КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Цифровая обработка сигналов в СМС. 1 страница
|
|
|
|
4.1 Роль и построение цифровой обработки; характеристики речевых сигналов. Аналого-цифровое преобразование. Сегментация и кодирование речи. Канальное кодирование и перемежение.
Цифровая обработка сигналов - важный элемент в аппаратурной реализации принципов сотовой связи. Именно цифровая обработка обеспечила возможность перехода от первого поколения сотовой связи ко второму с соответствующим совершенствованием методов множественного доступа, повышением емкости системы, улучшением качества связи. Только в цифровой форме оказывается возможным применение экономичного (с устранением избыточности) кодирования речи, эффективного канального кодирования с высокой степенью защиты от ошибок, совершенных методов борьбы с многолучевым распространением.
Цифровую обработку сигналов можно разделить на два этапа:
- аналого-цифровое преобразование сигналов;
- кодирование речи.
Каждому из этапов обработки в передающем тракте соответствует этап обработки в приемном тракте, так что в идеализированной ситуации - при отсутствии шумов, помех и искажений при обработке и распространении сигналов - форма сигнала в соответствующих точках передающего и приемного трактов, например на выходе кодера речи и на входе декодера речи, на выходе АЦП и на входе ЦАП, тождественна. Реально этой тождественности не получается, но обработка сигналов должна быть построена таким образом, чтобы искажения не превышали допустимых пределов.
Аналого-цифровое преобразование является первым этапом цифровой обработки сигналов в передающем тракте. Работа АЦП складывается из двух этапов, которые в реальном устройстве часто не могут быть четко отделены один от другого: дискретизации входного непрерывного сигнала во времени обычно с постоянным шагом, т.е. через равные интервалы времени, и квантования величины сигнала по уровню для этих дискретных моментов времени. В результате на выходе АЦП появляются двоичные числа, т.е. наборы единиц и нулей, соответствующие уровням сигнала в моменты дискретизации.
В соответствии с теоремой Котельникова, частота дискретизации должна быть по крайней мере вдвое выше наибольшей частоты в спектре обрабатываемого сигнала. Поскольку, как указывалось в предыдущем разделе, при передаче сигналов речи по телефонным каналам связи ограничиваются полосой частот от 300 до 3400 Гц, общепринятой является частота дискретизации fд = 8 кГц.
В результате на выходе АЦП получается поток 8-битовых чисел, следующих с частотой 8 кГц, т е. поток информации на выходе АЦП составляет 64 кбит/с. Практические схемы АЦП чаще всего строятся на основе сравнения выборок мгновенных значений аналогового сигнала с набором эталонов, каждый из которых содержит определенное число уровней квантования.
В схемах ЦАП, как правило, используется формирование аналоговых величин (токов), пропорциональных весовым коэффициентам разрядов входного двоичного кода, с последующим суммированием в разрядах кода, содержащих единицы.
Кодирование речи. Кодер речи является первым элементом собственно цифрового участка передающего тракга, следующим после АЦП. Основная задача кодера (англ. термин encoder) - предельно возможное сжатие сигнала речи, представленного в цифровой форме, т.е. предельно возможное устранение избыточности речевого сигнала, но при сохранении приемлемого качества передачи речи. Компромисс между степенью сжатия и сохранением качества отыскивается экспериментально, а проблема получения вьюокой степени сжатия без чрезмерного снижения качества составляет основную трудность при разработке кодера. В приемном тракге перед ЦАП размещен декодер речи, задача декодера (англ. термин decoder) - восстановление обычного цифрового сигнала речи, с присущей ему естественной избыточностью, по принятому кодированному сигналу. Сочетание кодера и декодера называют кодеком (англ. термин codec).
Прежде чем перейти к рассмотрению кодеров речи, используемых в сетях радиодоступа, приведем некоторые общие сведения об основных методах кодирования.
Исторически сложилось два направления кодирования речи: кодирование формы сигнала (waveform coding) и кодирование источника сигнала (source coding).
