КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Расчет теоретических уровней линейного тренда
|
|
|
|
| Год | Производство мяса, млн. т. | Условное обозначение времени, t | t2 | yt | 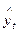
| (y-)2
|
| 9,4 8,3 7,5 6,8 5,9 | 9,4 16,6 22,5 27,2 29,5 | 9,28 8,43 7,58 6,73 5,88 | 0,0144 0,0169 0,0064 0,0049 0,0004 | |||
| n=5 | 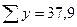
| 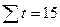
| 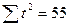
| 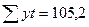
| 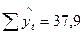
| 0,043 |
Приняв в качестве гипотетической функции теоретических уровней прямую 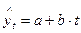 , определим параметры последней:
, определим параметры последней:
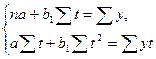
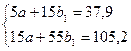
Решение этой системы можно осуществить по формулам:
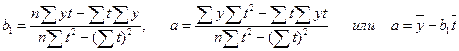 .
.
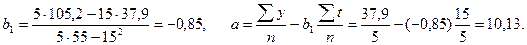
Отсюда искомое уравнение тренда: 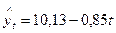 . Подставляя в полученное уравнении значения 1, 2, 3, 4, 5, определяем теоретические уровни ряда (см. предпоследнюю графу табл. 4.3). Сравнивая значения эмпирических и теоретических уровней, видим, что они близки, т.е. можно сказать, что найденное уравнение весьма удачно характеризует основную тенденцию изменения уровней именно как линейную функцию.
. Подставляя в полученное уравнении значения 1, 2, 3, 4, 5, определяем теоретические уровни ряда (см. предпоследнюю графу табл. 4.3). Сравнивая значения эмпирических и теоретических уровней, видим, что они близки, т.е. можно сказать, что найденное уравнение весьма удачно характеризует основную тенденцию изменения уровней именно как линейную функцию.
Система нормальных уравнений упрощается, если отсчет времени ведется от середины ряда. Например, при нечетном числе уровней серединная точка (год, месяц) принимается за нуль. Тогда предшествующие периоды обозначаются соответственно -1, -2, -3 и т.д., а следующие за средним – соответственно +1, +2, +3 и т.д. При четном числе уровней два срединных момента (периода) времени обозначают −1 и +1, а все последующие и предыдущие, соответственно, через два интервала: 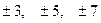 и т.д.
и т.д.
При таком порядке отсчета времени (от середины ряда) 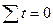 , система нормальных уравнений упрощается до следующих двух уравнений, каждое из которых решается самостоятельно:
, система нормальных уравнений упрощается до следующих двух уравнений, каждое из которых решается самостоятельно:
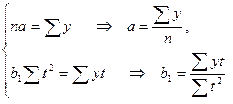
Важное значение при построении модели временного ряда имеет учет сезонных и циклических колебаний. Простейшим подходом, позволяющим учесть в модели сезонные и циклические колебания, является расчет значений сезонной/циклической компоненты и построение аддитивной и мультипликативной модели временного ряда.
Общий вид аддитивной модели следующий: Y=T+S+E. Эта модель предполагает, что каждый уровень временного уровня ряда может быть представлен как сумма трендовой T, сезонной S и случайной компонент. Общий вид мультипликативной модели выглядит как: Y=T∙S∙E.
Выбор одной из двух моделей проводится на основе анализа структуры сезонных колебаний. Если амплитуда колебаний приблизительно постоянна, строят аддитивную модель временного ряда, в которой значения сезонной компоненты предполагаются постоянными для различных циклов. Если амплитуда сезонных колебаний возрастает или уменьшается, строят мультипликативную модель временного ряда, которая ставит уровни ряда в зависимость от значений сезонной компоненты.
Построение аддитивной и мультипликативной моделей сводится к расчету T, S, E для каждого уровня ряда. Этапы построения модели включают в себя следующие шаги:
1. Выравнивание исходного ряда методом скользящей средней
2. Расчет значений сезонной компоненты S.
3. Устранение сезонной компоненты из исходных уровней ряда и получение выровненных данных в аддитивной (T+E) или мультипликативной (T∙E) модели.
4. Аналитическое выравнивание уровней (T+E) или (T∙E) и расчет значений T с использованием полученного уравнения тренда.
5. Расчет полученных по модели значений (T+E) или (T∙E).
6. Расчет абсолютных и/или относительных ошибок. Если полученные значения не содержат автокорреляции, ими можно заменить исходные уровни ряда и в дальнейшем использовать временной ряд ошибок E для анализа взаимосвязи исходного ряда и других временных рядов.
