КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Михаил Юрьевич Катаргин
|
|
|
|
Анализ трудоемкости операций над рассеянной таблицей
Рассеянные таблицы (Hash)
Таблицы с прямым доступом
Пусть в таблице из m записей все записи имеют разные значения ключа k1, k2, …,km и таблица отображается в вектор a1, a2, ..an, где n³m. Если определена функция f(k) такая, что для любого значения ki (i=1…m) 1 £ f(ki) £ n, причем f(ki) ¹ f(kj) при i ¹ j, то табличная запись с ключом k взаимно однозначно отображается в элемент af(k). Функцию f(k) называют функцией расстановки. Доступ к записи по ключу k производится непосредственно путем вычисления f(k). Таблица, для которой существует и известна функция расстановки, называют таблицей с прямым доступом. Подбор функции расстановки, обеспечивающей взаимно однозначное преобразование ключа записи в адрес хранения, на практике можно решить только для постоянных таблиц с заранее известным набором значений ключа.
Таблицы с прямым доступом имеют очень ограниченное применение в первую очередь из-за ограничения f(ki)¹f(kj) при i ¹ j, то есть требования взаимной однозначности преобразования ключа в адрес. Можно получить более гибкий метод, если отказаться от этого ограничения. Тогда сделается возможной ситуация f(ki)=f(kj) при i¹j, то есть более чем одна запись претендует на один и тот же адрес хранения. В этом случае ключи называют синонимами, а событие – коллизией. Чтобы таких ситуаций было меньше, функцию расстановки подбирают из соображений случайного и возможно более равномерного распределения ключей по памяти, отведенной для таблицы. Таблицы, построенные по такому принципу, называют рассеянными, рандомизированными или хешированными (hash) таблицами. Метод вычисления адреса называют хешированием. Английский глагол to hash означает нарезать, искрошить, сделать месиво. Функцию расстановки h(k) называют хеш-функцией и стремятся сделать такой, чтобы она равномерно рассеивала ключи по памяти.
Будем считать, что хеш-функция имеет не более m различных значений 0£h(k)<m. Хорошая хеш-функция должна удовлетворять двум требованиям: ее вычисление должно быть достаточно быстрым, а число коллизий минимальным. Как правило, хеш-функции используют ту же идею, что и линейные конгруэнтные генераторы псевдослучайных чисел, а именно:
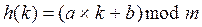 ,
,
где a и b – тщательно подобранные константы, m – число позиций в таблице. Возможное переполнение при выполнении операций умножения и сложения игнорируется.
Для разрешения коллизий существует два метода: метод цепочек переполнения и метод открытой адресации.
В методе цепочек переполнения поддерживается m линейных списков (можно деревьев) – по одному на каждый возможный хеш-адрес. После хеширования алгоритм получает адрес головы списка и производит в нем поиск простым перебором, если требуется поиск, или вставляет новую запись вслед за головой, если требуется вставка. Если имеется n ключей и m списков, то средняя длина списка m/n. На рис. 53 изображен массив списков для метода 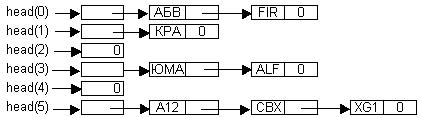
цепочек переполнения.
Рис.53 Метод цепочек переполнения
Метод открытой адресации состоит в том, чтобы, отправляясь от вычисленного хеш-адреса, просматривать записи до тех пор, пока не будет найден искомый ключ при поиске или свободная позиция при вставке. Если в процессе поиска алгоритм встретит свободную позицию, то это означает, что искомого ключа в таблице нет, так как механизм вставки такой, что запись вставляется в первую найденную свободную позицию. Простейшая схема открытой адресации, известная как линейное опробование, последовательно перебирает записи, отправляясь от хеш-адреса, и использует циклическую последовательность проб:
h(k), h(k)+1, h(k)+2,…,m-2, m-1, 0, 1, 2, …,h(k)-1
Эксперименты с линейным опробованием показали, что метод хорошо работает, пока таблица не слишком заполнена. Для линейного опробования характерно явление "скучивания" - скопление записей группами. Действительно, если некоторый отрезок позиций таблицы полностью занят записями, то вероятность хеш-адреса новой записи попасть в этот отрезок и тем самым увеличить его, тем больше, чем больше длина отрезка. Таким образом, куча имеет склонность к экспоненциальному росту. Изменение шага просмотра с единицы на некоторую константу С не решает проблемы – куча все равно образуется, хотя элементы кучи и не являются физическими соседями в памяти.
