КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Символы основных характеристик параметров генеральной и выборочной совокупности
|
|
|
|
| № п/п | Характеристика | Генеральная совокупность | Выборочная совокупность |
| Объем совокупности (численность единиц) | N | n | |
| Численность единиц, обладающих обследуемым признаком | M | m | |
| Доля единиц, обладающих обследуемым признаком | P = M: N | w = m:n | |
| Средний размер признака | |||
| Дисперсия количественного признака | |||
| Дисперсия доли | σp² = pq | σw² = w (1- w) |
При проведении выборочного наблюдения используют следующие способы отбора: собственно - случайный, механический, типический, серийный или их сочетание (комбинированный).
Собственно - случайный отбор — когда отбор единиц производится из всей совокупности непреднамеренно (случайно). С этой целью используется жеребьевка.
Механический отбор — разновидность случайного отбора. Его сущность: отбор единиц производится механически, т.е. через определенный интервал. При организации механического отбора единицы генеральной совокупности располагаются по порядку (по алфавиту, и т.д.). Затем отбирают механически число.
Типический отбор — отбор, при котором неоднородная генеральная совокупность предварительно разбивается на однородные (типические) группы, из которых случайно производят отбор необходимой численности выборки.
Серийный отбор — это отбор не отдельных единиц, а их групп. Осуществляется для того, чтобы в таких группах подвергались наблюдению все единицы без исключения.
Различают бесповторный и повторный отбор.
При повторном отборе каждая единица совокупности может участвовать в выборке несколько раз, при бесповторном — это исключено.
10 вопрос.
Расчет ошибок позволяет решить одну из главных проблем организации выборочного наблюдения — оценить репрезентативность (представительность) выборочной совокупности. Различают среднюю и предельную ошибки выборки. Эти два вида ошибок связаны следующим соотношением:
Δ = tμ
где Δ- предельная ошибка выборки,
t — коэффициент доверия, определяемый по таблицам в зависимости от уровня вероятности,
μ — средняя ошибка выборки.
Величина средней ошибки выборки рассчитывается дифференцированно в зависимости от способа отбора и процедуры выборки. Так, при случайном повторном отборе средняя ошибка определяется по формуле:
при бесповторном:
где σ² - выборочная (или генеральная) дисперсия,
σ - выборочное (или генеральное) среднее квадратическое отклонение,
n - объем выборочной совокупности,
N - объем генеральной совокупности.
Расчет средней и предельной ошибок выборки позволяет определить возможные пределы, в которых будут находиться характеристики генеральной совокупности. Например, для выборочной средней такие пределы устанавливаются на основе следующих соотношений:
где и — генеральная и выборочная средние соответственно;
— предельная ошибка выборочной средней.
Наряду с определением ошибок выборки и пределов для генеральной средней эти же показатели могут быть определены для доли признака. В этом случае особенности расчета связаны с определением дисперсии доли, которая вычисляется так:
σ²w = w (1-w).
Тогда при собственно-случайном повторном отборе для определения предельной ошибки выборки используется следующая формула:
Соответственно при бесповторном отборе:
Пределы доли признака в генеральной совокупности р выглядят следующим образом:
w - ∆w £ p £ w + ∆w.
Ошибки и пределы генеральных характеристик при других способах формирования выборочной совокупности определяются на основе соответствующих формул, отражающих особенности этих видов выборки. Например, в случае типической выборки показателем вариации является средняя из внутригрупповых дисперсий - s²i, при серийной выборке — межгрупповая дисперсия δ² и т.д. Кроме того, в последнем случае вместо объема выборочной совокупности n используется показатель серий r.
Следовательно, для типической выборки средняя ошибка вычисляется по формулам:
- при отборе, пропорциональном объему типических групп:
(повторный отбор);
(бесповторный отбор);
- при отборе, пропорциональном вариации признака (не пропорциональных объему групп):
(повторный отбор)
(бесповторный отбор),
где Ni и ni — объемы i-й типической группы и выборки из нее соответственно;
σ²i — групповые дисперсии.
При серийной выборке средняя ошибка определяется следующим образом:
(повторный отбор);
(бесповторный отбор),
где R — число серий в генеральной совокупности,
- межгрупповая дисперсия,
r — число серий в выборочной совокупности.
11 вопрос.
Для количественной оценки рядов динамики применяются различные статистические показатели (характеристики):
- 1) начальный, конечный и средний уровень ряда;
- 2) статистические показатели направления размера изменений уровней ряда во времени;
- 3) средние величины в рядах динамики;
- 4) основная тенденция развития (тренд) и оценка сезонных колебаний;
- 5) Каждый ряд динамики состоит из n-ого числа варьирующих во времени уровней (показателей).
Различают начальный уровень (y1), показывающий величину первого члена ряда и конечный (yn), показывающий величину последнего члена ряда.
