КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Накопление и коагулирование данных. 2 страница
|
|
|
|
Под предметной областью понимают один или несколько объектов управления (или определенные их части), информация которых моделируется с помощью БД и используется для решения различных функциональных задач.
Система управления базами данных (СУБД) — совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями. В ней можно выделить:
- ядро СУБД, которое обеспечивает организацию ввода, обработки и хранения данных,
- компоненты, которые обеспечивают отладку системы, средства тестирования,
- утилиты, которые обеспечивают выполнение вспомогательных функций (например, ведение журнала статистики работы системы и др.).
Очень важной задачей СУБД является обеспечение независимости данных. Практически одна и одна и та же СУБД может быть использована для ведения абсолютно разных файлов, которые используются для решения разноплановых, не связанных между собою задач управления. Все функции СУБД можно объединить в такие группы:
1. Управление данными. Задачами управления данных является подготовка данных и их контроль, внесение данных в базу, структуризация данных, обеспечение целостности, секретности данных.
2. Доступ к данным. Поиск и селекция данных, преобразование данных в форму, удобную для дальнейшего использования.
3. Организация и ведение связи с пользователем. Ведение диалога, выдача диагностических сообщений об ошибках в работе по БД и т.д.
Для обработки запросов к БД разрабатывают программы, которые составляют прикладное программное обеспечение. Программы, с помощью которых пользователи работают с базой данных, называются приложениями. В общем случае с одной базой данных могут работать множество различных приложений. Например, если база данных моделирует некоторое предприятие, то для работы с ней может быть создано приложение, которое обслуживает подсистему учета кадров, другое приложение может быть посвящено работе подсистемы расчета заработной платы сотрудников, третье приложение работает как подсистема складского учета, четвертое приложение посвящено планированию производственного процесса. При рассмотрении приложений, работающих с одной базой данных, предполагается, что они могут работать параллельно и независимо друг от друга, и именно СУБД призвана обеспечить работу множества приложений с единой базой данных таким образом, чтобы каждое из них выполнялось корректно, но учитывало все изменения в базе данных, вносимые другими приложениями.
Языковые средства банка данных
Языковые средства СУБД, необходимые для описания данных, организации общения и выполнения процедур поиска и различных преобразований данных. Классификация языковых средств БнД, показанная на рис. 12.1, разработана американским комитетом CODASYL по проектированию и созданию БД.
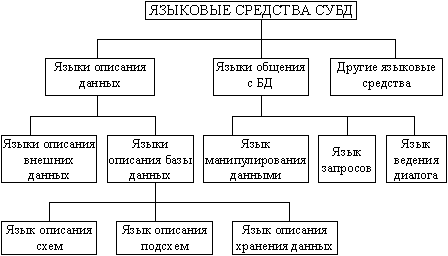
Рис. 12.1. Схема классификации языковых средств БнД.
Схема имеет общий характер и ориентирована на различные СУБД. Однако не каждая СУБД, которая сейчас используется на практике и распространена на рынке программных продуктов, имеет весь набор указанных языковых средств.
Язык описания данных (DDL - Data Definition Language), предназначен для описания данных на разных уровнях абстракции: внешнем, логическом и внутреннем. Исходя из предложений CODASYL, языки описания данных на логическом (концептуальном) и внутреннем уровнях независимые и разные. Однако в большинстве промышленных СУБД языки не делится на два отдельных языка описания логической и физической организации данных, а существует единый язык, которая еще называется языком описания схем. В известных и широко используемых на практике СУБД семьи dBASE применяется единый язык описания данных. Он предназначен для представления данных на логическом и физическом уровнях. Этот язык имеет свой синтаксис: например, имя файла не должно превышать восьми символов, а имя поля - десяти; при этом каждое имя может начинаться с буквы, поля календарной даты обозначаются символом D (DATA), символьные поля — С (CHARACTER), числовые — N (NUMERIC), логические — L (LOGICAL), примечаний — М (MEMO).
Описание всех имен, типов и размеров полей сохраняется в памяти вместе с данными; эти структуры в случае необходимости можно просмотреть и исправить. Если логический и физический уровни отделены, то в состав СУБД может входить язык описания сохранения данных. В некоторых СУБД используется еще язык описания подсхем, который нужен для описания части БД, которая отражает информационные потребности отдельного пользователя или прикладной программы. В составе СУБД типа dBASE такой язык не используется.
