КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Другие методологические принципы анализа социологических данных
|
|
|
|
Выше мы сформулировали два основных методологических принципа, соблюдение которых является необходимым для того, чтобы использование математики было эффективным: сопряжение формализма и содержания и органическая связь всех этапов исследования друг с другом. Можно было бы говорить еще о целом ряде подобных требований, носящих более частный характер: необходимость выполнения некоторых принципов измерения интересующих социолога показателей; обеспечения определенной однородности той совокупности объектов, на которой "действует" наша предполагаемая закономерность; соблюдения некоторых принципов интерпретации результатов применения метода; выполнения определенных правил комплексного использования целой серии методов при решении практически любой социологической задачи и т.д. (некоторая "сводка" подобных принципов дана нами в [Толстова, 1991а, б]).
Раскрытие каждого из названных принципов требует серьезного рассмотрения. Все они многоаспектны, имеют сложную структуру. Их практическая реализация требует достаточно глубокого анализа концептуальных представлений социолога об изучаемом явлении, для чего требуется четкая формулировка самих этих представлений.
Так, говоря об измерении, мы должны давать себе отчет в том, какие именно элементы реальности собираемся отобразить в тех или иных математических конструктах (чаще всего - в числах); какова наша модель восприятия респондентом предлагаемых ему объектов (суждений и т.п.); какая именно интерпретация этих конструктов будет нами использоваться при их анализе и т.д. [Толстова, 1998]
Обеспечивая однородность подвергаемой анализу совокупности данных о наших объектах, необходимо задуматься о том, имеем ли мы право для всех интересующих нас респондентов использовать один и тот же инструмент измерения и одинаковым образом интерпретировать результаты последнего; можем ли мы считать, что формальный вид искомой закономерности должен быть одним и тем же для всей выборки; можем ли мы одинаковым способом интерпретировать результаты анализа и т.д. [Толстова, 1986, 1991а].
Интерпретируя результаты применения того или иного алгоритма анализа мы должны обеспечивать, чтобы эта интерпретация не противоречила интерпретации исходных данных; чтобы при ее осуществлении по возможности компенсировались бы те недостатки формализма, которые волей-неволей мы вынуждены были игнорировать при измерении и выборе метода анализа ("идеальная" формализация того, что интересует социолога, как правило, бывает невозможна) и т.д. [Интерпретация и анализ …. Гл. 1; Толстова, 1991а]
Продумывая вопрос об адекватности тех или иных методов измерения и анализа данных, понимая, что все они не в полной мере отражают то, что нужно социологу, последний часто приходит (или должен приходить) к выводу о том, что достаточно полное отражение интересующей его картины реальности требует комплексного использования разных методов. За каждым - свои плюсы и минусы. А будучи примененными в комплексе друг с другом, они могут дать вполне адекватное представление о действительности. Но здесь встает множество вопросов, связанных с глубоким анализом модели, заложенной в каждом методе, с разработкой принципов сравнения разных методов друг с другом и т.д. [Толстова, 1991а]
Полагаем, что сказанного достаточно для того, чтобы читателю стало ясно, почему (и в каком смысле) в заглавии нашей книги мы "привязываем" анализ данных именно к социологии.
* * *
Итак, мы в самых общих чертах описали, что такое "анализ социологических данных". При этом мы не только активно использовали то, что о соответствующих вопросах говорится в литературе, но и изложили свое видение ряда положений. Последнее в особой степени касается роли термина "социологический" в интересующем нас словосочетании.
Выше коротко раскрыта роль методов анализа данных в социологии и рассмотрены основные методологические принципы их использования при изучении общественных процессов. Конечно, все изложенное раскрывает суть анализа социологических данных действительно лишь "в самых общих чертах". Поэтому, вероятно, не все сказанное выше стало читателю полностью понятно; отдельные положения, может быть, показались очевидными либо, напротив, слишком "заумными", оторванными от реальности.
Наше убеждение состоит в том, что все приведенные соображения имеют самое непосредственное отношение к практике, к обеспечению хорошего научного уровня любого эмпирического социологического исследования. И каждое сформулированное выше утверждение становится весьма нетривиальным, когда дело доходит до его воплощения в жизнь. Но показать это, равно как и разъяснить более подробно то, что, возможно, осталось неясным читателю, можно только на реальных примерах. Необходимы: рассмотрение реальных социологических задач; демонстрация того, как их решению может способствовать математический аппарат; подробный анализ процесса сопряжения каждого метода с концептуальными представлениями исследователя и т.д. В определенной мере об этом пойдет речь во второй части (особый упор будет сделан на анализ моделей, заложенных в рассматриваемых методах).