Обычно анализ рядов динамики начинается с определения среднего уровня.
Средний уровень ряда даёт обобщённую характеристику показателя за весь период, охватываемый рядом динамики.
Средний уровень в интервальном и моментальном рядах динамики определяется по разному.
В интервальном ряду с равными периодами (интервалами) средний уровень рассчитывается по формуле простой средней арифметической.
Например, средний уровень добычи нефти, выплавки чугуна и так далее ежегодно (за месяц) за рассматриваемый период.
Таким образом, чтобы исчислить среднюю из интервального ряда, нужно сложить члены ряда и разделить полученную сумму на их число.
Эта средняя известна в статистике как Средняя характеристическая для моментального ряда.
Таким образом, средняя хронологическая из моментального ряда динамики равняется сумме показателей этого ряда (при этом начальный и конечный уровни должны быть взяты в половинном размере), делённой на число показателей без одного.
В случае неравных интервалов времени между фактами (моментами, датами) средний уровень ряда определяется в следующей последовательности: 1) определяется средние за интервалы, ограниченные двумя датами; 2) расчёт из них общей средней; при этом средние за более длительные интервалы должны быть взяты с весами, кратные их длине.
Пример. Численность работников предприятия составила на 1.01 - 1100 человек; на 15.02 – 1120 человек; на 22.03 – 1150 человек, на 31.03 тоже 1150 человек.
б) Средний уровень ряда, как любая средняя величина, является обобщающим показателем. Вместе с тем при изучении рядов динамики важно проследить за направлением и размером изменений уровней во времени. С этой целью для динамических рядов (рядов динамики) рассчитываются такие статические показатели, как: 1) темпы роста. 2) абсолютные приросты. 3) темпы прироста. 4) абсолютная величина одного процента роста.
Темпы роста (темпы динамики ТР) – это относительный статистический показатель, определяемый как отношение одного уровня к другому одного и того же и показывающий во сколько раз один уровень больше(меньше) другого.
В зависимости от выбора базы сравнения темпы роста рассчитываются как цепные, когда каждый уровень сопоставляется с уровнем предыдущего периода и как базисные, когда все уровни ряда сопоставляются с уровнем одного какого-то периода, принятого за базу сравнения (как правило, это бывает начальный уровень ряда, но может быть и уровень любого другого периода)
Соответственно цепные темпы роста (Трцi) характеризуют интенсивность развития явления в каждом отдельном периоде, а базисное – интенсивности развития за любой отрезок времени (отделяющий данный уровень от базисного).
В том и другом случае темпы роста могут быть выражены в виде коэффициентов, если основание отношения принимается за единицу, и в виде процентов, если основание принимается за 100.
12 вопрос.
Основной тенденцией ряда динамики (или трендом) называется устойчивое изменение уровня явления во времени, обусловленное влиянием постоянно действующих факторов и свободное от случайных колебаний.
В случаях, когда уровни динамического ряда непрерывно растут или непрерывно снижаются, основная тенденция ряда является очевидной. Однако достаточно часто уровни динамических рядов претерпевают различные изменения (т. е. то растут, то убывают), и общая тенденция неясна. Задача статистики заключается в выявлении тенденции в таких рядах. С этой целью ряды динамики подвергаются обработке методами укрупнения интервалов, скользящей средней и аналитического выравнивания.
Укрупнение интервалов является наиболее простым методом. Он основан на увеличении периодов времени, к которым относятся уровни ряда динамики. Одновременно уменьшается количество интервалов. Рассмотрим применение этого метода на примере ежемесячных данных о выпуске продукции предприятия.
Рассмотренные методы дают возможность определить общую тенденцию изменения уровней ряда динамики. Однако они не позволяют получить обобщенную статистическую модель тренда. С этой целью применяют метод аналитического выравнивания рядов динамики. Основным содержанием метода является то, что общая тенденция развития представляется как функция времени
Определение теоретических уровней ряда динамики производится на основе так называемой адекватной математической модели, наилучшим образом отображающей основную тенденцию. Простейшими моделями для отображения социально-экономических процессов являются следующие:
линейная
показательная степенная парабола
Расчет параметров функции обычно производится методом наименьших квадратов.
Параметры уравнения, удовлетворяющие этому условию, могут быть найдены решением системы нормальных уравнений. На основе полученного уравнения тренда вычисляются теоретические уровни. Таким образом, выравнивание ряда динамики заключается в замене фактических уровней у плавно изменяющимися теоретическими уровнями.
Для окончательного выбора вида адекватной математической функции используются специальные критерии математической статистики (критерий х2, Колмогорова - Смирнова и другие).
13. вопрос.
При сравнении квартальных и месячных данных многих социально-экономических явлений часто обнаруживаются периодические колебания, возникающие под влиянием смены времени года. Они являются результатом влияния природно-климатических условий, общеэкономическихфакторов, а также других многочисленных и разнообразных факторов, которые часто являются регулируемыми.
