КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Кодирование и формат представления символьной информации
|
|
|
|
Кодирование информации – процесс формирования определенного представления информации. В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки. Обратное преобразование называется декодированием. Способ кодирования зависит от цели, ради которой оно осуществляется: сокращение записи, засекречивание (шифровка) информации, удобство обработки и т. д. Полный набор символов, используемый для кодирования текста, называется алфавитом или азбукой.
Кодирование текстовых данных. Компьютер может обрабатывать информацию, представленную только в числовой форме. Вся другая информация должна быть преобразована в числовую форму. Например, текст в книге состоит из букв и других символов. Буква – это элементарная часть текстовой информации. Информация называется закодированной, если любая ее элементарная часть представлена в виде числа. Такие числа называются кодами. Текст можно закодировать, если каждую букву заменить кодом, например, номером буквы в алфавите.
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы.
Технически это выглядит очень просто, однако всегда существовали достаточно веские организационные сложности. В первые годы развития вычислительной техники они были связаны с отсутствием необходимых стандартов, а в настоящее время вызваны, наоборот, изобилием одновременно действующих и противоречивых стандартов. Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, а это пока невозможно из-за противоречий между символами национальных алфавитов, а также противоречий корпоративного характера.
Для английского языка, захватившего де-факто нишу международного средства общения, противоречия уже сняты. Институт стандартизации США (ANSI — American National Standard Institute) ввел в действие систему кодирования ASCII (American Standard Code for Information Interchange — стандартный код информационного обмена США). В системе ASCII закреплены две таблицы кодирования — базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (в первую очередь производителям компьютеров и печатающих устройств). В этой области размещаются так называемые управляющие коды, которым не соответствуют никакие символы языков, и, соответственно, эти коды не выводятся ни на экран, ни на устройства печати, но ими можно управлять тем, как производится вывод прочих данных.
Начиная с кода 32 по код 127 размещены коды символов английского алфавита, знаков препинания, цифр, арифметических действий и некоторых вспомогательных символов. Для того чтобы закодировать буквы английского алфавита, нужно 52 числа (26 больших и 26 маленьких). Для букв русского алфавита нужно 33 заглавных буквы +33 прописных буквы = 66 чисел. А для кодирования десятичных чисел еще 10. Базовая таблица кодировки ASCII представлена в таблице 2.4.
Таблица 2.4 – Базовая таблица кодировки ASCII
| 32 пробел | 48 0 | 64 @ | 80 Р | 112 p | |
| 33! | 49 1 | 65 А | 81 Q | 97 а | 113 q |
| 50 2 | 66 В | 82 R | 98 b | 114 r | |
| 35 # | 51 3 | 67 С | 83 S | 99 с | 115 s |
| 36 $ | 52 4 | 68 D | 84 Т | 100 d | 116 t |
| 37 % | 53 5 | 69 Е | 85 U | 101 е | 117 u |
| 38 & | 54 6 | 70 F | 86 V | 102 f | 118 v |
| 55 7 | 71 G | 87 W | 103 g | 119 w | |
| 40 ( | 56 8 | 72 Н | 88 X | 104 h | 120 x |
| 41) | 57 9 | 73 I | 89 Y | 105 i | 121 у |
| 58: | 74 J | 90 Z | 106 j | 122 z | |
| 43 + | 59; | 75 К | 91 [ | 107 k | 123 { |
| 60 < | 76 L | 92 \ | 108 I | 124 | | |
| 77 М | 93 ] | 109 m | 125 } | ||
| 62 > | 78 N | 110 n | |||
| 47 / | 63? | 79 0 | 111 0 |
Аналогичные системы кодирования текстовых данных были разработаны и в других странах. Так, например, в СССР в этой области действовала система кодирования КОИ-7 (код обмена информацией, семизначный). Однако поддержка производителей оборудования и программ вывела американский код ASCII на уровень международного стандарта, и национальным системам кодирования пришлось «отступить» во вторую, расширенную часть системы кодирования, определяющую значения кодов со 128 по 255. Отсутствие единого стандарта в этой области привело к множественности одновременно действующих кодировок. Только в России можно указать три действующих стандарта кодировки и еще два устаревших (кодировка ГОСТ и кодировка ГОСТ - альтернативная ).
Кодировка символов русского языка, известная как кодировка Windows-1251, была введена «извне» — компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение. Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows. (смотри таблицу 2.5).
Таблица 2.5 – Кодировка Windows 1251

Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) — ее происхождение относится к временам действия Совета Экономической Взаимопомощи государств Восточной Европы. Сегодня кодировка КОИ–8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернета.
Международный стандарт, в котором предусмотрена кодировка символов русского алфавита, носит название кодировки ISO (International Standard Organization — Международный институт стандартизации). На практике данная кодировка используется редко. В связи с изобилием систем кодирования текстовых данных, действующих в России, возникает задача межсистемного преобразования данных – это одна из распространенных задач информатики.
Универсальная система кодирования текстовых данных. Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной — UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65536 различных символов — этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
Несмотря на тривиальную очевидность такого подхода, простой механический переход на данную систему долгое время сдерживался из-за недостаточных ресурсов средств вычислительной техники (в системе кодирования UNICODE все текстовые документы автоматически становятся вдвое длиннее). Для индивидуальных пользователей это еще больше добавило забот о согласовании документов, выполненных в разных системах кодирования, с программными средствами, но это надо понимать как трудности переходного периода.
Один байт – это не только единица информации, это элементарная ячейка памяти. Память компьютера состоит из последовательности таких ячеек. Каждая ячейка (байт) содержит двоичный код, который хранится в ней. Каждый разряд двоичного числа представляется физическим элементом, обладающим двумя устойчивыми состояниями, одному из которых приписывается значение 0, а другому - 1. Совокупность определенного количества этих элементов служит для представления многоразрядных чисел и составляет разрядную сетку. В компьютерах кодируемая информация записывается в разрядную сетку.
Рассмотрим восьмиразрядную сетку:
Символьная информация представляет собой последовательность знаков, представленных в коде. Например,
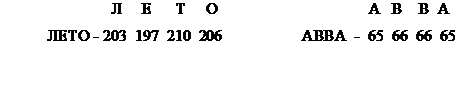
Чтобы записать символьную информацию в разрядную сетку компьютера, ее надо закодировать, затем код каждого символа перевести в двоичную систему счисления.
Пример 29. Закодируем слово «ЛЕТО»: переведем в двоичную систему и запишем в разрядную сетку.
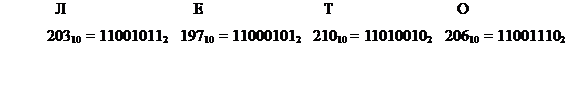
Запись символьной информации:
| Л | Е | ||||||||||||||
| Т | О | ||||||||||||||
|
|
|
|
|
Дата добавления: 2015-04-25; Просмотров: 2462; Нарушение авторских прав?; Мы поможем в написании вашей работы!