9. Одномерные частотные распределения. Представление одномерной случайной величины в выборочном социологическом исследовании. Стоящие за ним модели.
Итак, в выборочном социологическом исследовании случайная величина предстает перед социологом в виде признака, для каждого значения которого (а таких значений – конечное количество) известна относительная частота его встречаемости. Эта частота интерпретируется как выборочная оценка соответствующей вероятности (вопрос о правомерности такой трактовки не прост; здесь мы его не рассматриваем; см. п.4.1 части I). Совокупность частот встречаемости всех значений признака, соответственно, трактуется как выборочное представление функции плотности того распределения вероятностей, которое и задает изучаемую случайную величину. Подчеркнем, что пока речь идет об одномерной случайной величине (ниже, переходя к оценке вероятностей встречаемости сочетаний значений разных признаков, мы тем самым перейдем к многомерным случайным величинам).
Пусть, например, вопрос в используемой социологом анкете звучит: “Какова Ваша профессия?” и сопровождается 5-ю вариантами ответов, закодированных числами от 1 до 5. Тогда частотное распределение - аналог функции плотности - будет иметь, например, вид:
Таблица 1.
Пример одномерной частотной таблицы
| Значение признака | |||||
| Частота встречаемости (%) |
Вместо процентов могут фигурировать доли: 20% заменится на 0,2, 15 - на 0,15 и т.д. (в случае такой замены мы получим числа, конечно, в большей степени похожие на вероятности, поскольку величина вероятности, как известно, изменяется от 0 до 1).
То же частотное распределение можно выразить по-другому, в виде диаграммы вида, отраженного на рис. 1 или в виде т.н. полигона распределения, рис.2.
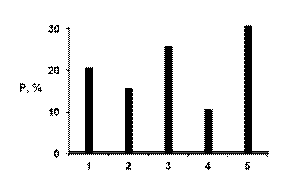
Рис.1. Диаграмма распределения, рассчитанная на основе таблицы 1.
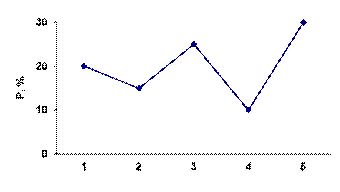
Рис. 2. Полигон распределения, рассчитанный на основе таблицы 1.
Подчеркнем, что здесь линии, связывающие отдельные точки, проведены лишь для наглядности, никакой содержательный смысл за ними не стоит (обращаем внимание читателя на то, что ниже ситуация изменится; здесь нельзя говорить об интерпретации линий из-за того, что признак – номинальный).
Казалось бы, что построение частотной таблицы или полигона распределения – дело простое, и говорить не о чем. Однако в социологии это не так. Рассмотрим проблемы, которые возникают при построении одномерных частотных таблиц. Будем учитывать тип шкалы, по которой получаются значения признака, рассмотрим номинальные, порядковые, интервальные шкалы. Однако прежде сделаем некоторое отступление для объяснения того, почему, обосновав во Введении целесообразность ограничиться номинальными данными, мы как будто отступаем от собственных принципов, переходя к шкалам более высокого типа. Дело в том, что продолжая считать номинальные данные основным объектов нашего изучения, мы не можем полностью отвлечься от других шкал. Причин тому несколько.
Во-первых, соответствующие положения фактически задействованы (иногда в неявном виде) почти во всех методах анализа, в том числе и рассчитанных на номинальные данные.
Во-вторых, хотя номинальные данные являются основным предметом изучения социолога, решение большинства задач эмпирической социологии требует “увязки” процесса такого изучения с анализом данных, полученных по шкалам высоких типов. Объясняется это тем, что именно по таким шкалам измеряются столь важные для социолога характеристики респондентов, как возраст респондента, его зарплата и т.д. Поэтому строить курс анализа данных вообще без упоминания методов изучения “числовой” информации представляется нецелесообразным.