Язык описания данных на внешнем уровне используется для описания требований пользователей и прикладных программ и создания инфологической модели БД. Этот язык не имеет ничего общего с языками программирования. Так, языковым средством, которое используются для инфологического моделирования, является обычный естественный язык или его подмножество, а также язык графов и матриц.
Язык манипулирования данными (DML - Data Manipulation Language) используется для обработки данных, их преобразований и написания программ. DML может быть базовым или автономным.
Базовый язык DML — это один из традиционных языков программирования (BASIC, C, FORTRAN и др.). Системы, которые используют базовый язык, называют открытыми. Использование базовых языков как языков описания данных сужает круг лиц, которые могут непосредственно обращаться к БД, поскольку для этого нужно знать язык программирования. В таких случаях для упрощения общения конечных пользователей с БД предполагается язык ведения диалога, который значительно проще для овладения, чем язык программирования.
Автономный язык DML — это собственный язык СУБД, который дает возможность выполнять различные операции с данными. Системы с собственным языком называют закрытыми.
В современных СУБД для упрощения процедур поиска данных в БД предусмотрен язык запросов. Наиболее распространенными языками запросов являются SQL и QBE.
Язык запросов SQL (Structured Query Language - структурированный язык запросов) был создан фирмой IBM в рамках работы над проектом построения системы управления реляционными базами данных в начале 70-х годов. Американский национальный институт стандартов (ANSI) положил этот язык в основу стандарта языков реляционных баз данных, принятого Международной организацией стандартов (ISO). Ядром существующего стандарта SQL-86, которые часто называют SQL-2 или SQL-92, являются функции, реализованные практически во всех известных коммерческих реализациях языка, а полный стандарт вмещает такие усовершенствования, которые некоторые разработчики будут должны еще реализовать.
Кроме стандарта SQL-86 существует коммерческий стандарт языка SQL, разработанный консорциумом производителей баз данных SQL Access Group. Эта группа создала такой вариант языка, который используется большинством систем и дает возможность им «понимать» одна другую.
Был разработан стандартный интерфейс языка CLI (Common Language Interface) для всех основных вариантов языка SQL. Этот интерфейс, формализованный фирмой Microsoft, получил название ODBC (Open DataBase Connectivity — открытый доступ к данным). ODBC — это интерфейс доступа к данным, которые сохраняются под управлением разных СУБД. ODBC имеет целый набор драйверов, с помощью которых одна СУБД может работать с данными других систем. Архитектура ODBC изображена на рис 12.2.
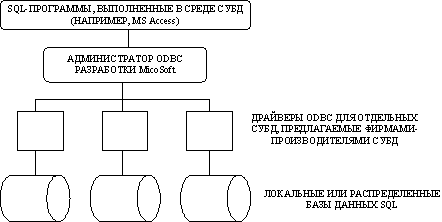
Рис. 12.2. Архитектура ODBC
Язык запросов QBE (Query By Example) — это реализация запросов по образцу в виде таблиц. Для определения запроса к БД пользователь должен заполнить предоставленную системой таблицу QBE и определить в ней критерии поиска и выбора данных.
Пользователи банков данных
Как любой программно-организационно-технический комплекс, банк данных существует во времени и в пространстве. Он имеет определенные стадии своего развития:
1. Проектирование.
2. Реализация.
3. Эксплуатация.
4. Модернизация и развитие.
5. Полная реорганизация.
На каждом этапе своего существования с банком данных связаны разные категории пользователей.
Определим основные категории пользователей и их роль в функционировании банка данных:
§ Конечные пользователи. Это основная категория пользователей, в интересах которых и создается банк данных, В зависимости от особенностей создаваемого банка данных круг его конечных пользователей может существенно различаться. Это могут быть случайные пользователи, обращающиеся к БД время от времени за получением некоторой информации, а могут быть регулярные пользователи. В качестве случайных пользователей могут рассматриваться, например, возможные клиенты вашей фирмы, просматривающие каталог вашей продукции или услуг с обобщенным или подробным описанием того и другого. Регулярными пользователями могут быть ваши сотрудники, работающие со специально разработанными для них программами, которые обеспечивают автоматизацию их деятельности при выполнении своих должностных обязанностей. Например, менеджер, планирующий работу сервисного отдела компьютерной фирмы, имеет в своем распоряжении программу, которая помогает ему планировать и распределять текущие заказы, контролировать ход их выполнения, заказывать на складе необходимые комплектующие для новых заказов. Главный принцип состоит в том, что от конечных пользователей не должно требоваться каких-либо специальных знании в области вычислительной техники и языковых средств.
