КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Сравнение двух средних независимых выборок
|
|
|
|
Сравнение двух выборок
(критерий Стьюдента)
Часто в процессе проведения испытаний необходимо сравнить результаты двух независимых выборок с тем, чтобы оценить достоверность разности Х1 – Х2. Если эта разность недостаточно значима, то средние Х1 и Х2 могут относиться к одной и той же генеральной совокупности. Если же эта разность достаточно значима, то средние Х1 и Х2 относятся к разным генеральным совокупностям или к одной совокупности, но при измерении величин Х1 и Х2 имеется достаточная разница в методах их определения.
При большом числе испытаний n>30 и m>30 критерий достоверности определяется по формуле:
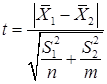 (42)
(42)
где S1, S2 – среднее квадратическое отклонение в первой и второй выборке;
n, m – число значений в первой и второй выборке.
Полученное значение сравнивают с табличными значениями критерия Стьюдента.
При малом числе испытаний n+m<60
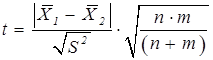 (43)
(43)
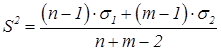
При числе испытаний n=m<30
 (44)
(44)
где σ1, σ2 – среднее квадратическое отклонение в первой и второй выборке.
При использовании формулы (43) находят значение
k = n + m -2 (45)
и по таблице 15 для найденной величины k и при вероятности 95% определяют табличное значение t.
При использовании формулы (44) находят значение
k = 2 . (n - 1) (46)
и по таблице 15 для найденной величины k и при вероятности 95% определяют табличное значение t.
Если tр > t, то разность средних Ха –Хв при нормальном распределении достоверна более чем на 95%. Если tр < t, то разность средних не считается достаточно достоверной.
Таблица 15
| k | t | k | t | k | t | k | t |
| 12,78 | 2,23 | 2,09 | 2,05 | ||||
| 4,30 | 2,20 | 2,09 | 2,05 | ||||
| 3,18 | 2,18 | 2,08 | 2,04 | ||||
| 2,78 | 2,16 | 2,07 | 2,02 | ||||
| 2,57 | 2,14 | 2,07 | 2,00 | ||||
| 2,45 | 2,13 | 2,06 | 1,98 | ||||
| 2,37 | 2,12 | 2,06 | ¥ | 1,96 | |||
| 2,30 | 2,11 | 2,06 | - | - | |||
| 2,26 | 2,10 | 2,05 | - | - |
В программе Excel применяется функция ТТЕСТ (рис. 35). Она возвращает вероятность, соответствующую критерию Стьюдента. Функция ТТЕСТ используется, чтобы определить, насколько вероятно, что две выборки взяты из генеральных совокупностей, которые имеют одно и то же среднее.
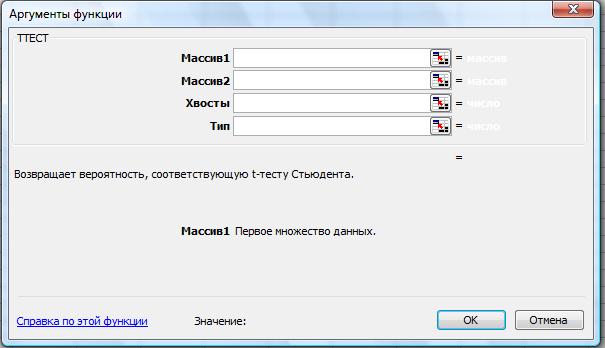
Рис. 35. Функция ТТЕСТ
ТТЕСТ (массив1; массив2; хвосты; тип)
Массив1 — первое множество данных.
Массив2 — второе множество данных.
Хвосты — число хвостов распределения. Если хвосты = 1, то функция ТТЕСТ использует одностороннее распределение. Если хвосты = 2, то функция ТТЕСТ использует двустороннее распределение.
Тип — вид исполняемого t-теста.
| Тип | Выполняемый тест |
| Парный | |
| Двухвыборочный с равными дисперсиями (гомоскедастический) | |
| Двухвыборочный с неравными дисперсиями (гетероскедастический) |
Если массив1 и массив2 имеют различное число точек данных, а тип = 1 (парный), то функция ТТЕСТ возвращает значение ошибки #Н/Д.
Аргументы хвосты и тип усекаются до целых.
Если хвосты или тип не является числом, то функция ТТЕСТ возвращает значение ошибки #ЗНАЧ!.
Если хвосты имеет значение, отличное от 1 и 2, то функция ТТЕСТ возвращает значение ошибки #ЧИСЛО!.