В-третьих, хотя в литературе имеется немало работ с описанием методов статистического анализа “числовых” данных, однако при этом не всегда достаточно подробно анализируются многие их аспекты, важные для социолога-практика (например, редко затрагивается проблема разбиения диапазона изменения признака на интервалы или проблема пропущенных значений). Мы постараемся ликвидировать этот пробел хотя бы для наиболее часто используемых социологом методов – вычислении мер средней тенденции и разброса для вероятностных распределений.
Именно с “числовых” шкал мы и начнем более подробное обсуждение специфики построения распределений в социологических задачах. Приводимые ниже рассуждения справедливы для интервальныхшкал и шкал более высоких типов.
В социологической практике интервальность шкалы обычно сопрягается с ее непрерывностью, т.е. с предположением о том, что в качестве значения интервального признака в принципе может выступить любое действительное число, любая точка числовой оси.
Переходя к описанию выборочного представления функции распределения или функции плотности распределения, прежде всего отметим, что непрерывную кривую в выборочном исследовании нельзя получить никогда. Здесь мы не можем иметь, скажем, линию, похожую на известный “колокол” нормального распределения. Причина ясна: наша выборка конечна. Даже если в генеральной совокупности распределение, к примеру, нормально, а выборка - репрезентативна, мы вместо “колокола” получим лишь некоторое его подобие, составленное, например, из отрезков, соединяющих отдельные точки - полигон распределения (рис. 3). Заменяющая непрерывное распределение ломаная линия может состоять также из “ступенек”, в таком случае она называется гистограммой распределения (рис. 4).
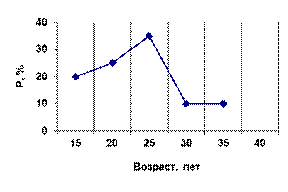
Рис 3. Полигон плотности распределения непрерывного признака
От середин отрезков, отложенных на горизонтальной оси, откладываются, соответственно, 20%, 25%, 35%, 10%, 10%
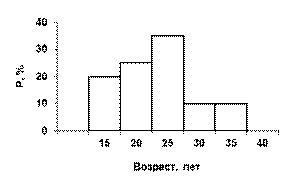
Рис. 4. Гистограмма плотности распределения непрерывного признака
 В математической статистике доказано, что при больших объемах выборки и достаточно мелком разбиении и гистограмма, и полигон достаточно хорошо приближают функцию плотности распределения (причем полигон делает это несколько лучше) [Ивченко, Медведев, 1992. С.24] (см. также [Тюрин, 1978.С. 8-10; Тюрин, Макаров, 1998. С. 40-41, 319].
В математической статистике доказано, что при больших объемах выборки и достаточно мелком разбиении и гистограмма, и полигон достаточно хорошо приближают функцию плотности распределения (причем полигон делает это несколько лучше) [Ивченко, Медведев, 1992. С.24] (см. также [Тюрин, 1978.С. 8-10; Тюрин, Макаров, 1998. С. 40-41, 319].
К подробному рассмотрению принципов построения таких “приблизительных” кривых плотностей распределения мы еще вернемся, а пока остановим свое внимание на ситуациях, когда речь идет не о невозможности, а о нецелесообразности стремления к непрерывной кривой.
Для примера рассмотрим признак “возраст респондента”. С одной стороны, без него не обходится практически ни один социолог (вряд ли можно представить себе социологическую задачу, которую имеет смысл решать без учета возраста тех людей, мнения которых изучаются), а, с другой, - на его примере легко демонстрировать некоторые принципиальные положения.