§ Администраторы банка данных. Это группа пользователей, которая на начальной стадии разработки банка данных отвечает за его оптимальную организацию с точки зрения одновременной работы множества конечных пользователей, на стадии эксплуатации отвечает за корректность работы данного банка информации и многопользовательском режиме. На стадии развития и реорганизации эта группа пользователей отвечает за возможность корректной реорганизации банка без изменения или прекращения его текущей эксплуатации.
§ Разработчики и администраторы приложений. Это группа пользователей, которая функционирует во время проектирования, создания и реорганизации банка данных. Администраторы приложений координируют работу разработчиков при разработке конкретного приложения или группы приложений, объединенных в функциональную подсистему. Разработчики конкретных приложений работают с той частью информации из базы данных, которая требуется для конкретного приложения.
Не в каждом банке данных могут быть выделены все тины пользователей. Мы уже знаем, что при разработке информационных систем с использованием настольных СУБД администратор банка данных, администратор приложении и разработчик часто существовали в одном лице. Однако при построении современных сложных корпоративных баз данных, которые используются для автоматизации всех или большей части бизнес-процессов в крупной фирме или корпорации, могут существовать и группы администраторов приложений, и отделы разработчиков. Наиболее сложные обязанности возложены на группу администратора БД.
Рассмотрим их более подробно. В составе группы администратора БД должны быть:
· системные аналитики;
· проектировщики структур данных и внешнего по отношению к банку данных информационного обеспечения;
· проектировщики технологических процессов обработки данных;
· системные и прикладные программисты:
· операторы и специалисты по техническому обслуживанию.
Если речь идет о коммерческом банке данных, то важную роль здесь играют специалисты по маркетингу.
Основные функции группы администратора БД
1. Анализ предметной области: описание предметной области, выявление ограничений целостности, определение статуса (доступности, секретности) информации, определение потребностей пользователей, определение соответствия «данные - пользователь», определение объемно-временных характеристик обработки данных.
2. Проектирование структуры БД: определение состава и структуры файлов БД и связей между ними, выбор методов упорядочения данных и методов доступа к информации, описание БД на языке описания данных (ЯОД).
3. Задание ограничений целостности при описании структуры БД и процедур обработки БД:
- задание декларативных ограничений целостности, присущих предметной области;
- определение динамических ограничений целостности, присущих предметной области в процессе изменения информации, хранящейся в БД;
- определение ограничений целостности, вызванных структурой БД;
- разработка процедур обеспечения целостности БД при вводе и корректировке данных;
- определение ограничений целостности при параллельной работе пользователей в многопользовательском режиме.
4. Первоначальная загрузка и ведение БД:
- разработка технологии первоначальной загрузки БД, которая будет отличаться от процедуры модификации и дополнения данными при штатном использовании базы данных;
- разработка технологии проверки соответствия введенных данных реальному состоянию предметной области. База данных моделирует реальные объекты некоторой предметной области и взаимосвязи между ними, и на момент начала штатной эксплуатации эта модель должна полностью соответствовать состоянию объектов предметной области на данный момент времени;
- в соответствии с разработанной технологией первоначальной загрузки может понадобиться проектирование системы первоначального ввода данных.
5. Защита данных:
- определение системы паролей, принципов регистрации пользователей, создание групп пользователей, обладающих одинаковыми правами доступа к данным;
- разработка принципов защиты конкретных данных и объектов проектирования;
- разработка специализированных методов кодирования информации при ее циркуляции в локальной и глобальной информационных сетях;
- разработка средств фиксации доступа к данным и попыток нарушения системы зашиты;
- тестирование системы защиты;
- исследование случаев нарушения системы защиты и развитие динамических методов защиты информации в БД.