TTEСT использует данные массива1 и массива2 для вычисления неотрицательной t-статистики. Если хвосты = 1, TTEСT возвращает вероятность более высокого значения t-статистики, исходя из предположения, что массив1 и массив2 являются выборками, принадлежащими одной и той же генеральной совокупности. Значение, возвращаемое функцией TTEСT в случае, когда хвосты = 2, является двусторонним значением, возвращаемым, когда хвосты = 1 и представляет собой вероятность более высокого абсолютного значения t-статистики, исходя из предположения, что массив1 и массив2 являются выборками, принадлежащими одной и той же генеральной совокупности.
В надстройке АНАЛИЗ ДАННЫХ представлено несколько типов теста для сравнения выборочных средних (рис. 36).
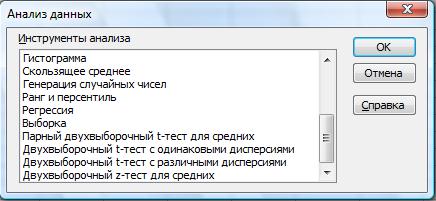
Рис. 36. Пакет анализа
Двухвыборочный t-тест проверяет равенство средних значений генеральной совокупности по каждой выборке. Эти три средства допускают следующие условия: равные дисперсии генерального распределения, дисперсии генеральной совокупности не равны, а также представление двух выборок до и после наблюдения по одному и тому же субъекту.
Для всех трех средств, перечисленных ниже, значение t-статистики t вычисляется и отображается как "t-статистика" в выводимой таблице. В зависимости от данных, это значение t может быть отрицательным или неотрицательным. Если предположить, что средние генеральной совокупности равны, при t < 0 “P(T <= t) одностороннее” дает вероятность того, что наблюдаемое значение t-статистики будет более отрицательным, чем t. При t >=0 “P(T <= t) одностороннее” делает возможным наблюдение значения t-статистики, которое будет более положительным чем t. “t критическое одностороннее” выдает пороговое значение, так что вероятность наблюдения значения t-статистики большего или равного “t критическое одностороннее” равно Alpha. “P(T <= t) двустороннее” дает вероятность наблюдения значения t-статистики по абсолютному значению большего чем t. “P критическое двустороннее” выдает пороговое значение, так что значение вероятности наблюдения значения t- статистики по абсолютному значению большего “P критическое двустороннее” равно Alpha.
Двухвыборочный t-тест с одинаковыми дисперсиями. Двухвыборочный t-тест Стьюдента служит для проверки гипотезы о равенстве средних для двух выборок. Эта форма t-теста предполагает совпадение значений дисперсии генеральных совокупностей и обычно называется гомоскедастическим t-тестом.
Элементы диалогового окна «Двухвыборочный t-тест с одинаковыми дисперсиями» приведены на рис. 37.
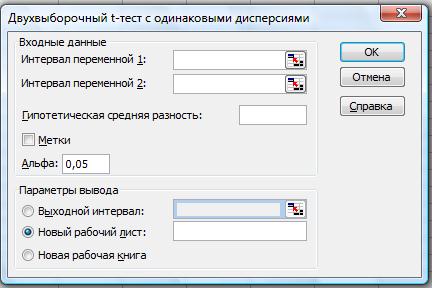
Рис. 37. Двухвыборочный t-тест с одинаковыми дисперсиями
Интервал переменной 1. Дается ссылка на первый диапазон анализируемых данных. Диапазон должен состоять из одного столбца или одной строки.
Интервал переменной 2. Дается ссылка на второй диапазон анализируемых данных. Диапазон должен состоять из одного столбца или одной строки.
Гипотетическая средняя разность. Вводится число, равное предполагаемой разности средних. Значение 0 (нуль) указывает, что средние принимаются равными.
Заголовки. Если первая строка или первый столбец входного интервала содержит заголовки, то устанавливается флажок. Флажок снимается, если заголовки отсутствуют; в этом случае подходящие названия для данных выходного диапазона будут созданы автоматически.
Альфа. Вводится уровень надежности для теста. Его значение должно находиться в диапазоне 0...1. Уровень альфа связан с вероятностью возникновения ошибки типа I (опровержение верной гипотезы).
Выходной диапазон. Вводится ссылка на левую верхнюю ячейку выходного диапазона. Размер выходного диапазона будет определен автоматически, и на экран будет выведено сообщение в случае возможного наложения выходного диапазона на исходные данные.
Новый лист. Устанавливается переключатель таким образом, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. Если в этом есть необходимость, введите имя нового листа в поле, расположенном напротив соответствующего положения переключателя.
Новая книга. Устанавливается переключатель таким образом, чтобы открыть новую книгу и вставить результаты анализа в ячейку A1 на первом листе в этой книге.
Результаты расчетов выводятся в виде таблицы (таблица 16).