Интересующая нас проблема касается понимания того, чем является та закономерность, которая ищется с помощью того или иного метода анализа данных. Коротко мы же касались этого вопроса в первой части (п.1.4). Продолжим здесь соответствующие рассуждения. Дело в том, что само понятие закономерности предполагает достаточно простую структуру того, что мы закономерностью называем. Слишком дробное описание ситуации мы в силу ограниченности своего мышления (имеется в виду мышление не отдельного человека, а человека вообще) не будем воспринимать как найденную закономерность, как что-то, помогающее нам осмыслить происходящее. Например, мы, всего вероятнее, будем воспринимать сведения о величинах наблюдаемых долей людей с тем или иным возрастом, выраженные в виде изображенного на рис. 5 фрагмента полигона распределения, как некий бессмысленный набор чисел. А вот если мы сгруппируем соответствующие наблюдения и приведем этот фрагмент к другому виду - виду, изображенному на рис. 6, то нам наверняка станет ясно, что изучаемая совокупность респондентов характеризуется тем, что половину ее составляют люди моложе 20 лет, а людей от 25 до 30 лет в ней вдвое меньше и т.д. Из таких фактов вполне можно сделать содержательные выводы (зависящие, конечно, от того, какую задачу мы решаем). Картину, изображенную на рис. 6, можно назвать закономерностью – пусть весьма примитивной, но
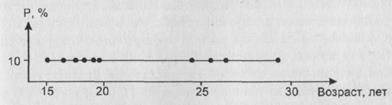
Рис.5. Полигон распределения по возрасту
При его построении использовались все наблюденные значения возраста
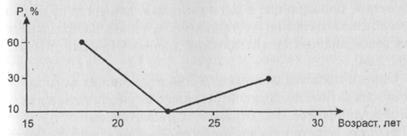
Рис. 6. Полигон распределения по возрасту
При его построении объединялись данные, относящиеся к интервалам 15-20 и 25-30
все же закономерностью, поскольку она позволяет нам сформировать какое-то новое представление об изучаемой совокупности респондентов, представление, связанное с описанием совокупности “в среднем”, как целого. Правда, здесь требуется подчеркнуть, что возможна двоякая интерпретация нашего шага.
а) Мы прибегли к определенному “сжатию” информации только потому, что не имели возможности прямо противоположного способа действий: скажем, измерения возраста с точностью до одного месяца и использования репрезентативной выборки в сотни тысяч единиц. Имея возможность сделать это, мы получили бы полигон, неотличимый на глаз от непрерывной кривой.
В таком случае естественно бы было полагать, что мы очень огрубили информацию и ушли дальше от “истинного” распределения, чем находились бы при использовании рис.5. Рассуждая так, мы фактически придерживаемся традиционного для математической статистики восприятия процесса разбиения диапазона изменения признака на интервалы. В соответствии с этим восприятием, указанный подход, называемый обычно методом группировки, имеет следующие свойства: (1) является просто более экономным способом записи информации, содержащейся в выборке (скажем, практически бесполезно знать 10 тысяч наблюдений, заданных на отрезке (0,10), достаточно указать, какая доля наблюдений содержится в интервале (0,1), (0,2) и т.д.), (2) обладает очевидными недостатками, связанными с некоторой неопределенностью в способе построения интервалов и частичной потерей информации при огрублении данных (фактически мы все наблюдения, попадающие в один интервал, заменяем на среднюю точку этого интервала) и (3) используется лишь на предварительном этапе анализа статистических данных [Ивченко, Медведев, 1992. С.24].
Однако представляется, что в социологических задачах часто более адекватной должна считаться другая интерпретация результатов группировки. Она отражается в следующем.
б) Даже если при дальнейшем дроблении величины интервалов распределение респондентов по возрасту будет стремиться к определенному виду, этот вид может вообще не интересовать социолога. Причины – в следующем. Многие “числовые” характеристики людей (в том числе и возраст), чаще всего интересуют социолога не сами по себе (возраст – не как количество оборотов, которые Земля совершила вокруг Солнца за время существования респондента), а лишь как признаки – приборы, как своего рода индикаторы, показатели чего-то непосредственно не измеримого, латентного (например, возраст служит для оценки социальной зрелости опрашиваемого). В таком случае указанное "огрубление" распределения в действительности может служить лишь переходом от признака-прибора к признаку, непосредственно интересующему исследователя (подробнее об этом см. [Клигер и др., 1978; Толстова, 1998]). И наше укрупнение может говорить об интересующем нас распределении больше, чем упомянутый результат дробления. Таким образом, описанная интерпретация частотных распределений – это своеобразное решение одной из проблем социологического измерения.
Итак, при описанной интерпретации имеется налицо, казалось бы, парадоксальная ситуация: если мы хотим получить новое знание с помощью анализа сравнительно небольшого количества наблюденных значений рассматриваемого признака, мы должны “сжать” исходные данные путем разбиения диапазона изменения значений этого признака на интервалы. За счет потери одной информации, мы приобретаем другую. Здесь тоже хотелось бы сделать определенное обобщение – вычленение какой-либо закономерности из массива “сырых” данных всегда сопряжено с потерей информации. Теряем “сырую” информацию, приобретаем ту, которая содержится в найденной закономерности.