Первый метод основан на использовании статистических характеристик сигнала и пракгически не зависит от механизма формирования сигнала. Кодеры этого типа с самого начала обеспечивали высокое качество передачи речи (хорошую разборчивость и натуральность речи), но отличались меньшей по сравнению со вторым методом экономичностью. В методе кодирования формы сигнала используются три основных способа кодирования: импульсно-кодовая модуляция HKIVI (Pulse Code Modulation - PCM), дифференциальная ИКМ - ДИКМ (Differential PCM - DPCM) и дельта-модуляция ДМ (Delta Modulation - DM). ИКМ соответствует цифровой сигнал непосредственно с выхода АЦП, в нем сохраняется вся избыточность аналогового речевого сигнапа. При ДИКМ эта избыточность несколько уменьшается за счет того, что квантованию с последующим кодированием и передачей по линии связи подвергается разность между исходным речевым сигналом и его предсказанным значением, а при приеме разностный сигнал скпадывается с предсказанным значением, полученным по тому же алгоритму предсказания. Шкала квантования может быть равномерной, неравномерной или адаптивно изменяемой, предсказание сигнала может не зависеть от формы последнего или же зависеть от формы сигнала, т.е. быть адаптивным. Если при кодировании сигнала используются элементы адаптации, то соответствующую разновидность ДИКМ называют адаптивной ДИКМ -АДИКМ (Adaptive DPCM - ADPCM). ДМ - это ДИКМ с однобитовым квантованием, она также может быть адаптивной (АДМ). АДИКМ находит применение, например, в беспроводном телефоне (СТ) с коэффициентом сжатия сигнала около 2.
Второй метод - кодирование источника сигнала, или кодирование параметров сигнала - первоначально основывался на данных о механизмах речеобразования, т.е. использовал своего рода модель голосового тракта и приводил к системам типа анализ - синтез, получившим название вокодерных систем, или вокодеров (vocoder - сокращение от voice coder, т.е. кодер голоса или кодер речи). Уже ранние вокодеры позвопяли получить весьма низкую скорость передачи информации, но при характерном синтетическом качестве речи на выходе. Поэтому вокодерные методы долгое время оставались в основном областью приложения усилий исследователей и энтузиастов, не находя широкого практического применения. Ситуация существенно изменилась с выходом на сцену метода линейного предсказания, предложенного в 60-х годах и получившего мощное развитие в 80-х, в том числе в прямой связи с разработкой речевых кодеков для цифровых систем сотовой связи. Именно вокодерные методы на основе линейного предсказания и применяются в сотовой связи, причем зависимость этих методов от данных о механизмах речеобразования отступает на второй или даже третий план, а оценка передаваемых по линии связи параметров производится на основе статистических характеристик сигнала по жестко определенному алгоритму, как и при кодировании формы сигнала. Поэтому фактически граница между двумя классическими методами кодирования - кодирования формы сигнала и кодирования источника сигнала - до некоторой степени стирается.
Кодер речи является первым элементом собственно цифрового участка передающего тракта АЦП. Основная задача кодера – предельно возможное сжатие сигнала речи, представленного в цифровой форме, т.е. предельно возможное устранение избыточности речевого сигнала, но при сохранении приемлемого качества передачи речи. Компромисс между степенью сжатия и сохранением качества отыскивается экспериментально, а проблема получения высокой степени сжатия без чрезмерного снижения качества составляет основную трудность при разработке кодера. В приемном тракте перед ЦАП размещен декодер речи; задача декодера – восстановление обычного цифрового сигнала речи (с присущей ему естественной избыточностью) по принятому кодированному сигналу. Сочетание кодера и декодера называют кодеком.
Ситуация существенно изменилась с появлением метода линейного предсказания, получившего мощное развитие в 1980-х годах на основе достижений микроэлектроники.
В настоящее время в системах подвижной связи получили распространение вокодерные методы на основе метода линейного предсказания. Суть кодирования речи на основе метода линейного предсказания (Linear Predictive Coding – LРС) заключается в том, что по линии связи передаются не параметры речевого сигнала, а параметры некоторого фильтра, в определенном смысле эквивалентного голосовому тракту, и параметры сигнала возбуждения этого фильтра. В качестве такого фильтра используется фильтр линейного предсказания. Задача кодирования на передающем конце линии связи заключается в оценке параметров фильтра и параметров сигнала возбуждения, а задача декодирования на приемном конце – в пропускании сигнала возбуждения через фильтр, на выходе которого получается восстановленный сигнал речи.
