КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Код Хаффмана
|
|
|
|
Унарное кодирование
Один из очевидных способов сжатия информации, в особенности текстовой, основывается на том, что вероятность использования в тексте разных символов сильно различна. В частности, в русском языке чаще всего используются буквы “о”, “а”, редко-“ъ”,”щ” и т.д. Поэтому, предлагается использовать для частых символов более короткий код, для редких – более длинный. Трудность заключается в том, что коды получаются переменной длины и в общем потоке выходных данных трудно обнаружить конец одного кода и начало другого.
Однако, существуют коды, для которых задача определения длины легко решается к таким кодам относятся так называемые неравномерные коды со свойством однозначного декодирования. Например, унарный код (в двоичной системе), где:
“о”-1
“а”-01
“и”-001
...
“щ”-00....1
т.е. для самой частой буквы длина кода составляет 1 бит, для самой редкой-33 бита (32 нуля и единица). Этот код очень прост, но далеко не эффективен. Но еще может нам пригодиться для построения кодов целых переменной длины (Variable Length Integers (VLI) codes). Именно эти коды с успехом применяются в архиваторах ARJ и LHA. VLI-коды состоят из двух частей: сначала следует унарный код, определяющий группу чисел определенной длины, а затем само число указанной длины. Таким образом, унарный код выполняет роль префикса, указывающего – какой длины будет следующее число. Для записи VLI-кодов используют три числа: (start, step, stop), где start определяет начальную длину числа, step -приращение длины для следующей группы, stop -конечную длину.
Например: код (3, 2, 9) задает четыре группы чисел:
0ххх - числа от 0 до 7, группа 0,
10ххххх - числа от 8 до 39, группа 1,
110ххххххх - числа от 40 до 167, группа 2,
111ххххххххх - числа от 168 до 679, группа 3.
Унарный код для n-ой группы – n единиц, затем ноль; для последней группы-только n единиц, так как это не вносит неопределенности. Размер числа из n-ой группы равен start + n× step. VLI-коды удобно применять для кодирования монотонных источников, для которых вероятность появления меньших чисел выше, чем больших. При отсутствии кодирования любое число представлялось бы десятью битами.
Идея, лежащая в основе кода Хаффмана, достаточно проста. Вместо того чтобы кодировать все символы одинаковым числом бит (как это сделано, например, в ASCII кодировке, где на каждый символ отводится ровно по 8 бит), будем кодировать символы, которые встречаются чаще, меньшим числом бит, чем те, которые встречаются реже.
Алгоритм был опубликован Дэвидом Хаффманом (David Huffman) в 1952 году, и за прошедшие 50 лет со дня опубликования, код Хаффмана ничуть не потерял своей актуальности и значимости. Данный алгоритм и сейчас активно используется различными архиваторами.
Алгоритм Хаффмана двухпроходный. На первом проходе строится частотный словарь и генерируются коды, на втором проходе происходит непосредственно кодирование.
Определение 1: Пусть A={a1,a2,...,an} - алфавит из n различных символов, W={w1,w2,...,wn} - соответствующий ему набор положительных целых весов. Тогда набор бинарных кодов C={c1,c2,...,cn}, такой что:
1. ci не является префиксом для cj, при i ¹ j.
2. 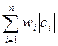 минимальна (|ci| длина кода ci).
минимальна (|ci| длина кода ci).
называется минимально-избыточным префиксным кодом или иначе кодом Хаффмана.
Замечания:
1. Свойство (1) называется свойством префиксности. Оно позволяет однозначно декодировать коды переменной длины.
- Сумму в свойстве (2) можно трактовать как размер закодированных данных в битах. На практике это очень удобно, т.к. позволяет оценить степень сжатия не прибегая непосредственно к кодированию.
Известно, что любому бинарному префиксному коду соответствует определенное бинарное дерево.
Определение 2: Бинарное дерево, соответствующее коду Хаффмана, будем называть деревом Хаффмана.
