КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Основные понятия математической статистики 1 страница
|
|
|
|
МЕТОДИЧЕСКИЕ УКАЗАНИЯ К ИЗУЧЕНИЮ ДИСЦИПЛИНЫ
В математической статистике принято выделять два основных направления исследований: первое направление связано с оценкой неизвестных параметров, второе – с проверкой некоторых априорных предположений или статистических гипотез.
Основными понятиями математической статистики являются: генеральная совокупность, выборка, эмпирическая функция распределения.
Генеральная совокупность – это случайная величина или случайный вектор, заданный на вероятностном пространстве событий.
Исследование всех элементов генеральной совокупности невозможно и нецелесообразно, так как объём элементов очень велик, и обработка стоит большого труда. Поэтому из генеральной совокупности отбирают определённое количество элементов, которые называются выборкой, и производят их изучение. Элементы выборки называют вариантами.
Чтобы по данным выборки можно было судить об интересующем признаке генеральной совокупности, все объекты должны иметь одинаковую вероятность попадания в выборку, т.е. выборка должна быть репрезентативной. И тогда, в соответствии с законом больших чисел, результаты выборки будут близки к результатам, которые могут быть получены при наблюдении всех объектов генеральной совокупности.
Способ составления выборки может быть повторным, если один и тот же объект генеральной совокупности попадает под наблюдение более одного раза, в противном случае способ составления выборки называется бесповторным. Если объём выборки достаточно велик, то существенной разницы между бесповторной и повторной выборками нет.
Среди этих двух основных способов различают следующие способы составления выборки: механический, при котором объекты отбирают через определённый интервал (например, каждое десятое изделие с конвейера); простойслучайный, при котором объекты отбирают случайно (например, каждый объект заменяют жетоном с номером, жетоны перемешивают и случайным образом берут несколько штук, а затем по ним берут объекты); типический, при котором объекты генеральной совокупности разбивают на непересекающиеся группы, а из них случайным образом берут объекты; серийный, при котором объекты разбивают на непересекающиеся группы и берут случайным образом некоторые из групп. Типическим способом пользуются тогда, когда результат наблюдения заметно колеблется в различных типических группах генеральной совокупности. Серийным способом пользуются тогда, когда результат наблюдения колеблется незначительно в различных группах, и тогда наблюдению подвергаются все объекты случайно выбранной группы (серии).
Статистическая обработка выборки начинается с составления дискретного вариационного ряда (Таблица 3),
где 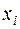 – варианта (ранжированные элементы выборки, т.е. выстроенные в порядке возрастания или убывания),
– варианта (ранжированные элементы выборки, т.е. выстроенные в порядке возрастания или убывания),
 - частота варианты (количество появления данного элемента в выборке),
- частота варианты (количество появления данного элемента в выборке),
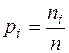 – относительная частота,
– относительная частота,
n – объём выборки.
Варианты могут быть записаны в виде точечных значений или в виде интервалов непрерывных значений. В первом случае вариационный ряд называется дискретным, во втором – интервальным. Эти ряды помогают выявить структуру изучаемого явления.
Для интервального вариационного ряда в первой строке (столбце) таблицы записываются интервалы изменения непрерывного признака , а во второй строке (столбце) – частоты попадания наблюдаемых значений признака в эти интервалы. Для интервала выбирают длину h, определяемую условиями задачи или рассчитывают по формуле Стерджесса:
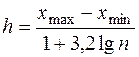 (1)
(1)
При этом значение признака, находящегося на границе интервалов относят к правой границе интервала.
На практике считают, что правильно составленный ряд распределения содержит от 6 до 15 частичных интервалов. Часто интервальный вариационный ряд заменяют дискретным вариационным рядом, выбирая средние значения интервала.
После составления вариационного ряда необходимо построить функцию распределения выборки или эмпирическую функцию F*(x), то есть функцию найденную по данным эксперимента.
Эмпирическое распределение можно изобразить в виде полигона, гистограммы или ступенчатой кривой.
Ступенчатая кривая. При известном статистическом распределении частот количественного признака Х, значение 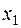 наблюдалось
наблюдалось 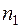 раз,
раз, 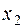 наблюдалось
наблюдалось 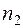 раз и т.д.