Значения коэффициентов предсказания, постоянные на интервале кодируемого сегмента речи (на практике длительность сегмента составляет 20 мс), находятся из условия минимизации среднеквадратического значения остатка предсказания на интервале сегмента.
Таким образом, процедура кодирования речи в методе линейного предсказания сводится к следующему:
· оцифрованный сигнал речи нарезается на сегменты длительностью 20 мс;
· для каждого сегмента оцениваются параметры фильтра линейного предсказания и параметры сигнала возбуждения; в качестве сигнала возбуждения в простейшем случае может выступать остаток предсказания, получаемый при пропускании сегмента речи через фильтр линейного предсказания с параметрами, полученными из оценки для данного сегмента;
· параметры фильтра и параметры сигнала возбуждения кодируются по определенному закону и передаются в канал связи.
Процедура декодирования речи заключается в пропускании принятого сигнала возбуждения через синтезирующий фильтр известной структуры, параметры которого переданы одновременно с сигналом возбуждения.
Во-первых, линейное предсказания – кратковременное предсказание (STP – Short-Term Prediction) не обеспечивает достаточной степени устранения избыточности речи. Поэтому в дополнение к кратковременному предсказанию используется еще долговременное предсказание (LTP – Long-Term Prediction), в значительной мере устраняющее остаточную избыточность и приближающее остаток предсказания по своим статистическим характеристикам к белому шуму.
В стандарте GSM используется метод RPE-LTP (Regular Pulse Excited Long Term Predictor – линейное предсказание с возбуждением регулярной последовательностью импульсов и долговременным предсказателем).
Блок предварительной обработки кодера осуществляет:
· предыскажение входного сигнала при помощи цифрового фильтра, подчеркивающего верхние частоты;
· нарезание сигнала на сегменты по 160 выборок (20 мс);
· взвешивание каждого из сегментов окном Хэмминга («косинус на пьедестале» – амплитуда сигнала плавно спадает от центра окна к краям).
Далее для каждого 20-миллисекундного сегмента оцениваются параметры фильтра кратковременного линейного предсказания – 8 коэффициентов частичной (порядок предсказания М = 8), которые для передачи по каналу связи преобразуются в логарифмические отношения площадей, причем для функции логарифма используется кусочно-линейная аппроксимация.
Сигнал с выхода блока предварительной обработки фильтруется решетчатым фильтром-анализатором кратковременного линейного предсказания и по его выходному сигналу (остатку предсказания) оцениваются параметры долговременного предсказания: коэффициент предсказания и задержка. При этом 160-выборочный сегмент остатка кратковременного предсказания разделяется на 4 подсегмента по 40 выборок в каждом.
В качестве сигнала возбуждения выбирается та из последовательностей, энергия которой больше. Амплитуды импульсов нормируются по отношению к импульсу с наибольшей амплитудой, и нормированные амплитуды кодируются тремя битами каждая при линейной шкале квантования. Абсолютное значение наибольшей амплитуды кодируется шестью битами в логарифмическом масштабе. Положение начального импульса 13-элементной последовательности кодируется двумя битами, т.е. кодируется номер последовательности, выбранной в качестве сигнала возбуждения для данного подсегмента.
Таким образом, выходная информация кодера речи для одного 20-миллисекундного сегмента речи включает параметры:
· фильтра кратковременного линейного предсказания;
· фильтра долговременного линейного предсказания;
· сигнала возбуждения.
Число битов, отводимых на кодирование передаваемых параметров, для одного 20-миллисекундного сегмента речи передается 260 бит информации, т.е. рассмотренный речевой кодер осуществляет сжатие информации по отношению к несжатому оцифрованному речевому сигналу (20 миллисекундному сегменту соответствует 160 восьмиразрядных отсчетов или 1280 битов) почти в 5 раз (1280: 260 = 4,92). Перед выдачей в канал связи выходная информация кодера речи также подвергается дополнительно канальному кодированию.
Речь разделяется на 20 миллисекундные фрагменты, каждый из которых кодируется в 260 битов, давая суммарную скорость передачи 13 кб/с.
Декодер. Блок формирования сигнала возбуждения, используя принятые параметры сигнала возбуждения, восстанавливает 13-импульсную последовательность сигнала возбуждения для каждого из подсегментов сигнала речи, включая амплитуды импульсов и их расположение во времени. Сформированный таким образом сигнал возбуждения фильтруется фильтром-синтезатором долговременного предсказания, на выходе которого получается восстановленный остаток предсказания фильтра-анализатора кратковременного предсказания.
