КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Методы вторичной статистической обработки результатов эксперимента
С помощью вторичных методов статистический обработки экспериментальных данных непосредственно проверяются, доказываются или опровергаются гипотезы, связанные с экспериментом. Эти методы, как правило, сложнее, чем методы первичной статистической обработки, и требуют от исследователя хорошей подготовки в области элементарной математики и статистики.
Обсуждаемую группу методов можно разделить на несколько подгрупп: 1. Регрессионное исчисление. 2. Методы сравнения между собой двух или нескольких элементарных статистик (средних, дисперсий и т.п.), относящихся к разным выборкам. 3. Методы установления статистических взаимосвязей между переменными, например их корреляции друг с другом. 4. Методы выявления внутренней статистической структуры эмпирических данных (например, факторный анализ). Рассмотрим каждую из выделенных подгрупп методов вторичной статистической обработки на примерах.
Регрессионное исчисление — это метод математической статистики, позволяющий свести частные, разрозненные данные к некоторому линейному графику, приблизительно отражающему их внутреннюю взаимосвязь, и получить возможность по значению одной из переменных приблизительно оценивать вероятное значение другой переменной.
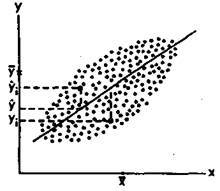
Воспользуемся для графического представления взаимосвязанных значений двух переменных х и у точками на графике (рис. 73). Поставим перед собой задачу: заменить точки на графике линией прямой регрессии, наилучшим образом представляющей взаимосвязь, существующую между данными переменными. Иными словами, задача заключается в том, чтобы через скопление точек, имеющихся на этом графике, провести прямую линию,
|
| ______ Глава 3. Статистический анализ экспериментальных данных ____ |
Рис.73. Прямая регрессии YnoX. х и у — средние значения переменных. Отклонения отдельных значений от линии регрессии обозначены вертикальными пунктирными линиями. Величина yt - у является отклонением измеренного значения переменной у. от оценки, а величина у - у является отклонением оценки от среднего значения (Цит. по: Иберла К. Факторный анализ. М., 1980. С. 23).
пользуясь которой по значению одной из переменных, х или у, можно приблизительно судить о значении другой переменной. Для того чтобы решить эту задачу, необходимо правильно найти коэффициенты а и Ь в уравнении искомой прямой:
у = ах + Ь.
Это уравнение представляет прямую на графике и называется уравнением прямой регрессии.
Формулы для подсчета коэффициентов а и Ь являются следующими:
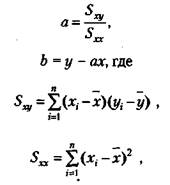
Часть II. Введение в научное психологическое исследование
где х., у{ — частные значения переменных X и Y, которым соответствуют точки на графике;
х, у — средние значения тех же самых переменных;
п — число первичных значений или точек на графике.
Для сравнения выборочных средних величин, принадлежащих к двум совокупностям данных, и для решения вопроса о том, отличаются ли средние значения статистически достоверно друг от друга, нередко используют ^-критерий Стъюдента. Его основная формула выглядит следующим образом:
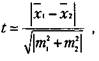
где х{ — среднее значение переменной по одной выборке данных;
хг — среднее значение переменной по другой выборке данных;
т1ит2 — интегрированные показатели отклонений частных значений из двух сравниваемых выборок от соответствующих им средних величин.
/и, и т2 в свою очередь вычисляются по следующим формулам:
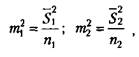
|
|
Дата добавления: 2015-06-04; Просмотров: 626; Нарушение авторских прав?; Мы поможем в написании вашей работы!