6. Обеспечение восстановления БД:
- разработка организационных средств архивирования и принципов восстановления БД;
- разработка дополнительных программных средств и технологических процессов восстановления БД после сбоев.
7. Анализ обращений пользователей БД: сбор статистики по характеру запросов, по времени их выполнения, по требуемым выходным документам
8. Анализ эффективности функционирования БД:
- анализ показателей функционирования БД;
- планирование реструктуризации (изменение структуры) БД и реорганизации БнД.
9. Работа с конечными пользователями:
- сбор информации об изменении предметной области;
- сбор информации об оценке работы БД;
- обучение пользователей, консультирование пользователей;
- разработка необходимой методической и учебной документации по работе конечных пользователей.
10. Подготовка и поддержание системных средств:
- анализ существующих на рынке программных средств и анализ возможности и необходимости их использования в рамках БД;
- разработка требуемых организационных и программно-технических мероприятий по развитию БД;
- проверка работоспособности закупаемых программных средств перед подключением их к БД;
- курирование подключения новых программных средств к БД.
11. Организационно-методическая работа по проектированию БД:
- выбор или создание методики проектирования БД;
- определение целей и направления развития системы в целом;
- планирование этапов развития БД;
- разработка общих словарей-справочников проекта БД и концептуальной модели;
- стыковка внешних моделей разрабатываемых приложений;
- курирование подключения нового приложения к действующей БД;
- обеспечение возможности комплексной отладки множества приложений, взаимодействующих с одной БД.
Архитектура базы данных. Физическая и логическая независимость
Терминология в СУБД, да и сами термины «база данных» и «банк данных» частично заимствованы из финансовой деятельности. Это заимствование — не случайно и объясняется тем, что работа с информацией и pa6oтa с денежными массами во многом схожи, поскольку и там и там отсутствует персонификация объекта обработки: две банкноты достоинством в сто рублей столь же неотличимы и взаимозаменяемы, как два одинаковых байта (естественно, за исключением серийных номеров). Вы можете положить деньги на некоторый счет и предоставить возможность вашим родственникам или коллегам использовать их для иных целей. Вы можете поручить банку оплачивать ваши расходы с вашего счета или получить их наличными о другом банке, и это будут уже другие денежные купюры, но их ценность будет эквивалентна той, которую вы имели, когда клали их на ваш счет.
В процессе научных исследований, посвященных тому, как именно должна быть устроена СУБД, предлагались различные способы реализации. Самым жизнеспособным из них оказалась предложенная американским комитетом по стандартизации ANSI (American National Standards Institute) трехуровневая система организации БД, изображенная на рис. 12.3.
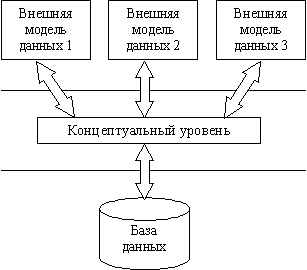
Рис. 12.3. Трехуровневая модель системы управления базой данных, предложенная ANSI
1. Уровень внешних моделей — самый верхний уровень, где каждая модель имеет свое «видение» данных. Этот уровень определяет точку зрения на БД отдельных приложений. Каждое приложение видит и обрабатывает только те данные, которые необходимы именно этому приложению. Например, система распределения работ использует сведения о квалификации сотрудника, но ее не интересуют сведения об окладе, домашнем адресе и телефоне сотрудника, и наоборот, именно эти сведения используются в подсистеме отдела кадров.
2. Концептуальный уровень — центральное управляющее звено, здесь база данных представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной базой данных. Фактически концептуальный уровень отражает обобщенную модель предметной области (объектов реального мира), для которой создавалась база данных. Как любая модель, концептуальная модель отражает только существенные, с точки зрения обработки, особенности объектов реального мира.
3. Физический уровень — собственно данные, расположенные в файлах или в страничных структурах, расположенных на внешних носителях информации.
Эта архитектура позволяет обеспечить логическую (между уровнями 1 и 2) и физическую (между уровнями 2 и 3) независимость при работе с данными. Логическая независимость предполагает возможность изменения одного приложения без корректировки других приложений, работающих с этой же базой данных. Физическая независимость предполагает возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений, работающих с данной базой данных. Это именно то, чего не хватало при использовании файловых систем. Выделение концептуального уровня позволило разработать аппарат централизованного управления базой данных.