Последний фильтруется решетчатым фильтром-синтезатором кратковременного предсказания, причем параметры фильтра предварительно преобразуются из логарифмических отношений площадей, в коэффициенты частичной корреляции. Выходной сигнал фильтра-синтезатора кратковременного предсказания фильтруется (в блоке постфильтрации) цифровым фильтром, восстанавливающим амплитудные соотношения частотных составляющих сигнала речи, т.е. компенсирующим предыскажение, внесенное входным фильтром блока предварительной обработки кодера. Сигнал на выходе постфильтра является восстановленным цифровым сигналом речи.
Кодер канала - второй (и последний) элемент собственно цифрового участка передающего тракта. Он следует после кодера речи и предшествует модулятору, осуществляющему перенос информационного сигнала на несущую частоту. Основная задача кодера канала - помехоустойчивое кодирование сигнала речи, т.е. такое его кодирование, которое позволяет обнаруживать и в значительной мере исправлять ошибки, возникающие при распространении сигнала по радиоканалу от передатчика к приемнику. Помехоустойчивое кодирование осуществляется за счет введения в состав передаваемого сигнала довольно большого объема избыточной (контрольной) информации. В английской терминологии такое кодирование носит наименование Forward Error Correcting coding (FEC coding), т.е. кодирование с упреждающей коррекцией ошибок, или кодирование с коррекцией ошибок на проходе. В сотовой связи помехоустойчивое кодирование реализуется в виде трех процедур - блочного кодирования (block coding), сверточного кодирования (convolutional coding) и перемежения (interleaving). Кроме того, кодер канала выполняет еще ряд функций: добавляет управляющую информацию, которая, в свою очередь, также подвергается помехоустойчивому кодированию; упаковывает подготовленную к передаче информацию и сжимает ее во времени; осуществляет шифрование передаваемой информации, если таковое предусмотрено режимом работы аппаратуры.
При блочном кодировании входная информация разделяется на блоки, содержащие по k символов каждый, которые по определенному закону преобразуются кодером в n-символьные блоки, причем n > k. Отношение R = k/n носит наименование скорости кодирования (coding rate) и является мерой избыточности, вносимой кодером. При рационально построенном кодере меньшая скорость кодирования, т.е. большая избыточность, соответствует более высокой помехоустойчивости.
Повышению помехоустойчивости способствует также увеличение длины блока. Блочный кодер с параметрами n, k обозначается (n, k). Если символы входной и выходной последовательностей являются двоичными, т.е. состоят из одного бита каждый, то кодер называется двоичным (binary); именно двоичные кодеры используются в сотовой связи. Каждый бит блока выходной информации получается как сумма по модулю 2 нескольких бит (от одного до k) входного блока, для чего используется n сумматоров по модулю 2.
Схема другого блочного кодера - это так называемый систематический кодер. Отличительная особенность систематического кодера состоит в том, что в состав блока выходной информации включается полностью блок входной информации; тривиальные сумматоры, соответствующие формированию этой части выходного блока, на схеме не показаны. Систематический кодер - простейший: выходной блок, помимо копии входного, содержит лишь один избыточный бит, который является суммой по модулю 2 всех бит входного блока.
Этот избыточный бит называется кодом контроля четности, поскольку, как нетрудно убедиться, число единиц в выходном блоке, с учетом контрольного бита, оказывается четным. Для 8-битового блока двоичной информации используется наименование байт, и схема (рис.4.1)может быть названа схемой побайтного контроля четности. На примере этой схемы можно показать возможность обнаружения ошибок при помощи блочного кода, а затем, несколько усложнив схему кодирования, - и возможность коррекции ошибок.