раз и т.д. 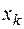 наблюдалось
наблюдалось 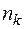 раз, общий объём выборки можно определить по формуле:
раз, общий объём выборки можно определить по формуле:
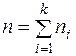 (2)
(2)
Число наблюдений называется эмпирической частотой, а значение его отношения к объёму выборки – относительной частотой:
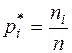 (3)
(3)
Если за 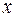 принять некоторое значение в табличном ряду, а за
принять некоторое значение в табличном ряду, а за 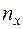 – число наблюдений, расположенных левее
– число наблюдений, расположенных левее  в том же табличном ряду, то эмпирической функцией распределения случайной величины называют функцию F*(x), определяющую для каждого значения x относительную частоту события X<x:
в том же табличном ряду, то эмпирической функцией распределения случайной величины называют функцию F*(x), определяющую для каждого значения x относительную частоту события X<x:
F*(x)= 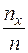 (4)
(4)
Таким образом, для того чтобы найти, например 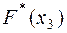 , надо число вариант, меньших
, надо число вариант, меньших 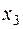 , разделить на объём выборки:
, разделить на объём выборки:
= 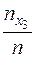 (5)
(5)
Эта функция служит приближённой оценкой теоретической функции распределения F(x) случайной величины Х.
Различие между эмпирической и теоретической функциями состоит в том, что теоретическая функция F(x) определяет вероятность события Х<х, а эмпирическая функция 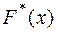 определяет относительную частоту этого же события. обладает всеми свойствами F(x), а именно:
определяет относительную частоту этого же события. обладает всеми свойствами F(x), а именно:
1) значения эмпирической функции принадлежат интервалу [0;1];
2) F*(x)- неубывающая функция;
3) если 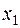 - наименьшее значение, - наибольшее, то F*(x)= 0 при
- наименьшее значение, - наибольшее, то F*(x)= 0 при 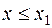 и F*(x)= 1 при x> .
и F*(x)= 1 при x> .
На рисунке 1 изображена функция распределения 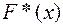 интервального вариационного ряда, результаты расчёта которой представлены в таблице №4.
интервального вариационного ряда, результаты расчёта которой представлены в таблице №4.
Полигон частот (или многоугольник распределения) – это ломаная, отрезки которой соединяют точки (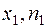 ), (
), (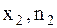 ), …(
), …(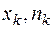 ). На оси абсцисс откладывают значения величины Х, на оси ординат – соответствующие им частоты или относительные частоты. Полученные точки соединяют (рисунок 2).
). На оси абсцисс откладывают значения величины Х, на оси ординат – соответствующие им частоты или относительные частоты. Полученные точки соединяют (рисунок 2).
В случае непрерывных случайных величин строится гистограмма частот или относительных частот. Это ступенчатая фигура, состоящая из прямоугольников, основаниями которых являются частичные интервалы длиной h, а высоты равны 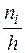 или
или 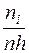 . Площадь под гистограммой равна сумме всех частот (относительных частот), т.е. объёму выборки (единице).
. Площадь под гистограммой равна сумме всех частот (относительных частот), т.е. объёму выборки (единице).
Графическое изображение вариационных рядов в виде полигона и гистограммы позволяет получать первоначальное представление о закономерностях, имеющих место в совокупности наблюдений.
На основании полученных выборочных данных необходимо сделать предположение, что изучаемая величина распределена по некоторому определённому закону. Для того чтобы проверить, согласуется ли это предположение с данными наблюдений, вычисляют частоты наблюдаемых значений, т.е. находят теоретически сколько раз величина Х должна была принять каждое из наблюдаемых значений, если она распределена по предполагаемому закону. Для этого находят выравнивающие (теоретические) частоты по формуле:
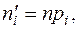 (6)
(6)
где n – число испытаний,
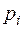 - вероятность наблюдаемого значения , вычисленная при допущении, что Х имеет предполагаемое распределение.
- вероятность наблюдаемого значения , вычисленная при допущении, что Х имеет предполагаемое распределение.
В случае непрерывного распределения весь интервал возможных значений делят на k непересекающихся интервалов и вычисляют вероятности попадания Х в i -й частичный интервал, а затем, как и для дискретного распределения, умножают число испытаний на эти вероятности (6).
Эмпирические и выравнивающие частоты сравнивают, и при небольшом расхождении данных, делают заключение о выбранном законе распределения.
Статистические оценки и их свойства
Статистической оценкой неизвестного параметра называется функция от наблюдаемых случайных величин.