Классификация банков данных
Банки данных — это очень сложная система, которую можно классифицировать по целому спектру признаков, касающихся как банка в целом, так и отдельных его компонентов.
По назначению БнД бывают:
- информационно-поисковые;
- специализированные по отдельным областям науки и техники;
- банки данных АСУ для организационно-экономической информации;
- банки данных для систем автоматизации научных исследований и производственных испытаний;
- банки данных для систем автоматизированного проектирования.
По архитектуре поддерживаемой вычислительной среды БнД бывают централизованными (интегрированными) и распределенными.
По виду информации, которая сохраняется, банки делятся на банки данных, банки документов и банки знаний.
По языку общения пользователя с БД различают системы с базовым языком (открытые системы) и с собственным языком (закрытые системы).
В открытых системах языковым средством общения с БД один из языков программирования, например C, Pascal. В таких системах для общения с БД нужен посредник, то есть программист, который владеет избранным языком программирования.
Закрытые системы имеют собственный язык общения. Он, как правило, намного проще, чем язык программирования. Поэтому в таких системах не нужен посредник-программист для общения с БД. Сами пользователи, которые имеют соответствующую подготовку, смогут работать с БД.
Одними из основополагающих в концепции баз данных являются обобщенные категории «данные» и «модель данных».
Понятие «данные» в концепции баз данных — это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы. Примеры данных: Петров Николай Степанович, $30 и т. д. Данные не обладают определенной структурой, данные становятся информацией тогда, когда пользователь задает им определенную структуру, то есть, осознает их смысловое содержание. Поэтому центральным понятием в области баз данных является понятие модели. Не существует однозначного определения этого термина, у разных авторов эта абстракция определяется с некоторыми различиями, но, тем не менее, можно выделить нечто общее в этих определениях-
Модель данных — это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними. На рис. 12.4 представлена классификация моделей данных.
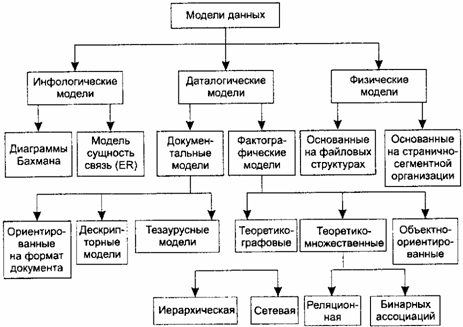
Рис. 12.4. Классификация моделей данных
В соответствии с рассмотренной ранее трехуровневой архитектурой мы сталкиваемся с понятием модели данных по отношению к каждому уровню. И действительно, физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. В настоящий момент в качестве физических моделей используются различные методы размещения данных, основанные на файловых структурах: это организация файлов прямого и последовательного доступа, индексных файлов и инвертированных файлов, файлов, использующих различные методы хеширования, взаимосвязанных файлов. Кроме того, современные СУБД широко используют страничную организацию данных. Физические модели данных, основанные на страничной организации, являются наиболее перспективными.
Наибольший интерес вызывают модели данных, используемые на концептуальном уровне. По отношению к ним внешние модели называются подсхемами и используют те же абстрактные категории, что и концептуальные модели данных.
Кроме трех рассмотренных уровней абстракции при проектировании БД существует еще один уровень, предшествующий им. Модель этого уровня должна выражать информацию о предметной области в виде, независимом от используемой СУБД. Эти модели называются инфологическими, или семантическими, и отражают в естественной и удобной для разработчиков и других пользователей форме информационно-логический уровень абстрагирования, связанный с фиксацией и описанием объектов предметной области, их свойств и их взаимосвязей.
Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения, а даталогические модели уже поддерживаются конкретной СУБД.
Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке.