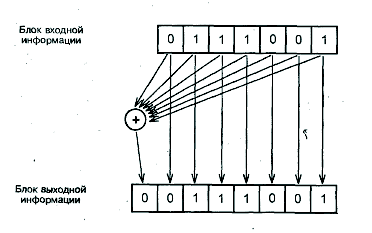 |
Рис.4.1. Схема систематического двоичного блочного кодера(8,7)
На рис.4.2а показаны семь блоков выходной информации кодера рис.4.1, причем последний бит в каждом байтовом блоке, отмеченный затененным фоном, является кодом четности. Очевидно, что при наличии одиночной ошибки в любом блоке, включая и ошибку в коде четности, нарушается правило формирования кода четности, на основании чего она и обнаруживается. Однако ошибка локализуется лишь с точностью до байта, а потому не может быть исправлена, ибо неизвестно, какой именно бит в байте ошибочен.
Рис.4.2. Обнаружение и коррекция ошибок при блочном кодировании.
а- побайтовый контроль четности позволяет обнаружить одиночные ошибки в байтах.
б– добавление ещё 8 бит позволяет исправить одиночную ошибку в восьми байтах.
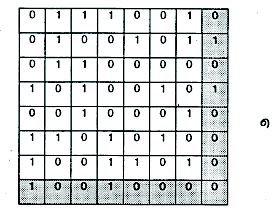 |
 Столь же очевидно, что двойная ошибка в блоке (и вообще - ошибка в четном числе бит) этой схемой не обнаруживается.
Столь же очевидно, что двойная ошибка в блоке (и вообще - ошибка в четном числе бит) этой схемой не обнаруживается.
Если, помимо контроля четности по строкам для всей приведенной информации (рис.4.2а), ввести еще и контроль чётности по столбцам (нижняя строка на рис.4.2б), то при наличии одиночной ошибки в этом 64-битовом блоке мы сможем указать не только строку, содержащую ошибку, но и столбец с ошибкой, а следовательно - и ошибочный бит, лежащий на пересечении этих строки и столбца. А если известно, что бит ошибочен, то он элементарно исправляется, поскольку для этого достаточно заменить нуль на единицу или единицу на нуль - в зависимости от того, каково значение ошибочного бита. Кратные ошибки этой схемой уже не исправляются. Для коррекции кратных ошибок нужно использовать более совершенные (и более сложные) схемы кодеров. Заметим, что рис. 4.2б соответствует систематическому двоичному блочному кодеру (64, 49), и при желании его схема без труда может быть построена по аналогии с рис.4.1.
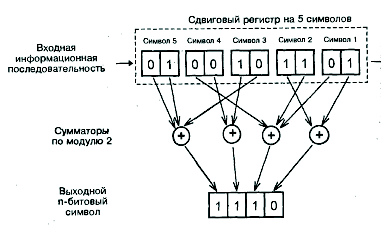 |
Рис.4.3. Схема свёрточного кодера (4,2,5) (n=4, k=2, R=k/n=1/2)
При сверточном кодировании (рис. 4.3) К последовательных символов входной информационной последовательности, по k бит в каждом символе, участвуют в образовании n-битовых символов выходной последовательности, n > k, причем на каждый символ входной последовательности приходится по одному символу выходной.
Каждый бит выходной последовательности получается как Результат суммирования по модулю 2 нескольких бит (от двух до Kk бит) К входных символов, для чего используются п сумматоров по модулю 2. Сверточный кодер с параметрами n, k, К обозначается (n, k, K). Отношение R = k/n, как и в блочном кодере, называется скоростью кодирования.
Параметр К называется длиной ограничения (constraint length); он определяет длину сдвигового регистра (в символах), содержимое которого участвует в формировании одного выходного символа.
После того как очередной выходной символ сформирован, входная последовательность сдвигается на один символ вправо (рис. 4.3), в результате чего символ 1 выходит за пределы регистра, символы 2…5 перемещаются вправо, каждый на место соседнего, а на освободившееся место записывается очередной символ входной последовательности, и по новому содержимому регистра формируется следующий выходной символ. Название сверточного кода обязано тому, что он может рассматриваться как свертка импульсной характеристики кодера и входной информационной последовательности. Если k = 1, т.е. символы входной последовательности однобитовые, сверточный кодер называется двоичным. Сверточный кодер, схема которого приведена на рис. 2, не является двоичным, поскольку для него k = 2.