В статистике периодические колебания, которые имеют определенный и постоянный период, равный годовому промежутку, носят название сезонных колебаний или сезонной волны, а динамический ряд в этом случае называется сезонным рядом динамики. Сезонные колебания наблюдаются в различных отраслях экономики, в том числе в отраслях химико-лесного комплекса. В ряде случаев они могут отрицательно влиять на результаты производственной деятельности. Поэтому встает вопрос о регулировании сезонных изменений. В основе этого регулирования должно лежать исследование сезонных колебаний.
В статистике существует ряд методов изучения и измерения сезонных колебаний. Самый простой из них заключается в расчете специальных показателей, называемых индексами сезонности I s .Совокупность этих показателей отражает сезонную волну.
Для того чтобы выявить устойчивую сезонную волну, на которой не отражались бы случайные условия одного года, индексы сезонных колебаний вычисляются по данным за несколько лат (неменее трех).
Если ряд динамики не содержит ярко выраженной тенденция в развитии, то индексы сезонности вычисляются непосредственно по эмпирическим данным без их предварительного выравнивания.
Для каждого месяца рассчитывается средняя величина уровня, например, за три года (γi), затем вычисляется среднемесячный уровень для всего ряда (γ). После этого определяются индексы сезонности, представляющие собой процентные отношения средних для каждого месяца к общему среднемесячному уровню ряда
14 вопрос.
Простейшим показателем, используемым в индексном анализе, является индивидуальный индекс, который характеризует изменение во времени экономических величин, относящихся к одному объекту:
ip=p1/p0 – индекс цены где p1 – цена товара в текущем периоде; p0 – цена товара в базисном периоде;
iq=q1/q0 – индекс физического объема реализации;
ipq=p1q1/p0q0- индекс товарооборота.
Индивидуальные индексы, в сущности, представляют собой относительные показатели динамики или темпы роста, и по данным за несколько периодов времени могут рассчитываться в цепной или базисной формах.
В тех случаях, когда исследуются не единичные объекты, а состоящие из нескольких элементов совокупности, используются сводные индексы. Исходной формой сводного индекса является агрегатная.
При расчете агрегатного индекса для разнородной совокупности находят такой общий показатель, в котором можно объединить все ее элементы.
15 вопрос.
Способ построения агрегатных индексов заключается в том, что при помощи так называемых соизмерителей можно выразить итоговые величины сложной совокупности в отчетном и базисном периодах, а затем первую сопоставить со второй.
Агрегатный индекс ФОП (предложен Э. Ласпейресом) отражает изменение выпуска всей совокупности продукции, где индексируемой величиной является количество продукции q, а соизмерителем - цена р:
I=(E(q1*p0))/(E(q0*p0)
где q1 и q0 - количество выработанных единиц отдельных видов продукции соответственно в отчетном и базисном периодах; p0 - цена единицы продукции (отдельного вида) в базисном периоде.
При вычислении индекса ФОП в качестве соизмерителей может выступать также себестоимость продукции или трудоемкость.
16 вопрос.
Третьим индексом в индексной системе является сводный индекс физического объема реализации. Он характеризует изменение количества проданных товаров не в денежных, а в физических единицах измерения.
Цепные и базисные индексы.
В зависимости от базы сравнения различают цепные и базисные индексы. Для того, чтобы построить индексы нужны данные за два периода, за отчетный и базисный, однако возникает необходимость узнать эти изменения не за два периода, а за несколько периодов и в этом случае исчисляют цепные и базисные индексы.
Цепные – это каждый последующий к предыдущему.
Базисный – каждый последующий к базе.
В ряде случаев на практике вместо индексов в агрегатной форме удобнее использовать средние арифметические и средние гармонические индексы. Любой сводный индекс можно представить как среднюю взвешенную из индивидуальных индексов. Однако при этом форму средней нужно выбрать таким образом, чтобы полученный средний индекс был тождественен исходному агрегатному индекс.
17 вопрос.
Индексный метод основан на относительных показателях, выражающих отношение уровня данного явления к уровню его в прошлое время или к уровню аналогичного явления, которое принято за базу. Произвольный индекс исчисляется сопоставлением сопоставимых величины (отчетной) с базисной. Индексы, выражающие соотношение непосредственно сопоставимых величин, называются индивидуальными, а индексы, характеризующие отношение сложных явлений - групповыми или тотальными.
18 вопрос.
Статистическое изучение взаимосвязей является одним из важнейших разделов статистики. Изучение взаимосвязей между различными явлениями общественной жизни позволяет предсказывать развитие процессов, зависимых от других, и, в конечном счете, оказывать на них влияние. Таким образом, изучение связей позволяет от объяснения фактов перейти к изменению фактов.
Взаимосвязь — это совместное согласованное изменение двух или нескольких признаков.