Модели, основанные на языках разметки документов, связаны, прежде всего, со стандартным общим языком разметки — SGML (Standard Generalized Markup Language), который был утвержден ISO в качестве стандарта еще в 80-х годах. Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тегов (ссылок), их атрибуты и внутреннюю структуру документа. Контроль за правильностью использования тегов осуществляется при помощи специального набора правил, называемых DTD-описаниями. которые используются программой клиента при разборе документа. Для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. С помощью SGML можно описывать структурированные данные, организовывать информацию, содержащуюся в документах, представлять эту информацию в некотором стандартизованном формате. Но ввиду некоторой своей сложности SGML использовался в основном для описания синтаксиса других языков (наиболее известным из которых является HTML), и немногие приложения работали с SGML-документами напрямую.
Гораздо более простой и удобный, чем SGML, язык HTML позволяет определять оформление элементов документа и имеет некий ограниченный набор инструкций — тегов, при помощи которых осуществляется процесс разметки. Инструкции HTML в первую очередь предназначены для управления процессом вывода содержимого документа на экране программы-клиента и определяют этим самым способ представления документа, но не его структуру. В качестве элемента гипертекстовой базы данных, описываемой HTML. используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP. Эта особенность, а также то, что HTML является открытым стандартом, и огромное количество пользователей имеет возможность применять возможности этого языка для оформления своих документов, безусловно, повлияли на рост популярности HTML и сделали его сегодня главным механизмом представления информации в Internet.
Однако HTML сегодня уже не удовлетворяет в полной мере требованиям, предъявляемым современными разработчиками к языкам подобного рода. И ему на смену был предложен новый язык гипертекстовой разметки, мощный, гибкий и, одновременно с этим, удобный язык XML. В чем же заключаются его достоинства?
XML (Extensible Markup Language) — это язык разметки, описывающий целый класс объектов данных, называемых XML-докумснтами. Он используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документов. То есть сам по себе XML не содержит никаких тегов, предназначенных для разметки, он просто определяет порядок их создания.
Тезаурусные модели основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых переводчиках. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям.
Дескрипторные модели — самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор — описатель. Этот дескриптор имел жесткую структуру и описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной БД. Например, для БД, содержащей описание патентов, дескриптор содержал название области, к которой относился патент, номер патента, дату выдачи патента и еще ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных велась исключительно по дескрипторам, то есть по тем параметрам, которые характеризовали патент, а не по самому тексту патента.
5.3. Проектирование баз данных
Этапы проектирования баз данных
Создание и внедрение в практику современных информационных систем автоматизированных баз данных выдвигает новые задачи проектирования, которые невозможно решать традиционными приемами и методами. Большое внимание необходимо уделять вопросам проектирования баз данных. От того, насколько успешно будет спроектирована база данных, зависит эффективность функционирования системы в целом, ее жизнеспособность и возможность расширения и дальнейшего развития. Поэтому вопрос проектирования баз данных выделяют как отдельное, самостоятельное направление работ при разработке информационных систем.
Проектирование баз данных — это итерационный, многоэтапный процесс принятия обоснованных решений в процессе анализа информационной модели предметной области, требований к данным со стороны прикладных программистов и пользователей, синтеза логических и физических структур данных, анализа и обоснования выбора программных и аппаратных средств. Этапы проектирования баз данных связаны с многоуровневой организацией данных. Рассматривая вопрос проектирования баз данных, будем придерживаться такого многоуровневого представления данных: внешнего, инфологического, логического (даталогического) и внутреннего.
Такое представление уровней данных не единственное. Существуют и другие варианты многоуровневого представления данных. Так, в соответствии с предложениями исследовательской группы по системам управления данными Американского национального института стандартов ANSI/X3/SPARC, а также CODASYL (Conference on Data Systems Languages), как правило, выделяется три уровня представления данных:
внешний уровень (с точки зрения конечного пользователя и прикладного программиста),
концептуальный уровень (с точки зрения СУБД),
внутренний уровень (с точки зрения системного программиста).
В соответствии с этой концепцией внешний уровень это часть (подмножество) концептуальной модели, необходимая для реализации какого-либо запроса или прикладной программы. То есть, если концептуальная модель выступает как схема, поддерживаемая конкретной СУБД, то внешний уровень — это некоторая совокупность подсхем, необходимых для реализации конкретной прикладной программы или запроса пользователя.
|
|
|
|
|
Дата добавления: 2014-11-20; Просмотров: 608; Нарушение авторских прав?; Мы поможем в написании вашей работы!