Перемежение представляет собой такое изменение порядка следования символов информационной последовательности, т.е. такую перестановку, или перетасовку, символов, при которой стоявшие рядом символы оказываются разделенными несколькими другими символами. Такая процедура предпринимается с целью преобразования групповых ошибок (пакетов ошибок) в одиночные ошибки, с которыми легче бороться с помощью блочного и сверточного кодирования. Использование перемежения - одна из характерных особенностей сотовой связи, и это является следствием неизбежных глубоких замираний сигнала в условиях многолучевого распространения, которое практически всегда имеет место, особенно в условиях плотной городской застройки. При этом группа следующих один за другим символов, попадающих на интервал замирания (провала) сигнала, с большой вероятностью оказывается ошибочной. Если же перед выдачей информационной последовательности в радиоканал она подвергается процедуре перемежения, а на приемном конце восстанавливается прежний порядок следования символов, то пакеты ошибок с большой вероятностью рассыпаются на одиночные ошибки. Известно несколько различных схем перемежения и их модификаций - диагональная, блочная, свёрточная и другие.
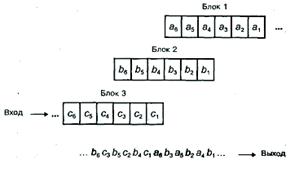 Рис.4.4. Схема диагонального перемежения. Рис.4.5. Схема блочного перемежения.
Рис.4.4. Схема диагонального перемежения. Рис.4.5. Схема блочного перемежения.
 |
При диагональном перемежении входная информация делится на блоки, а блоки - на субблоки, и в выходной последовательности субблоки, например, второй половины предыдущего блока чередуются с субблоками первой половины следующего блока. Такая схема иллюстрируется рис.4.4, где каждый блок состоит из шести субблоков, и субблоки первого блока обозначены аi, второго - bi третьего - сi. Субблок может состоять из нескольких символов, или из одного символа, или даже из одного бита. Приведённая схема диагонального перемежения вносит малую задержку, но расставляет соседние символы лишь через один, т.е. рассредоточение ошибочных символов группы получается сравнительно небольшим.
При блочном перемежении входная информация также делится на блоки, по n субблоков (или символов) в каждом, и в выходной последовательности чередуются субблоки k последовательных блоков. Работу этой схемы можно представить себе в виде записи блоков входной последовательности в качестве строк матрицы размерности k х п (рис. 4.5), считывание информации из которой производится по столбцам. Следовательно, если входная последовательность в этом примере имела вид а1, а2, … аn, b1, b2, … bn, … k1, k2 …kn, то выходная будет такой: a1, b1, … k1, a2, b2, … k2, … an, bn, … kn. Субблоки, или символы, в частном случае здесь также могут состоять лишь из одного бита. Схема блочного перемежения вносит большую задержку, чем диагонального, но значительно сильнее рассредоточивает символы группы ошибок.
В стандарте GSM 260 бит информации, кодирующих параметры 20-миллисекундного сегмента речи, разделяются на два класса: класс 1 - 182 бита, защищаемые помехоустойчивым кодированием, и класс 2 - оставшиеся 78 бит, которые передаются без помехоустойчивого кодирования. В свою очередь, из 182 бит класса 1 выделяются 50 наиболее существенных бит, составляющих подкласс 1а, которые подвергаются более мощному кодированию, а остальные 132 бита класса 1 составляют подкласс 1b и кодируются слабее. К подклассу 1а относятся параметры фильтра кратковременного предсказания и часть информации о параметрах фильтра долговременного предсказания, к подклассу 1b - часть информации о параметрах сигнала возбуждения и оставшаяся информация о параметрах фильтра долговременного предсказания, к классу 2 - оставшаяся информация о параметрах сигнала возбуждения.
Информация подкласса 1а кодируется блочным кодом, обнаруживающим ошибки, - укороченным систематическим циклическим кодом (53, 50), дающим 3-битовый код четности. Затем вся информация класса 1 переупаковывается, располагаясь в такой последовательности: биты с четными индексами, код четности подкласса 1а, биты с нечетными индексами в обратной последовательности, четыре добавочных нулевых бита - всего 189 бит. Эти 189 бит подаются на сверточный кодер (2, 1, 5) со скоростью кодирования Д = 1/2 и длиной ограничения К = 5. В результате 378 бит с выхода сверточного кодера вместе с 78 битами класса 2 составляют 456 бит, т.е. поток информации речи на выходе кодера речи равен 456 бит/20 мс, или 22,8 кбит/с. При декодировании информации речи также сначала выполняется свёрточное декодирование информации класса 1, и при этом исправляются ошибки в пределах возможностей кода свертки. Затем по коду четности проверяется наличие остаточных ошибок в информации подкласса 1а, и, если такие ошибки обнаруживаются, информация данного сегмента не идет в последующую обработку, а заменяется интерполированной информацией смежных сегментов.