Присутствие взаимосвязи между различными явлениями, процессами выражается во взаимосогласованном изменении статистических данных, описывающих эти процессы.
þ Например, стаж работы является одним из факторов роста производительности труда. Поэтому увеличение стажа, как правило, приводит к росту выработки. Статистические данные отражают согласованность в изменении обоих показателей.
Все многообразие взаимосвязей принято классифицировать по различным признакам:
- Форма проявления:
- Причинно-следственные связи — в том случае, когда из двух взаимодействующих признаков можно выделить причину и следствие, признак-фактор (x) и признак-результат (y).
þ Например, взаимосвязь между объемом производимой продукции и себестоимостью единицы продукции проявляется следующим образом: с увеличением объема производимой продукции себестоимость единицы продукции снижается. Здесь, объем продукции — признак-фактор, а себестоимость — признак-результат.
- Связи соответствия — в случае, когда нет возможности выделить причину и следствие, в частности оба согласованно меняющихся признака являются следствиями третьего признака.
- Механизм связи:
- функциональная;
- стохастическая (статистическая).
Под функциональной зависимостью между явлениями понимается такая связь, которая может быть выражена для каждого случая вполне определенно строгой математической формулой.
При функциональной зависимости каждому значению одной величины соответствует одно или несколько, но вполне определенных значений другой величины. Например, отношения между стороной и площадью квадрата (S = a2), временем и путем при движении с постоянной скоростью (S = vt) и тому подобными величинами, часто встречающимися в геометрии, механике.
Для массовых социальных явлений характерны зависимости другого рода, возникающие в результате взаимодействия многих причин и условий и осложненные действием объективной случайности и ошибок наблюдения. Выразить подобные зависимости с помощью однозначных, точных формул, пригодных для описания каждого отдельного случая невозможно.
При статистической связи разным значениям одной переменной соответствуют разные распределения значений другой переменной.
Частным случаем статистической связи является корреляционная связь.
Корреляционная зависимость — взаимосвязь между признаками, состоящая в том, что средняя величина значений одного признака меняется в зависимости от изменения другого признака (например, зависимость между выработкой и стажем работы, между числом судимостей преступника и временем его нахождения на свободе между ними и др.). Здесь, в отличие от функциональной зависимости, в индивидуальных случаях при определении значения одного признака могут быть разные значения другого, то есть совсем не обязательно, что обнаруженная связь будет подтверждаться в каждом конкретном случае.
þ Например, изменение профессорско-преподавательского состава в сторону увеличения числа преподавателей, имеющих ученую степень, приводит в конечном итоге к повышению качества образования. Но это не значит, что каждый отдельно взятый выпускник будет обладать большим набором знаний, чем выпускник учебного заведения, имеющего более «слабый» преподавательский состав.
Следовательно, в статистическом анализе корреляционные зависимости проявляются не между каждой парой сопоставляемых данных, а между изменениями в рядах распределения множества соответствующих величин.
Кроме того, что корреляционная зависимость не имеет функционального характера, следует учитывать две ее особенности:
- вывод может быть сделан только на основе анализа достаточно больших статистических совокупностей, позволяющих построить относительно длинные статистические ряды;
- желательно, чтобы число наблюдений было не менее чем в 5-6 раз больше числа факторов.
Корреляционный анализ имеет смысл лишь в тех случаях, когда возможность причинной связи между анализируемыми признаками теоретически обоснована хотя бы на уровне содержательной гипотезы.
Если с изменением значения признака среднее значение другого признака не изменяется закономерным образом, но закономерно изменяется другая статистическая характеристика (например, показатели вариации), то связь не является корреляционной, но является статистической.
В случае статистической связи предполагается, что оба признака имеют случайную вариацию индивидуальных значений относительно средней величины, то есть каждый из признаков принимает несколько случайных значений. В том случае, если такую вариацию имеет один из признаков, а значения другого являются жестко детерминированными, то говорят о регрессии, но не о статистической связи. При анализе динамических рядов можно измерять регрессию уровней ряда (имеющих случайную колеблемость) на номера лет. Например, динамика производства продукции. Но, нельзя говорить о корреляции (взаимосвязи) между выпуском продукции и временем и оценивать между ними тесноту связи.
- Направление связи:
- прямые;
- обратные.
В том случае, если при увеличении признака-фактора растет признак-результат, говорят о прямой корреляционной связи. Например, чем выше уровень алкоголизации общества, тем выше преступность, причем преступность специфичная («пьяная»).
Если при увеличении признака-причины уменьшается признак-результат, говорят об обратной корреляционной зависимости. Например, чем выше социальный контроль в обществе, тем ниже преступность.
- Форма связи:
- прямолинейные;
- криволинейные.
