КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Уровни представления и независимости данных
|
|
|
|
Под моделью данных понимается совокупность данных и их взаимосвязей. На рисунке 1.3.3.1 представлена классификация моделей данных (взято из [19]).
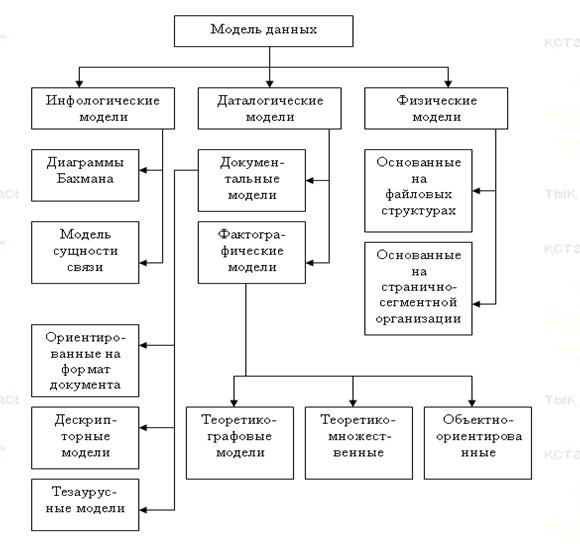
Рисунок 1.3.3.1 - Классификация моделей данных
Рассмотрим основные модели.
Инфологическая (концептуальная) модель определяет тип модели представления данных в целом для всей базы.
При определении типов моделей используется математическое понятие ориентированного связанного графа: множество точек (узлов) и направленных связей (дуг), соединяющих попарно все точки. Точки (узлы) представляют собой объекты, а дуги ‑ линии связей между объектами.
Пример графа: схема железнодорожных дорог.
Эти модели отражают в естественной и удобной для разработчиков и пользователей форме уровень абстрагирования, связанный с фиксацией и описанием объектов предметной области, их свойств и их взаимосвязей.
Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения.
Существуют следующие типы моделей данных: иерархическая, сетевая, реляционная, постреляционная, многомерная и объектно‑ориентированная.
Даталогическая (логическая) модель - это совокупность объектов и их взаимосвязей в терминах конкретной СУБД.
Физическая (внутренняя) модель - это представление данных на внешнем носителе.
Подмодель(подсхема, внешняя схема) ‑ это представление о базе с точки зрения пользователя таблицы. Эта модель упрощает для пользователя представление о базе (не нужно знать всю базу, а только ее часть, используемую пользователем) и защищает базу данных от несанкционированного использования данных за пределами внешней модели.
Такое многоуровневое представление упрощает реализацию, управление и использование таблицы. Проектирование и управление базой ведется на каждом уровне представления.
Документальные модели данных - соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке.
Для описания таких моделей разработаны и применятся следующие языки разметки.
SGML (Standart Generalised MarkupLanguage), который был утвержден ISO в качестве стандарта еще в 80-х годах. Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тегов (ссылок), их атрибуты и внутреннюю структуру документа. Контроль за правильностью использования тегов осуществляется при помощи специального набора правил, называемых DTD-описаниями, которые используются программой клиента при разборе документа. Для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. С помощью SGML можно описывать структурированные данные, организовывать информацию, содержащуюся в документах, представлять эту информацию в некотором стандартизованном формате. Но ввиду некоторой своей сложности SGML использовался в основном для описания синтаксиса других языков (наиболее известным из которых является HTML.
HTML - позволяет определять оформление элементов документа и имеет некий ограниченный набор инструкций – тегов, при помощи которых осуществляется процесс разметки. Инструкции HTML в первую очередь предназначены для управления процессом вывода содержимого документа на экране программы-клиента и определяют этим самым способ представления документа, но не его структуру. В качестве элемента гипертекстовой базы данных, описываемой HTML, используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP.
XML (Extensible Markup Language) - описывающий целый класс объектов данных, называемых XML-документами. Он используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документов. То есть сам по себе XML не содержит никаких тегов, предназначенных для разметки, он просто определяет порядок их создания.
Тезаурусные модели - это модели, которые основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых переводчиках. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям.
Дескрипторные модели - самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор - описатель. Этот дескриптор имел жесткую структуру и описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной БД. Например, для БД, содержащей описание товара, дескриптор содержал наименование товара, поставщика, группы товара, Обработка информации в таких базах данных велась исключительно по дескрипторам, то есть по тем параметрам, которые характеризовали товар, а не по самому тексту описания товара.
Независимость данных ‑ это возможность использования БД без знания внутреннего представления данных и отсутствие необходимости корректировать программы при изменении логической (первый уровень независимости) и физической (второй уровень) моделей базы данных.
Причины стремления к независимости данных: отсутствие перепрограммирования в случае изменения структуры БД, упрощение работы пользователя, защита от несанкционированного доступа.
Классификация моделей данных.
|
|
|
|
|
Дата добавления: 2014-12-10; Просмотров: 905; Нарушение авторских прав?; Мы поможем в написании вашей работы!