Перед выдачей в канал связи закодированная информация речи также подвергается перемежению. В стандарте GSM используется достаточно сложная и совершенная схема блочно-диагонального перемежения. 456 бит информации одного 20-миллисекундного сегмента речи разбиваются на 8 подсегментов, и 57 бит одного подсегмента распределяются между смежными восемью подсегментами таким образом, что после перемежения смежными с каждым конкретным битом оказываются соответствующие ему по положению биты, отстоявшие от него до перестановки на 4 подсегмента, причем на четные и нечетные (после перестановки) битовые позиции подсегмента ставятся биты из смежных сегментов. Алгоритм перемежения обладает свойствами квазислучайности, так что смежные биты исходной последовательности оказываются разделенными непостоянным числом бит, что является преимуществом в борьбе с периодическими битовыми ошибками.
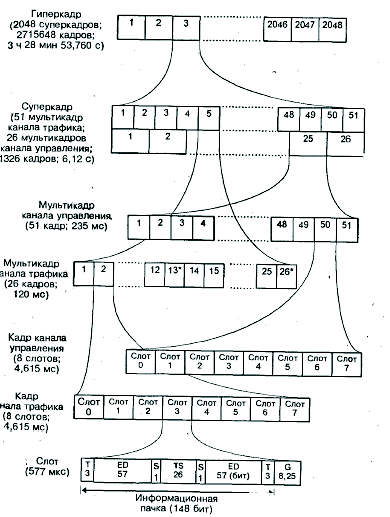
После перемежения 456 бит информации одного сегмента распределяются по одноименным слотам четырех последовательных кадров канала трафика - два поля по 57 бит в слоте (рис.4.6), и каждое 57-битовое поле снабжается дополнительным скрытым флажком, помечающим информацию речи (в отличие от информации управления канала FACCH, которая кодируется иначе).
Информация каналов управления подвергается блочному и свёрточному кодированию в полном объеме. Так, для кодирования информации каналов SACCH, 
 FACCH, FCCH, РСН, AGCH, SDCCH используется блочный кодер (224, 184), сверточный кодер (2, 1, 5), и та же схема перемежения, что и для канала трафика. В каналах RACH, SCH используются другие схемы блочного кодирования, а также сверточные кодеры (2, 1, 5), отличающиеся от сверточных кодеров перечисленных ранее каналов управления. При передаче данных используются более сложные схемы сверточного кодирования и перемежения, обеспечивающие соответственно и более высокое качество передачи информации.
FACCH, FCCH, РСН, AGCH, SDCCH используется блочный кодер (224, 184), сверточный кодер (2, 1, 5), и та же схема перемежения, что и для канала трафика. В каналах RACH, SCH используются другие схемы блочного кодирования, а также сверточные кодеры (2, 1, 5), отличающиеся от сверточных кодеров перечисленных ранее каналов управления. При передаче данных используются более сложные схемы сверточного кодирования и перемежения, обеспечивающие соответственно и более высокое качество передачи информации.
Длительность слота канала трафика, с учетом добавления вспомогательной и служебной информации, составляет 156,25 бит, и, поскольку информация одного 20-миллисекундного сегмента речи занимает по одному слоту в четырех последовательных кадрах, результирующий поток информации составляет 625 бит/20 мс, или 31,25 кбит/с. Эта
информация сжимается во времени в 8 раз, так что на протяжении одного кадра длительностью 4,615 мс передается информация восьми временных слотов, в результате чего частота битовой последовательности возрастает до 250 кбит/с.
Наконец, на каждые 12 кадров канала трафика, несущих информацию речи, добавляется по одному кадру с информацией управления канала SACCH (кадры 13 и 26 мультикадра канала графика на рис.4.6). Таким образом, частота информационной битовой последовательности на выходе кодера канала составляет 270,833 кбит/с.
|
|
|
|
|
Дата добавления: 2014-11-29; Просмотров: 1151; Нарушение авторских прав?; Мы поможем в написании вашей работы!