И прямые, и обратные связи могут быть прямолинейными и криволинейными. Математически прямолинейные связи могут быть описаны с помощью уравнения прямой:
y = а + вx,
где
| y | — признак-результат; |
| x | — признак-фактор. |
Криволинейные связи носят иной характер. Возрастание величины факторного признака оказывается неравномерное влияние на величину результирующего признака.
þ Например, связь преступлений с возрастом нарушителей. Вначале криминальная активность лиц растет прямо пропорционально увеличению возраста (приблизительно до 30 лет), а затем начинает снижаться. Математически такие связи описываются с помощью кривых (гиперболы, параболы).
19 вопрос
Для практического использования моделей регрессии большое значение имеет их адекватность, т.е. соответствие фактическим статистическим данным.
Анализ качества эмпирического уравнения парной и множественной линейной регрессииначинаютс построения эмпирического уравнения регрессии, которое является начальным этапом эконометрического анализа. Первое же, построенное по выборке, уравнение регрессии очень редко является удовлетворительным по тем или иным характеристикам. Поэтому следующей важнейшей оценкой является проверка качества уравнения регрессии. В эконометрике принята устоявшаяся схема такой проверки, которая проводится по следующим направлениям:
- проверка статистической значимости коэффициентов уравнения регрессии
- проверка общего качества уравнения регрессии
- проверка свойств данных, выполнимость которых предполагалась при оценивании уравнения (проверка выполнимости предпосылок МНК)
Прежде, чем проводить анализ качества уравнения регрессии, необходимо определить дисперсии и стандартные ошибки коэффициентов, а также интервальные оценки коэффициентов. Корреляционный и регрессионный анализ, как правило, проводится для ограниченной по объёму совокупности. Поэтому параметры уравнения регрессии (показатели регрессии и корреляции), коэффициент корреляции и коэффициент детерминации могут быть искажены действием случайных факторов. Чтобы проверить, на сколько эти показатели характерны для всей генеральной совокупности, не являются ли они результатом стечения случайных обстоятельств, необходимо проверить адекватность построенных статистических моделей.
При анализе адекватности уравнения регрессии (модели) исследуемому процессу, возможны следующие варианты:
1. Построенная модель на основе F-критерия Фишера в целом адекватна и все коэффициенты регрессии значимы. Такая модель может быть использована для принятия решений и осуществления прогнозов.
2. Модель по F-критерию Фишера адекватна, но часть коэффициентов не значима. Модель пригодна для принятия некоторых решений, но не для прогнозов.
3. Модель по F-критерию адекватна, но все коэффициенты регрессии не значимы. Модель полностью считается неадекватной. На ее основе не принимаются решения и не осуществляются прогнозы.
Проверить значимость (качество) уравнения регрессии–значит установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным, достаточно ли включенных в уравнение объясняющих переменных для описания зависимой переменной. Чтобы иметь общее суждение о качестве модели, по каждому наблюдению из относительных отклонений определяют среднюю ошибку аппроксимации. Проверка адекватности уравнения регрессии (модели) осуществляется с помощью средней ошибки аппроксимации, величина которой не должна превышать 10-12% (рекомендовано).
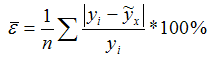
Оценка значимости уравнения регрессии в целом производится на основе F-критерия Фишера, которому предшествует дисперсионный анализ. В математической статистике дисперсионный анализ рассматривается как самостоятельный инструмент статистического анализа. В эконометрике он применяется как вспомогательное средство для изучения качества регрессионной модели. Согласно основной идее дисперсионного анализа, общая сумма квадратов отклонений переменной (y) от среднего значения (yср.) раскладывается на две части – «объясненную» и «необъясненную»:
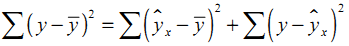
Схема дисперсионного анализа имеет следующий вид:

(n –число наблюдений, m–число параметров при переменной x)
Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду. Сопоставляя факторную и остаточную дисперсии в расчете на одну степень свободы, получим величину F-критерия Фишера. Фактическое значение F -критерия Фишера сравнивается с табличным значением Fтабл. (α, k1, k2) при заданном уровне значимости α и степенях свободы k1= m и k2=n-m-1. При этом, если фактическое значение F-критерия больше табличного Fфакт > Fтеор, то признается статистическая значимость уравнения в целом. Для парной линейной регрессии m=1, поэтому:
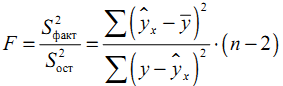
Эта формула в общем виде может выглядеть так:
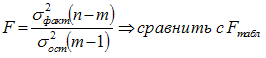