Пусть 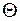 – оцениваемый параметр закона распределения случайной величины Х;
– оцениваемый параметр закона распределения случайной величины Х; 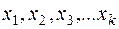 – наблюдаемые значения случайной величины в n опытах,
– наблюдаемые значения случайной величины в n опытах, 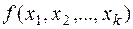 - статистика. Её значение до опыта есть случайная величина, а после опыта – некоторое число. Задача точечного оценивания подобрать такую статистику , что
- статистика. Её значение до опыта есть случайная величина, а после опыта – некоторое число. Задача точечного оценивания подобрать такую статистику , что 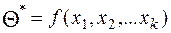 - точечная оценка параметра , т.е. его приближённое значение. Это случайная величина и её возможные значения изменяются при переходе от одной выборки к другой. Математическое ожидание случайной величины
- точечная оценка параметра , т.е. его приближённое значение. Это случайная величина и её возможные значения изменяются при переходе от одной выборки к другой. Математическое ожидание случайной величины 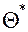 может совпасть или не совпасть с оцениваемым параметром .
может совпасть или не совпасть с оцениваемым параметром .
Если М()= , то называется несмещённой оценкой, в противном случае – смещённой. Несмещённость оценки говорит о том, что отклоняется от в обе стороны одинаково и отклонения компенсируют друг друга.
Оценка может иметь большой или небольшой разброс (дисперсию) относительно математического ожидания.
Если несмещённая оценка имеет наименьшую дисперсию при одних и тех же объёмах выборки, то она называется эффективной.
При большом объёме выборки наряду с требованием несмещённости и эффективности, к оценке предъявляют требование состоятельности. Оценка называется состоятельной, если вероятность сколь угодно малого отклонения оценки от оцениваемого параметра сколь угодно близка к единице:
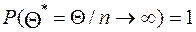 (7)
(7)
После извлечения из генеральной совокупности выборки объёма n рассчитывают основные числовые характеристики выборки: 
Выборочные средние
При статистической обработке материала необходимо учитывать особенности изучаемых явлений, для изучения которых требуются различные средние. Математическая статистика выводит различные средние из формул степенной средней:
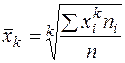 . (8)
. (8)
Вопрос о том, какой вид средней необходимо применить, решается путём конкретного анализа изучаемой совокупности, определяется материальным содержанием изучаемого явления, а также исходя из принципа осмысленности результатов при суммировании.
Средняя арифметическая: Это величина (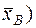 , определяемая как среднее арифметическое значение выборки:
, определяемая как среднее арифметическое значение выборки:
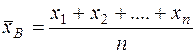
или 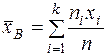 , (9)
, (9)
где - частоты,
а 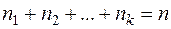 -объём выборки.
-объём выборки.
Она исчисляется в тех случаях, когда объём усредняемого признака, образуется как сумма его значений у отдельных единиц изучаемой статистической совокупности.
Средняя гармоническая:
 (10)
(10)
Эта величина применяется, когда статистическая информация не содержит частот по отдельным вариантам совокупности, а представлена как их произведение, т.е. произведения по каждому признаку равны.
Средняя квадратическая:
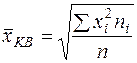 (11)
(11)
Средняя геометрическая:
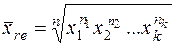 (12)
(12)
Этой средней удобно пользоваться, когда уделяется внимание не абсолютным разностям, а отношениям двух чисел, т.е. индивидуальные значения признака – относительные величины. Она используется в расчётах среднегодовых темпов роста, а также для определения равноудалённой величины от максимального и минимального значений признака.
Необходимо заметить, что разные виды средних величин при одном и том же исходном материале имеют неодинаковое значение:
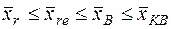 (13)
(13)
Эти неравенства называются мажорантностью средних.
Для характеристики структуры совокупности применяются особые показатели, которые называются структурными средними. К ним относятся мода и медиана.
Выборочная мода (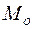 ) - это варианта, имеющая наибольшую частоту или то значение признака, которое соответствует максимальной точке теоретической кривой распределения.
) - это варианта, имеющая наибольшую частоту или то значение признака, которое соответствует максимальной точке теоретической кривой распределения.
Выборочная медиана (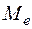 ) – это варианта, которая делит вариационный ряд на две части, равные по числу вариант. Если число вариант нечётное, т.е.
) – это варианта, которая делит вариационный ряд на две части, равные по числу вариант. Если число вариант нечётное, т.е. 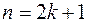 , то
, то 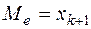 ; при чётном
; при чётном 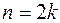 ,
, 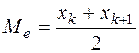 .