Задача построения кода Хаффмана равносильна задаче построения соответствующего ему дерева. Приведем общую схему построения дерева Хаффмана:
- Составим список кодируемых символов.
- Из списка выберем 2 узла (элемента) с наименьшим весом.
- Сформируем новый узел и присоединим к нему, в качестве дочерних, два узла выбранных из списка. При этом вес сформированного узла положим равным сумме весов дочерних узлов.
- Добавим сформированный узел к списку.
- Если в списке больше одного узла, то повторить 2-5.
Приведем пример: построим дерево Хаффмана для сообщения
S="A H F B H C E H E H C E A H D C E E H H H C H H H D E G H G G E H C H H".
Для начала введем несколько обозначений:
- Веса узлов будем обозначать нижними индексами: A 5, B 3, C 7.
- Составные узлы будем заключать в скобки: ((A 5+ B 3)8+ C 7)15.
Итак, в нашем случае A={ A, B, C, D, E, F, G, H }, W={2, 1, 5, 2, 7, 1, 3, 15}.
- A 2 B 1 C 5 D 2 E 7 F 1 G 3 H 15
- A 2 C 5 D 2 E 7 G 3 H 15 (F 1+ B 1)2
- C 5 E 7 G 3 H 15 (F 1+ B 1)2 (A 2+ D 2)4
- C 5 E 7 H 15 (A 2+ D 2)4 ((F 1+ B 1)2+ G 3)5
- E 7 H 15 ((F 1+ B 1)2+ G 3)5 (C 5+(A 2+ D 2)4)9
- H 15 (C 5+(A 2+ D 2)4)9 (((F 1+ B 1)2+ G 3) 5+ E 7)12
- H 15 ((C 5+(A 2+ D 2)4) 9+(((F 1+ B 1)2+ G 3) 5+ E 7)12)21
- (((C 5+(A 2+ D 2)4) 9+(((F 1+ B 1)2+ G 3) 5+ E 7)12)21+ H 15)36
В списке, как и требовалось, остался всего один узел. Дерево Хаффмана построено. Теперь запишем его в более привычном для нас виде.
ROOT /\ 0 1 / \ /\ H / \ / \ / \ 0 1 / \ / \ / \ / \ /\ /\ 0 1 0 1 / \ / \ C /\ /\ E 0 1 0 1 / \ / \ A D /\ G 0 1 / \ F BЛистовые узлы дерева Хаффмана соответствуют символам кодируемого алфавита. Глубина листовых узлов равна длине кода соответствующих символов.
Путь от корня дерева к листовому узлу можно представить в виде битовой строки, в которой "0" соответствует выбору левого поддерева, а "1" - правого. Используя этот механизм, мы без труда можем присвоить коды всем символам кодируемого алфавита. Выпишем, к примеру, коды для всех символов в нашем примере:
| A=0010bin | C=000bin | E=011bin | G=0101bin |
| B=01001bin | D=0011bin | F=01000bin | H=1bin |
Теперь у нас есть все необходимое для того чтобы закодировать сообщение S. Достаточно просто заменить каждый символ соответствующим ему кодом:
S/="0010 1 01000 01001 1 000 011 1 011 1 000 011 0010 1 0011 000 011 011 1 1 1 000 1 1 1 0011 011 0101 1 0101 0101 011 1 000 1 1".
Оценим теперь степень сжатия. В исходном сообщении S было 36 символов, на каждый из которых отводилось по élog2|A|ù = 3 бита. Таким образом, размер S равен 36*3=108 бит
Размер закодированного сообщения S/ можно получить воспользовавшись замечанием 2 к определению 1, или непосредственно, подсчитав количество бит в S/. И в том и другом случае мы получим 89 бит.
Алгоритм декодирования: Начиная с корня дерева двигаться вниз, выбирая левое поддерево, если очередной бит в потоке равен "0", и правое - если "1". Дойдя до листового узла декодируем соответствующий ему символ.
|
|
|
|
|
Дата добавления: 2014-12-16; Просмотров: 1492; Нарушение авторских прав?; Мы поможем в написании вашей работы!