Отношение объясненной части дисперсии переменной (у) к общей дисперсии называют коэффициентом детерминации и используют для характеристики качества уравнения регрессии или соответствующей модели связи. Соотношение между объясненной и необъясненной частями общей дисперсии можно представить в альтернативном варианте:
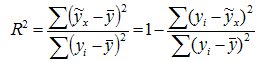
Коэффициент детерминации R2 принимает значения в диапазоне от нуля до единицы 0≤ R2 ≤1. Коэффициент детерминации R2показывает, какая часть дисперсии результативного признака (y) объяснена уравнением регрессии. Чем больше R2, тем большая часть дисперсии результативного признака (y) объясняется уравнением регрессии и тем лучше уравнение регрессии описывает исходные данные. При отсутствии зависимости между (у) и (x) коэффициент детерминации R2 будет близок к нулю. Таким образом, коэффициент детерминации R2 может применяться для оценки качества (точности) уравнения регрессии. Значение R-квадрата является индикатором степени подгонки модели к данным (значение R-квадрата близкое к 1.0 показывает, что модель объясняет почти всю изменчивость соответствующих переменных). Чтобы определить, при каких значениях R2 уравнение регрессии следует считать статистически не значимым, что, в свою очередь, делает необоснованным его использование в анализе, рассчитывается F-критерий Фишера: Fфакт > Fтеор - делаем вывод о статистической значимости уравнения регрессии. Величина F-критерия связана с коэффициентом детерминации R 2xy (r2xy) и ее можно рассчитать по следующей формуле:
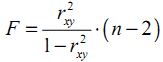 Либо при оценке значимости индекса детерминации (аналог коэффициента детерминации):
Либо при оценке значимости индекса детерминации (аналог коэффициента детерминации):
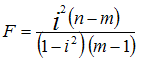 где: i2 - индекс (коэффициент) детерминации, который рассчитывается:
где: i2 - индекс (коэффициент) детерминации, который рассчитывается:
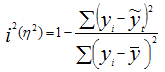
Использование коэффициента множественной детерминации R2 для оценки качества модели, обладает тем недостатком, что включение в модель нового фактора (даже несущественного) автоматически увеличивает величину R2. Поэтому, при большом количестве факторов, предпочтительнее использовать, так называемый, улучшенный, скорректированный коэффициент множественной детерминации R2, определяемый соотношением:
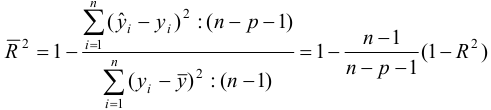
где p – число факторов в уравнении регрессии, n – число наблюдений. Чем больше величина p, тем сильнее различия между множественным коэффициентом детерминации R2и скорректированным R2. При использовании скорректированного R2, для оценки целесообразности включения фактора в уравнение регрессии, следует учитывать, что увеличение его величины (значения), при включении нового фактора, не обязательно свидетельствует о его значимости, так как значение увеличивается всегда, когда t-статистика больше единицы (|t|>1). При заданном объеме наблюдений и при прочих равных условиях, с увеличением числа независимых переменных (параметров), скорректированный коэффициент множественной детерминации убывает. При небольшом числе наблюдений, скорректированная величина коэффициента множественной детерминации R2 имеет тенденцию переоценивать долю вариации результативного признака, связанную с влиянием факторов, включенных в регрессионную модель. Низкое значение коэффициента множественной корреляции и коэффициента множественной детерминации R2 может быть обусловлено следующими причинами:
- в регрессионную модель не включены существенные факторы;
- неверно выбрана форма аналитической зависимости, которая нереально отражает соотношения между переменными, включенными в модель.
Следует также обратить внимание на важность анализа остатков (остаточной, “необъясненной” дисперсии). Остаток представляет собой отклонение фактического значения зависимой переменной от значения, полученного расчетным путем. При построении уравнения регрессии, мы можем разбить значение (у) в каждом наблюдении на 2 составляющие:
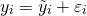
Отсюда:
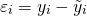
Если εi=0, то для всех наблюдений фактические значения зависимой переменной совпадают с расчетными (теоретическими) значениями. Графически это означает, что теоретическая линия регрессии (линия, построенная по функции у=а0+а1х) проходит через все точки корреляционного поля, что возможно только при строго функциональной связи. Следовательно, результативный признак (у) полностью обусловлен влиянием фактора (х). На практике, как правило, имеет место некоторое рассеивание точек корреляционного поля относительно теоретической линии регрессии, т.е. отклонения эмпирических данных от теоретических εi≠0. Величина этих отклонений и лежит в основе расчета показателей качества (адекватности) уравнения.