.
Если 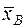 , , совпадают, то данное распределение симметрично.
, , совпадают, то данное распределение симметрично.
Различие индивидуальных значений признака внутри изучаемой совокупности в статистике называют вариацией признака, которую характеризуют следующие показатели:
Выборочная дисперсия (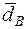 ) - это среднее арифметическое квадратов отклонений наблюдаемых значений от выборочного среднего:
) - это среднее арифметическое квадратов отклонений наблюдаемых значений от выборочного среднего:
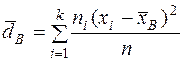 (14)
(14)
Мерой надёжности средней является выборочное среднее квадратическое отклонение (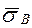 ).
).
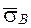 =
= 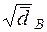 (15)
(15)
Чем меньше , тем лучше 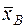 отражает собой всю представленную совокупность.
отражает собой всю представленную совокупность.
Коэффициент вариации (V) - это выраженное в процентах отношение выборочного среднего квадратического отклонения к выборочной средней. Он служит для сравнения величин рассеяния двух вариационных рядов. Ряд, у которого коэффициент вариации больше, имеет большее рассеяние:
V = 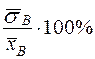 (16)
(16)
Если V>33%, то имеет место большая колеблемость изучаемого признака.
Для характеристики колеблемости признака используется ряд показателей. Наиболее простой - размах варьирования (R). Это разность между наибольшей и наименьшей вариантами:
R = 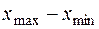 (17)
(17)
Чтобы дать обобщающую характеристику распределению отклонений, исчисляют среднее абсолютное отклонение (). Это среднее арифметическое абсолютных отклонений:
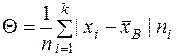 (18)
(18)
служит для характеристики рассеяния вариационного ряда и учитывает различия всех единиц изучаемой совокупности.
Величины 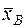 , , имеют такие же свойства как M[ x ], D[ x ], σ[ x ].
, , имеют такие же свойства как M[ x ], D[ x ], σ[ x ].
Выборочная средняя является несмещённой состоятельной оценкой для М[ x ], а в случае нормального закона – эффективной. Выборочная дисперсия - смещённая оценка для D[ x ]; - смещённая оценка для σ[x].
Для устранения смещённости выборочной дисперсии и среднего квадратического отклонения их умножают на дроби 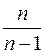 и
и 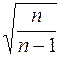 соответственно. В результате «исправленная» дисперсия и «исправленное» среднее квадратическое отклонение соответственно равны:
соответственно. В результате «исправленная» дисперсия и «исправленное» среднее квадратическое отклонение соответственно равны:
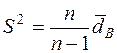 и
и 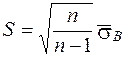 (19)
(19)
Оценки , , 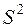 , S являются состоятельными, но не эффективными.
, S являются состоятельными, но не эффективными.
Все оценки, рассмотренные выше – точечные. Они выражаются одним числом. При выборке малого объёма точечная оценка может значительно отличаться от оцениваемого параметра, то есть могут возникнуть грубые ошибки.
Задача интервального оценивания состоит в том, чтобы по данным выборки найти такой интервал, который с заданной вероятностью покрывает оцениваемый параметр.
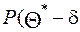 < <
< < 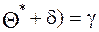 (20)
(20)
Заданную вероятность 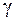 называют надёжностью (доверительной вероятностью). Она задаётся наперёд, причём в качестве берут число, близкое к единице (0,95;0,99;0,999), а точность
называют надёжностью (доверительной вероятностью). Она задаётся наперёд, причём в качестве берут число, близкое к единице (0,95;0,99;0,999), а точность 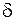 берут равной 0,1; 0,01; 0,001, в зависимости от задачи.
берут равной 0,1; 0,01; 0,001, в зависимости от задачи.
Интервал (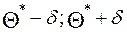 ) называют доверительным. Именно он покрывает неизвестный параметр с заданной надёжностью .
) называют доверительным. Именно он покрывает неизвестный параметр с заданной надёжностью .
Пусть генеральная совокупность распределена по нормальному закону, причём известно. Требуется построить доверительный интервал для математического ожидания. В качестве точечной оценки параметров нормального закона возьмём 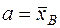 ,
, 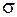 =
= 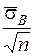 .
.