Выбор способа разбиения диапазона изменения признака на интервалы представляет собой проблему, далеко не всегда просто решающуюся. В следующем параграфе рассмотрим ее более подробно. А сейчас приведем пример (заимствованный из [Миркин, 1985. С. 18]), иллюстрирующий, какую огромную роль играет группировка значений признака при анализе данных. При первом чтении книги текст до конца параграфа можно пропустить, поскольку в нем используются положения, рассматриваемые в п.п. 2.1.3 2.3.
Предположим, что мы изучаем связь между двумя признаками: Y, принимающим два значения – 1 и 2, и Х, принимающим 4 значения – 1,2,3,4. Предположим, что исходная таблица сопряженности имеет вид (определение таблицы сопряженности дано в п. 1.3 раздела 2; в каждой клетке таблицы указано количество респондентов, обладающих отвечающим этой клетке сочетанием значений рассматриваемых признаков):
Пример таблицы сопряженности при наличии связи между признаками Х и Y
| X | Y | Итого | |
| Итого |
Нетрудно понять, что между Х и Y имеется статистическая связь (подробнее о показателях связи см. п. 3 раздела 2). Это можно обосновать, вычислив любой показатель связи, а можно усмотреть и из полуинтуитивных соображений: если бы связи не было, то “внутри” каждого значения признака Х респонденты должны были бы поровну распределяться между двумя категориями признака Y (первая строка должна была бы состоять из частот 25 и 25, вторая – 24 и 24, третья – 21 и 21, четвертая – 20 и 20).
Предположим теперь, что мы сгруппировали значения признака Х, объединив градации 1 и 2, а также градации 3 и 4 (другими словами, разбили значения признака Х на интервалы).
Получим новую таблицу сопряженности:
Таблица сопряженности, получающаяся из предыдущей таблицы путем объединения градаций (1 и 2) и (3 и 4) признака Х. Связи между Х и Y нет
| X | Y | Итого | |
| 1+2 | |||
| 3+4 | |||
| Итого |
"Невооруженным" взглядом видно, что никакой зависимости между переделанным признаком Х и признаком Y нет. Связь “исчезла”.
Сгруппируем значения признака Х по-другому (т.е. по-другому разобьем совокупность этих значений на интервалы): объединим градации 1 и 3, а также градации 2 и 4.
Получим еще одну таблицу сопряженности:
Таблица сопряженности, получающаяся из первой таблицы путем объединения градаций (1 и 3) и (2 и 4) признака Х. Связь между Х и Y имеется.
| X | Y | Итого | |
| 1+3 | |||
| 2+4 | |||
| Итого |
Наличие связи представляется очевидным. Связь снова "появилась".
10. Проблема разбиения диапазона изменения значений признака на интервалы. Кумулята. Проблема пропущенных значений.
При определении способа разбиения встает целый ряд взаимосвязанных вопросов: какова величина интервалов? Сколько их? Каково соотношение между ними? И т.д.
Мы не будем подробно рассматривать эти вопросы. Лишь коротко заметим, что их решение в первую очередь должно опираться на содержание задачи. Так, при изучении типов личности, вполне возможно, что нас удовлетворит разбиение всех возрастов от 15 до 100 лет на равные интервалы: (15-20), (20-25), (25-30) и т.д. Если же одной из решаемых нами задач будет изучение выбора молодежью жизненного пути, то мы, вероятно отдельно рассмотрим интервалы (15-17), поскольку в 17 лет человек кончает школу; (17-18), поскольку в 18 лет юношей забирают в армию; (18-22), поскольку в 22 года большинство поступивших после школы в институт получают дипломы о высшем образовании и т.д. Если нас интересует лишь производственная деятельность людей, то всех лиц старше 60 лет мы будем считать одинаковыми по возрасту (в анкете одним из вариантов ответа на вопрос о возрасте будет вариант “старше 60”). Если нас будут интересовать какие-то аспекты геронтологии, то, возможно мы выделим интервалы (70-72), (72-74) и т.д. [Пасхавер, 1972; Сиськов, 1971]
Конечно, какую-то роль при выборе интервалов разбиения может сыграть желание исследователя иметь возможность сравнивать свои результаты с результатами других социологов - в таком случае способы разбиения диапазонов изменения тех признаков, по которым совокупности сравниваются, должны быть одинаковыми. В свое время были выдвинуты предложения по унификации разбиения на интервалы диапазонов тех признаков, которые обычно входят в стандартную “паспортичку” анкеты. Однако это не прижилось, поскольку все же разные задачи диктуют разные разбиения [Петренко, Ярошенко, 1979].