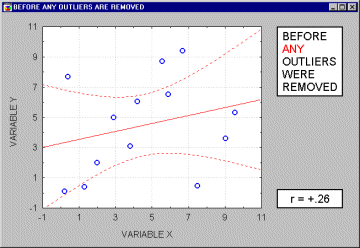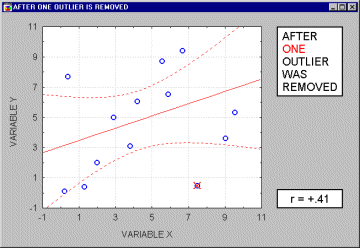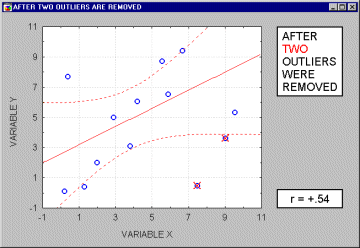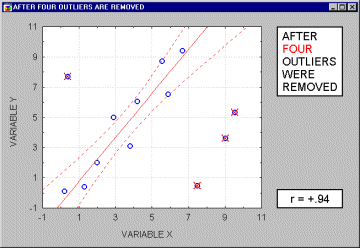
Большинство предположений множественной регрессии нельзя в точности проверить, однако можно обнаружить отклонения от этих предположений. В частности, выбросы (экстремальные наблюдения) могут вызвать серьезное смещение оценок, сдвигая линию регрессии в определенном направлении и, тем самым, вызывая смещение коэффициентов регрессии. Часто исключение всего одного экстремального наблюдения приводит к совершенно другому результату. Выбросы оказывают существенное влияние на угол наклона регрессионной линии и,соответственно, на коэффициент корреляции. Всего один выброс может полностью изменить наклон регрессионной линии и, следовательно, вид зависимости между переменными. Одна точка выброса обуславливает высокое значение коэффициента корреляции, в то время, как в отсутствие выброса, он практически равен нулю.
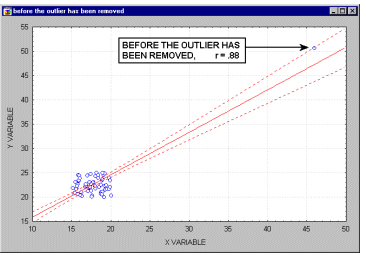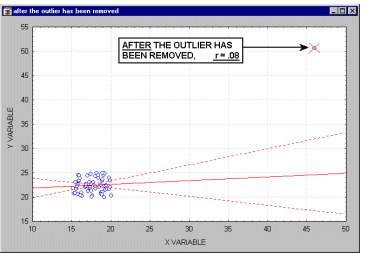
При численности объектов анализа до 30 единиц возникает необходимость проверки значимости (существенности) каждого коэффициента регрессии. При этом выясняют насколько вычисленные параметры характерны для отображения комплекса условий: не являются ли полученные значения параметров результатами действия случайных причин. Значимость коэффициентов простой линейной регрессии (применительно к совокупностям, у которых n<30) осуществляют с помощью t-критерия Стьюдента. При этом вычисляют расчетные (фактические) значения t-критерия для параметров a0 а1:
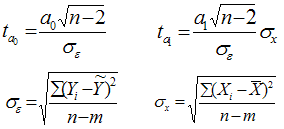
- n – число наблюдений, m-число параметров уравнения регрессии,
- σ ε - (остаточное) среднее квадратическое отклонение результативного признака от выровненных значений ŷ,
- σ х - среднее квадратическое отклонение факторного признака от общей средней.
Вычисленные, по вышеприведенным формулам, значения сравнивают с критическими t, которые определяют по таблице значений Стьюдента с учетом принятого уровня значимости (α) и числа степеней свободы вариации k (ν)=n-2. В социально-экономических исследованиях уровень значимости α обычно принимают равным 0,05. Параметр признается значимым (существенным) при условии, если tрасч. > tтабл . В этом случае, практически невероятно, что найденные значения параметров обусловлены только случайными совпадениями.
Для оценки значимости парного коэффициента корреляции (корень квадратный из коэффициента детерминации), при условии линейной формы связи между факторами, можно использовать t-критерий Стьюдента:
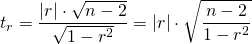
Анализ качества эмпирического уравнения множественной линейной регрессии предусматривает оценку мультиколлинеарности факторов. При оценке мультиколлинеарности факторов следует учитывать, что чем ближе к нулю определитель матрицы межфакторной корреляции, тем сильнее мультиколлинеарность факторов и ненадежнее результаты множественной регрессии. Для отбора наиболее значимых факторов Хi должны быть учтены следующие условия:
- связь между результативным признаком и факторным должна быть выше межфакторной связи
- связь между факторами должна быть не более 0.7
- при высокой межфакторной связи признака отбираются факторы с меньшимкоэффициентом корреляции между ними
Более объективную характеристику тесноты связи дают частные коэффициенты корреляции, измеряющие влияние на результативный фактор Уi фактора Хi при неизменном уровне других факторов. Коэффициент частной корреляции отличается от простого коэффициента линейной парной корреляции тем, что он измеряет парную корреляцию соответствующих признаков (У и Хi) при условии, что влияние на них остальных факторов (Хj) устранено.
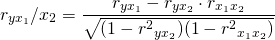
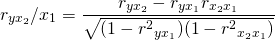
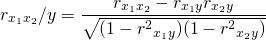
20 вопрос.