В методе вторичного хеширования константа С зависит от ключа k. Алгоритм вычисляет две хеш-функции: h1(k) и h2(k). Как и прежде, h1(k) это хеш-адрес, а h2(k) – это шаг опробования. Значение h2(k) должно лежать в диапазоне от 1 до m-1 и быть взаимно простым с m для того, чтобы с этим шагом можно было пройти все позиции таблицы.
Удаление из рассеянной таблицы несет с собой некоторые проблемы. Просто удалить запись, пометив занимаемую ей позицию как свободную, нельзя, так как при этом нарушится работа алгоритмов вставки и поиска. Действительно, при удалении записи с хеш-адресом L одновременно сделаются недоступными все синонимы, которые были включены в таблицу позднее. Можно выйти из положения, имея три типа позиций: свободные, занятые и удаленные. При поиске удаленные позиции трактуются как занятые, а при вставке как свободные. Однако это не решает проблему полностью, так как после длинной серии вставок и удалений в таблице не останется свободных позиций – останутся только занятые и удаленные. В этом случае любой неудачный поиск (поиск ключа, которого нет в таблице) будет приводить к полному перебору всей таблицы. Единственное известное решение этой проблемы заключается в рехешировании, то есть построении таблицы заново. После рехеширования в таблице останутся только свободные и занятые позиции.
Пусть для хранения таблицы отведено m позиций, и в таблице имеется n записей, тогда a= n/m £ 1 – коэффициент загруженности памяти. Вероятность того, что хеш-адрес попадет в занятую позицию равна a, а в свободную 1-a. При вставке нам удастся найти место для новой записи:
- с 1-й попытки с вероятностью 1-a,
- со 2-й попытки – с вероятностью a(1-a) (первая попытка неудачная, вторая успешная),
- c 3-й попытки – с вероятностью a2(1-a) (две первых неудачны, третья успешна) и т.д.
Математическое ожидание числа попыток N при вставке:
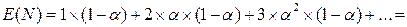
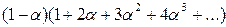 (13)
(13)
Выражение 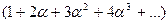 является производной по a от суммы геометрической прогрессии
является производной по a от суммы геометрической прогрессии 
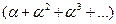 , которая может быть вычислена по формуле (a+a2+a3+…)=a / (1-a) (14),
, которая может быть вычислена по формуле (a+a2+a3+…)=a / (1-a) (14),
Подставляя производную правой части (14) в (13), получим:
E(N)=1 / (1-a) (15)
Для определения среднего числа проб при поиске заметим, что запись будет найдена в точности за столько же проб, сколько потребовалось при ее вставке. Каждая запись вставляется при своем значении a, так, например, при вставке первой записи a=0. Усредняя (14) по a, получим:
 (16)
(16)
Таблица, приведенная ниже, дает представление о среднем числе проб при вставке и поиске.
| a | N(a) | R(a) |
| 0,20 | 1,25 | 1,12 |
| 0,50 | 2,00 | 1,39 |
| 0,80 | 5,00 | 2,01 |
| 0,90 | 10,00 | 2,56 |
| 0,95 | 20,00 | 3,15 |
| 0,99 | 100,00 | 4,65 |
Как видно из таблицы, не следует рассчитывать на полное использование памяти. Для динамичных таблиц коэффициент загрузки памяти не должен превышать 0,7 – 0,8.
Контрольные вопросы
1) В чем заключается основное отличие рассеянных таблиц от таблиц с прямым доступом?
2) Каким требованиям должны удовлетворять первичная и вторичная хеш-функции?
3) Какие методы разрешения коллизий в рассеянных таблицах вы знаете?
4) В чем заключается явление скучивания?
5) Опишите алгоритмы поиска, вставки и удаления для метода открытой адресации.
6) Дайте оценку трудоёмкости операций поиска и вставки для рассеянной таблицы.
Литература
1. Вирт Н. Алгоритмы и структуры данных. СПб Невский диалект 2001г. 352 с.
2. Ахо А., Хопкрофт Д, Ульман Дж.., Структуры данных и алгоритмы СПб Издательский дом "Вильямc", 2000 г., 384 с.
3. Мейн М. Савитч У. Структуры данных и другие объекты в C++, 2-е издание. СПб Издательский дом "Вильямс" 2002г. 832 с.
4. Гудрич М.Т., Тамассия Р. Структуры данных и алгоритмы в Java. СПб Издательский дом "Вильямс" 671 с.
5. Бакнелл Дж. Фундаментальные алгоритмы и структуры данных в Delphi. М. ДиаСофт. 560 с.
|
|
|
|
|
Дата добавления: 2014-12-08; Просмотров: 740; Нарушение авторских прав?; Мы поможем в написании вашей работы!