Существуют и математические методы, помогающие разбить диапазон изменения признака на интервалы [Орлов, 1977]. Однако при этом речь идет о достаточно тонких и сложных моделях того, что происходит в сознании респондента, дающего нам информацию. Здесь мы их рассматривать не будем.
Разбив на интервалы, мы ставим другие вопросы. Рассмотрим наиболее часто встающие.
К какому интервалу относить объект, для которого значение рассматриваемого признака лежит на “стыке” двух интервалов? Ответом на него обычно служит соглашение: скажем, все “стыки” считать принадлежащими правому интервалу (используя известные математические обозначения, можно сказать, например, что при разбиении диапазона изменения возраста на равные интервалы по 5 лет, мы в действительности будем рассматривать полуинтервалы: [15, 20), [20, 25) и т.д. Последним полуинтервалом может быть, например, [60, 65). Заметим, что фактически используемая нами при этом модель (мы уже неоднократно подчеркивали, что какая-то модель всегда стоит за любым, даже самым простым, математическим методом, и что для социолога раскрытие смысла подобных моделей является первоочередной задачей) изучаемого явления может привести к неоправданному (хотя вряд ли большому, особенно для многочисленной выборки) сдвигу массива данных вправо. Это скажется, например, при расчете мер средней тенденции (их определение см. ниже).
Как в только что описанной ситуации поступать с правым концом самого правого интервала? Прибегая к только что приведенному примеру, переформулируем вопрос: что делать с возрастом 25 лет? Ответы могут быть разными: например, вместо полуинтервала [60,65) использовать отрезок [60,65]; ввести дополнительный полуинтервал [65,70). При достаточно репрезентативной выборке принятие любого из них приведет примерно к одному и тому же результату (точнее, результаты не будут статистически значимо отличаться друг от друга).
При построении полигонов и гистограмм встают свои вопросы.
От какой точки интервала проводить вертикаль, на которой будет откладываться величина процента при построении полигона? На этот вопрос мы ответили в работе [Толстова, 1998] (см. также Приложение 1). Там соответствующая ситуация рассмотрена очень подробно. Здесь же лишь отметим, что вертикаль может начинаться в любой точке интервала (хотя на практике из иллюстративных соображений чаще всего используют его середину).
Конечно, при выборе разных точек, в процессе дальнейшего анализа данных, вообще говоря, будут получаться разные результаты. Однако если считать, что мы работаем в рамках интервальной шкалы, то соответствующее различие будет именно таким, которое с точки зрения теории измерений для этой шкалы вполне допустимо.
Чем отличаются друг от друга модели, которые мы фактически используем, строя, с одной стороны, - полигон, а, с другой, - гистограмму распределения?
В обоих случаях мы в процессе построения закономерности (коей является частотное распределение) теряем информацию о том, каким образом распределены объекты внутри каждого интервала, и восполняем эту потерю путем введения модельных предположений об этом распределении. Обычно считают, что полигон отвечает кусочно-линейной плотности распределения. При использовании же гистограммы полагают, что объекты равномерно распределены внутри каждого интервала.
Напомним, что в соответствии с известными положениями теории вероятностей, площадь фигуры, лежащей под кривой функции плотности над каким-либо интервалом равна вероятности попадания объекта в этот интервал. Особенное внимание ниже будет обращено на то, как это свойство проявляется в случае гистограммы (здесь оно превращается в то обстоятельство, что вероятность попадания значения признака на тот или иной отрезок равна площади соответствующего отрезку прямоугольника гистограммы), поскольку площади прямоугольников легко вычисляются.
Как строить гистограмму с неравными интервалами?
Способ построения такой гистограммы опирается на только что сформулированное положение о площадях составляющих гистограмму прямоугольников. На примере опишем соответствующий алгоритм.
Предположим, что частотная таблица, на базе которой мы хотим построить гистограмму, отвечающую распределению нашей совокупности респондентов по возрасту, имеет вид, отраженный в таблице 2..
Таблица 2
|
|
|
|
|
Дата добавления: 2015-04-23; Просмотров: 642; Нарушение авторских прав?; Мы поможем в написании вашей работы!