Основную информацию о численности населения дают переписи населения.
В промежутках между переписями определяют по следующей форме:
1) Численность населения на конец года. 2) Численность населения на начало года. 3) Число родившихся за год. 4) Число прибывших за год. 5) Число умерших. 6) Число выбывших.
Численность населения в населенных пунктах рассчитывается по 2ум категориям: постоянное и наличное.
Постоянно население - это лица, обычно проживающие в данном населенном пункте независимо от их местонахождение во время переписи.
Наличное население - это лица фактически находящиеся в данном населенном пункте на момент учета.
Среднегодовая численность населения рассчитывается как средний арифметический показатель численности населения на начало и конец года. /S = Sн + Sк/2 (/S – среднее число населения, Sн (Sк) число населения на начало (конец) года.
При наличие данных о численности населения на несколько равностоящих дат сред. годов /S определяется по формуле: /S =? * S1 + S2 + S3 + …. + Sn-1 + Sn *? / n – 1
21 вопрос.
Естественно движение населения – это изменение численности населения за счет рождения и смертности.
К основным показателям естественного движения населения относят: коэффициент (К) рождаемости, К смертности, К естественного прироста, К брака и развода.
Абсолютный показатель рождения и смертности не позволяет сравнивать эти величины в различных населенных пунктах, странах и т.д. поэтому эти показатели приводятся в расчете на 1 т.ч., т.е. выражаются в относительных величинах в промилях %.
К рожд = N/ /S * 1000 (N – число родившихся за год, /S – среднее число населения)
К смертности = M/ /S * 1000 (M – число умерших за год)
К естественного прироста = N – M / /S * 1000
Механическое движение – миграция населения.
Миграция бывает внутренняя и внешняя т.е. внутри страны и между странами.
Основным показателем мех. движения населения является К выбытия, выбытия населения и сальдо миграции.
К прибытия = П / /S * 1000 (П – число прибывших)
К выбытия = В / /S * 1000 (В – число выбывших)
К миграции (сальдо) = П – В / /S * 1000 = Кп – Кв
Перспектива численности населения определяется по формуле:
S н + t = Sн * (1 + К общего прироста / 1000)|t (| – степень (прим. автора))
22 вопрос
Баланс трудовых ресурсов – это система показателей, отражающих численность и состав трудовых ресурсов и их распределение на занятых по отраслям народного хозяйства, по формам собственности, безработных и экономически неактивного населения.
Баланс трудовых ресурсов составленный по стране в целом, краям, областям с разделением на городское и с/х население. По фактору времени баланс бывает отчетный и плановый.
В настоящее время баланс трудовых ресурсов составляют по среднегодовым данным и он состоит из 2х разделов: 1. имеющихся ресурсов; 2. распределяемых ресурсов.
Трудовые ресурсы – это лица которые потенциально могут участвовать в производстве товаров и услуг. Трудовые ресурсы включают экономически активное и не активное население.
Численность трудоспособного населения равна численности населения в трудоспособном возрасте (16 – 54, 59 лет), минус численность неработающих инвалидов 1ой, 2ой группы, минус число не работающих получивших пенсию по возрасту на льготных условиях + лица пенсионного возраста продолжающие трудится + лица моложе 16 лет занятые в экономике.
Баланс распределяет трудовые ресурсы по видам занятости и отраслям экономики:
Распределение отражает след. направления:
1. численность рабочих без совместителей; 2. число аппарата хозуправления; 3. число рабочих и служащих учитываемых в централизованном порядке; 4. число занятых совместных предприятий; 5. число занятых индивидуальной трудовой деятельности.
23 вопрос.
Трудовые ресурсы – это часть населения страны, которая по возрасту и состоянию здоровья фактически работает или способна к трудовой деятельности. Схему формирования трудовых ресурсов представим на рис.3.1.
Таким образом, в состав трудовых ресурсов включают:
· трудоспособное население в трудоспособном возрасте;
· фактически работающих подростков моложе 15 лет;
· фактически работающих пенсионеров.
Численность трудовых ресурсов рассчитывают двумя методами:
1. Демографический: население трудоспособного возраста за вычетом инвалидов I, II групп, включая работающих подростков и пенсионеров.
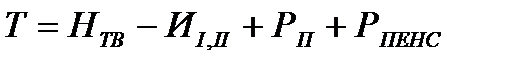
2. Экономический: фактически работающее население (занятое), включая занятых в личном, подсобном и фермерском хозяйствах, плюс учащиеся с отрывом от производства, безработные и остальные неработающие лица трудоспособного возраста.
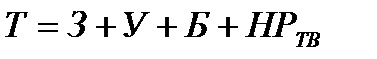
24 вопрос)))
|
|
|
|
|
Дата добавления: 2014-12-24; Просмотров: 1291; Нарушение авторских прав?; Мы поможем в написании вашей работы!