Таблица 16
| Заголовок | Объяснение |
| Среднее | Средние значения первой и второй выборки |
| Дисперсия | Дисперсии первой и второй выборки |
| Наблюдения | Число значений в первой и второй выборке (n и m) |
| Объединенная дисперсия | Выборочная дисперсия 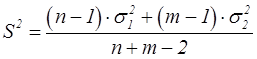 , вычисленная по объединенным данным обеих выборок , вычисленная по объединенным данным обеих выборок
|
| Гипотетическая разность средних | Гипотетическая разность средних 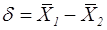
|
| df | Число степеней свободы статистики Т (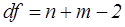 ) )
|
| t - статистика | Расчетное значение t, найденное по формуле (50) |
| P(T≤t) одностороннее | Значимость α. В случае а) 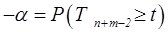 , в случае б) , в случае б) 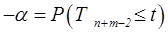 , где t – расчетное значение статистики Т; Тn+m-2 – случайная величина, имеющая распределение Стьюдента с (n + m-2) степенями свободы , где t – расчетное значение статистики Т; Тn+m-2 – случайная величина, имеющая распределение Стьюдента с (n + m-2) степенями свободы
|
| t критическое одностороннее | Критическое значение t (α; n + m-2) порядка α распределения Стьюдента с (n + m-2) степенями свободы 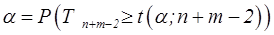
|
| P(T≤t) двухстороннее | Значимость 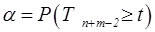 (случай в)) (случай в))
|
| t критическое двухстороннее | Критическое значение t (α/2; n + m-2) порядка α/2 распределения Стьюдента с (n + m-2) степенями свободы 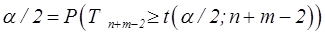
|
Двухвыборочный t-тест с разными дисперсиями. Двухвыборочный t-тест Стьюдента (рис. 38) используется для проверки гипотезы о равенстве средних для двух выборок данных из разных генеральных совокупностей. Эта форма t-теста предполагает несовпадение дисперсий генеральных совокупностей и обычно называется гетероскедастическим t-тестом. Если тестируется одна и та же генеральная совокупность, используется парный тест.
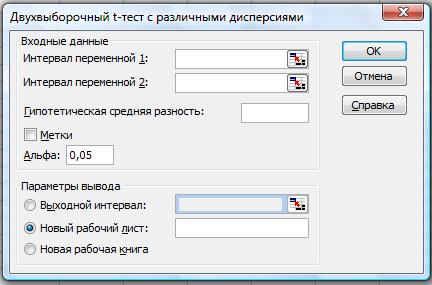
Рис. 38. Двухвыборочный t-тест с разными дисперсиями
Для определения тестовой величины t используется следующая формула.
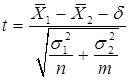 (47)
(47)
где δ - гипотетическая разность средних; .
Так как результат вычисления обычно не бывает целым числом, значение df округляется до целого для получения порогового значения из t-таблицы. Функция Excel ТТЕСТ по возможности использует вычисленные значения без округления для вычисления значения ТТЕСТ с нецелым значением df. Из-за разницы подходов к определению степеней свободы, результаты функций ТТЕСТ и t-тест будут различаться в случае с разными дисперсиями. Следующая формула используется для вычисления степени свободы df.
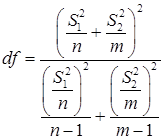 (48)
(48)
Элементы диалогового окна «Двухвыборочный t-тест с различными дисперсиями» совпадают с элементами диалогового окна «Двухвыборочный t-тест с одинаковыми дисперсиями»
Парный двухвыборочный t-тест для средних. Парный двухвыборочный t-тест Стьюдента (рис. 39) используется для проверки гипотезы о различии средних для двух выборок данных. В нем не предполагается равенство дисперсий генеральных совокупностей, из которых выбраны данные. Парный тест используется, когда имеется естественная парность наблюдений в выборках, например, когда генеральная совокупность тестируется дважды — до и после эксперимента.
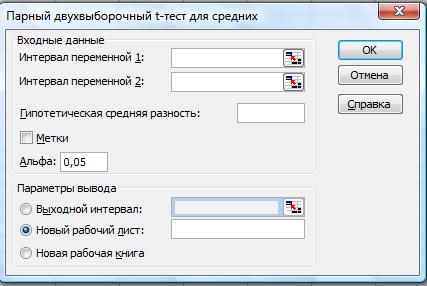
Рис. 39. Парный двухвыборочный t-тест для средних
Одним из результатов теста является совокупная дисперсия (совокупная мера распределения данных вокруг среднего значения), вычисляемая по следующей формуле.
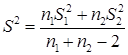 (49)
(49)
Элементы диалогового окна «Парный двухвыборочный t-тест для средних» совпадают с элементами диалогового окна «Двухвыборочный t-тест с одинаковыми дисперсиями».
|
|
|
|
|
Дата добавления: 2014-01-03; Просмотров: 4627; Нарушение авторских прав?; Мы поможем в написании вашей работы!