КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Алгоритм
|
|
|
|
U – критерий Манна – Уитни
Критерий предназначен для оценки различий между двумя выборками по уровню какого-либо признака, количественно измеренного. Он позволяет выявить различия между малыми выборками, когда n1, n2 ≥ 3 или n1= 2, n2≥ 5 и является более мощным, чем критерий Q Розенбаума.
Гипотезы:
Н0: Уровень признака в группе 2 не ниже уровня признака в группе 1.
Н1: Уровень признака в группе 2 ниже уровня признака в группе 1.
подсчета критерия U Манна-Уитни [15]
1. Перенести все данные испытуемых на индивидуальные карточки.
2. Пометить карточки испытуемых выборки 1 одним цветом, скажем красным, а все карточки из выборки 2 - другим, например синим.
3. Разложить все карточки в единый ряд по степени нарастания признака, не считаясь с тем, к какой выборке они относятся, как если бы мы работали с одной большой выборкой.
4. Проранжировать значения на карточках, приписывая меньшему значению меньший ранг, а одинаковым значениям – ранг, являющийся средним арифметическим значением от вероятных рангов (см. стр. 28). Всего рангов получится столько, сколько у нас (n1+п2).
5. Вновь разложить карточки на две группы, ориентируясь на цветные обозначения: красные карточки в один ряд, синие - в другой.
6. Подсчитать сумму рангов отдельно на красных карточках (выборка 1) и на синих карточках (выборка 2). Проверить, совпадает ли общая сумма рангов с расчетной, которая вычисляется по формуле 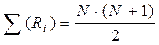 .
.
7. Определить большую из двух ранговых сумм.
8. Определить значение U по формуле:
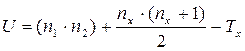 , где
, где
n1 - количество испытуемых в выборке 1;
n2 - количество испытуемых в выборке 2;
Тх - большая из двух ранговых сумм;
nх - количество испытуемых в группе с большей суммой рангов.
9. Определить критические значения U по Табл. 3 Приложения 3. Если Uэмп>Uкр0,05, Н0 принимается. Если Uэмп≤Uкр0,05, Н0 отвергается. Чем меньше значения U, тем достоверность различий выше.
Пример.
В НПК № 3 у студентов-филологов и студентов специальности «учитель начальных классов» диагностировали уровень интеллекта. Результаты представлены в табл. 13.1. можно ли сказать, что студенты разных специальностей обладают разным уровнем интеллекта.
Таблица 13.1.
Индивидуальные значения уровня интеллекта в выборке студентов специальности «учитель начальных классов» (n1=14) и студентов-филологов (n2=12)
| Студенты «началка» | Студенты-филологи | ||
|
| ||
Данный метод основан на подсчете рангов.
Запомните правила ранжирования. Их три:
1. Меньшему значению начисляется меньший ранг.
2. В случае, если несколько значений равны, им начисляется ранг, представляющий собой среднее значение из тех рангов, которые они получили бы, если бы не были равны.
3. Общая сумма рангов должна совпадать с расчетной, которая определяется по формуле , где N – общее количество ранжируемых наблюдений.
В нашем примере, проделав шаги 1 – 6 алгоритма, получим следующие данные.
Таблица 13.2.
Подсчет ранговых сумм
| Студенты-«началка» (n1=14) | Студенты -филологи (п2=12) | |||
| Показатель интеллекта | Ранг | Показатель интеллекта | Ранг | |
| 20,5 | ||||
| 20,5 | ||||
| 15,5 | 15,5 | |||
| 11,5 | 11,5 | |||
| 11,5 | ||||
| 11,5 | ||||
| 6,5 | 6,5 | |||
| 4,5 | 4,5 | |||
| Суммы | ||||
| Средние | 107,2 | 111,5 |
Общая сумма рангов 165 + 186 = 351.
Расчетная сумма: 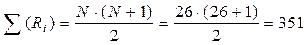 . Ошибки нет.
. Ошибки нет.
Шаг 7. Бόльшая сумма рангов – в группе студентов – филологов (Тх=186).
Шаг 8. Определим значение U.
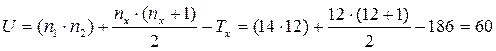
Шаг 9. Определим критические значения U по Табл.3 Прил. 3 для n1 =14 и n2 =12.
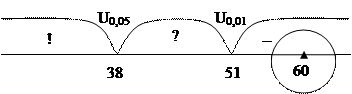
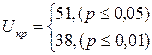
Uэмп > Uкр.
Ответ: Н0 принимается. Группа студентов-филологов не превосходит группу студентов «началки» по уровню интеллекта, т.е. различия недостоверны.
φ*-критерий (угловое преобразование Фишера)
Данный критерий относится к группе многофункциональных. Это означает, что он может использоваться по отношению к самым разнообразным данным, выборкам и задачам. Выборки могут быть разными, а можно сопоставлять данные, полученные на одной выборке в разных условиях.
Многофункциональный критерий построен на сопоставлении долей, выраженных в долях единицы или в процентах. Суть критерия состоит в определении того, какая доля наблюдений (реакций, выборов, испытуемых) в данной выборке характеризуется интересующим нас эффектом. Таким эффектом может быть:
- определенное значение качественно определяемого признака (например, отнесенность к определенному полу, выражение согласия с каким-либо предложением и др.),
- определенный уровень количественно измеряемого признака (например, получение оценки, превосходящей проходной бал; выбор дистанции в разговоре, превышающей 50 см и др.),
- определенное соотношение значений или уровней исследуемого признака (например, преобладание положительных сдвигов над отрицательными; преимущественное проявление крайних значений признака).
Другими словами, здесь сводятся любые данные к альтернативной шкале «есть эффект – нет эффекта». Важно, что ни одна из сопоставляемых долей не должна быть равной нулю!!!
Гипотезы:
Н0: Доля лиц, у которых проявляется исследуемый эффект, в выборке 1 не больше, чем в выборке 2.
Н1: Доля лиц, у которых проявляется исследуемый эффект, в выборке 1 больше, чем в выборке 2.
|
|
|
Дата добавления: 2014-01-03; Просмотров: 1627; Нарушение авторских прав?; Мы поможем в написании вашей работы!