 . Поиск осуществляется следующим образом. На каждом шаге выбирается некоторое подмножество записей и выясняется, принадлежит или нет искомая запись выделенному подмножеству. Необходимо построить алгоритм, состоящий из подобных шагов и решающий любую задачу поиска при минимуме среднего числа сравнений. Каждое сравнение при этом делит текущее подмножество непроверенных записей на два других подмножества, одно из которых будет проверяться на данном шаге, а другое – нет.
. Поиск осуществляется следующим образом. На каждом шаге выбирается некоторое подмножество записей и выясняется, принадлежит или нет искомая запись выделенному подмножеству. Необходимо построить алгоритм, состоящий из подобных шагов и решающий любую задачу поиска при минимуме среднего числа сравнений. Каждое сравнение при этом делит текущее подмножество непроверенных записей на два других подмножества, одно из которых будет проверяться на данном шаге, а другое – нет.
Для построения такого алгоритма предположим, что записи упорядочены по возрастанию значений pi и разобьем каждое из множеств непроверенных записей посередине (если число записей в множестве нечетно, то для определенности будем относить серединную запись к подмножеству с меньшими значениями pi). Пример такого разбиения приведен на рис. 2.8.

Рис.2.8. Пример чистого бинарного поиска
Для приведенного примера на первом шаге алгоритма выясняется, «равен ли аргумент поиска пяти или больше», т.е. производится первое сравнение. Пусть ответом на поставленный вопрос будет «нет», тогда следующим вопросом (второе сравнение) будет: «тройка или четверка?» и т.д.
Прямой подсчет среднего числа сравнений для рассмотренного примера дает: C10’=4∙(1/55 + 2/55) + 3∙(3/55 + 4/55 + 5/55) + 4∙(6/55 + 7/55) + 3∙(8/55 + 9/55 + 10/55) = 3,291.
Рассмотренная задача соответствует удачному поиску. Однако, если сравнить этот алгоритм с алгоритмом двоичного поиска, то легко заметить, что его поведение в точности соответствует случаю неудачного двоичного поиска.
Сравнивая задачу чистого бинарного поиска с рассмотренной в разделе 1 задачей экономного кодирования, легко убедиться, что они идентичны. Дерево поиска соответствует при этом бинарному кодовому дереву. Следовательно, для улучшения алгоритма чистого бинарного поиска можно воспользоваться процедурами экономного кодирования (Шеннона-Фано или Хафмана). Так, применение этих процедур к рассматриваемому примеру обеспечивает среднее число сравнений, равное 3,145. При этом, ввиду оптимальности процедуры Хафмана, это число не может быть меньше.
|
|
|
|
|
Дата добавления: 2014-11-20; Просмотров: 495; Нарушение авторских прав?; Мы поможем в написании вашей работы!