Вероятность заданного отклонения вычисляется по формуле:
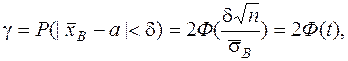
где t = 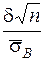 ,
, 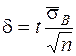 и тогда
и тогда
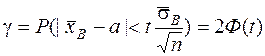 или
или
P( - t 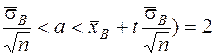 Ф(t)= (21)
Ф(t)= (21)
Для заданного по таблице функции Лапласа (Приложение 4) определяют квантиль t для функции Ф(t).
Квантилью, или левосторонней критической областью, отвечающей вероятности 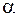 , называется такая граница, левее которой вероятность равна . Квантиль обозначается
, называется такая граница, левее которой вероятность равна . Квантиль обозначается 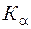 по определению
по определению 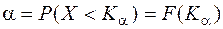 , т.е. квантиль является решением уравнения
, т.е. квантиль является решением уравнения 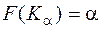 .
.
Доверительный интервал для оценки среднего квадратического отклонения случайной величины Х с надёжностью для нормального закона распределения случайной величины находится из неравенств [1]:
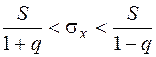 , (22)
, (22)
где S – несмещённое значение выборочного среднего квадратичного отклонения;
q – параметр, который находится по таблице (Приложение 5) на основе известного объёма выборки n и заданной надёжности оценки .
С помощью рядов распределения решается важнейшая задача статистики – характеристика закономерностей и изменение показателей колеблемости для варьирующих признаков. Определение формы кривой распределения является важной задачей, так как обрабатываемый материал даёт по определённому признаку характерную, типичную для него кривую. Всякое искажение формы кривой означает нарушение или изменение нормальных условий возникновения материала.
Для характеристики распределений используются моменты распределения. Это средние величины отклонений определённой степени от какого-либо числа. Если это средние арифметические, то моменты называются центральными. Если отклонения отсчитываются от произвольно выбранного начала, то они называются условными. Если же это число равно 0, то моменты распределения называются начальными.
Центральный эмпирический момент k -го порядка случайной величины Х вычисляется по формуле:
 (23)
(23)
Наиболее точным и распространённым показателем является асимметрия (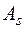 ). Это отношение центрального эмпирического момента третьего порядка к кубу среднего квадратического отклонения. Она характеризует несимметричность распределения случайной величины.
). Это отношение центрального эмпирического момента третьего порядка к кубу среднего квадратического отклонения. Она характеризует несимметричность распределения случайной величины.
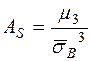 (24)
(24)
Асимметрия положительна, если «длинная часть» кривой распределения расположена справа от математического ожидания и отрицательна, если «длинная часть» кривой расположена слева от математического ожидания.
Оценка степени существенности этого показателя даётся с помощью средней квадратической ошибки, которая зависит от объёма наблюдений n и рассчитывается по формуле:
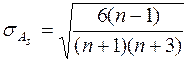 (25)
(25)
если отношение 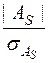 >3, то асимметрия существенна, а если <3, то её наличие может быть объяснено влиянием различных обстоятельств.
>3, то асимметрия существенна, а если <3, то её наличие может быть объяснено влиянием различных обстоятельств.
Для оценки «крутости», то есть большего или меньшего подъёма кривой распределения по сравнению с нормальной кривой, пользуются другой характеристикой - эксцессом.
Эксцесс эмпирического распределения (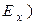 – это величина, которая определяется по формуле:
– это величина, которая определяется по формуле:
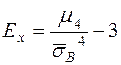 (26)
(26)
Если эксцесс положительный, то кривая имеет более высокую и острую вершину, чем нормальная кривая; если эксцесс отрицательный, то сравниваемая кривая имеет более низкую и плоскую вершину, чем нормальная кривая (при равенстве математических ожиданий). Если асимметрия и эксцесс имеют небольшие значения, то предполагается близость этого распределения к нормальному.
Проверка статистической гипотезы о нормальном распределении
Наряду с задачами оценивания параметров большую группу задач математической статистики составляют задачи проверки статистических гипотез.
Статистической гипотезой называется предположение относительно генеральной совокупности, проверяемое по выборочным данным. Процесс принятия решения называется проверкой статистической гипотезы. Поскольку выдвигаемая гипотеза опирается только на случайные выборочные значения, то и выводы будут носить вероятностный характер. Поэтому можно с заданной вероятностью утверждать, что гипотеза справедлива или нет.
|
|
|
|
|
Дата добавления: 2015-04-24; Просмотров: 1029; Нарушение авторских прав?; Мы поможем в написании вашей работы!