Рассмотрим другие методы анализа взаимосвязи, предположив что изучаемые временные ряды не содержат периодических колебаний. Допустим, что изучается зависимость между рядами х и у. Для количественной характеристики этой зависимости используется линейный коэффициент корреляции. Если рассматриваемые временные ряды имеют тенденцию, коэффициент корреляции по абсолютной величине будет высоким. Однако это не говорит о том, что х причина у. Высокий коэффициент корреляции в данном случае – это результат того, что х и у зависят от времени, или содержат тенденцию. При этом одинаковую или противоположную тенденцию могут иметь ряды, совершенно не связанные друг с другом причинно-следственной зависимостью. Например, коэффициент корреляции между численностью выпускников вузов и числом домов отдыха в РФ в период с 1970-1990 г. составил 0,8. Однако, это не говорит о том, что количество домов отдыха способствует росту числа выпускников или наоборот.
Для того чтобы получить коэффициенты корреляции, характеризующие причинно-следственную связь между изучаемыми рядами, следует избавиться от так называемой ложной корреляции, вызванной наличием тенденции в каждом ряду, которую устраняют одним из методов.
Предположим, что по двум временным рядам хt и уt строится уравнение парной регрессии линейной регрессии вида: 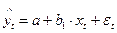 . наличие тенденции в каждом из этих временных рядов означает, что на зависимую уt и независимую хt переменные модели оказывает воздействие фактор времени, который непосредственно в модели не учтен. Влияние фактора времени будет выражено в корреляционной зависимости между значениями остатков
. наличие тенденции в каждом из этих временных рядов означает, что на зависимую уt и независимую хt переменные модели оказывает воздействие фактор времени, который непосредственно в модели не учтен. Влияние фактора времени будет выражено в корреляционной зависимости между значениями остатков 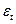 за текущий и предыдущие моменты времени, которая получила название автокорреляции в остатках.
за текущий и предыдущие моменты времени, которая получила название автокорреляции в остатках.
Автокорреляция в остатках – это нарушение одной из основных предпосылок МНК – предпосылки о случайности остатков, полученных по уравнению регрессии. Один из возможных путей решения этой проблемы состоит в применении обобщенного МНК.
Для устранения тенденции используются две группы методов:
- методы, основанные на преобразовании уровней исходного ряда в новые переменные, не содержащие тенденции (метод последовательных разностей и метод отклонения от трендов);
- методы, основанные на изучении взаимосвязи исходных уровней временных рядов при элиминировании воздействия фактора времени на зависимую и независимую переменные модели (включение в модель регрессии по временным рядам фактора времени).
Пусть имеются два временных ряда 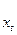 и
и 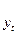 , каждый из которых содержит трендовую компоненту Т и случайную составляющую . Аналитическое выравнивание каждого из этих рядов позволяет найти параметры соответствующих уравнений трендов и определить расчетные по тренду уровни и
, каждый из которых содержит трендовую компоненту Т и случайную составляющую . Аналитическое выравнивание каждого из этих рядов позволяет найти параметры соответствующих уравнений трендов и определить расчетные по тренду уровни и 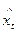 соответственное. Эти расчетные значения можно принять за оценку трендовой компоненты Т каждого ряда. Поэтому влияние тенденции можно устранить путем вычитания расчетных значений уровней ряда из фактических. Эту процедуру проделывают для каждого временного ряда в модели. Дальнейший анализ взаимосвязи рядов проводят с использованием не исходных уровней, а отклонений от тренда
соответственное. Эти расчетные значения можно принять за оценку трендовой компоненты Т каждого ряда. Поэтому влияние тенденции можно устранить путем вычитания расчетных значений уровней ряда из фактических. Эту процедуру проделывают для каждого временного ряда в модели. Дальнейший анализ взаимосвязи рядов проводят с использованием не исходных уровней, а отклонений от тренда 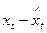 и
и 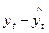 . Именно в этом и заключается метод отклонений от тренда.
. Именно в этом и заключается метод отклонений от тренда.
В ряде случаев вместо аналитического выравнивания временного ряда с целью устранения тенденции можно применить более простой метод – метод последовательных разностей. Если временной ряд содержит ярко выраженную линейную тенденцию, ее можно устранить путем замены исходных уровней ряда цепными абсолютными приростами (первыми разностями).
Пусть 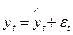 ,
, 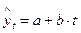 .
.
Тогда 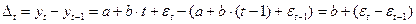 .
.
Коэффициент b – константа, которая не зависит от времени. При наличии сильной линейной тенденции отставки достаточно малы и в соответствии с предпосылками МНК носят случайный характер. Поэтому первые разности уровней ряда 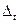 не зависят от переменной времени, их можно использовать для дальнейшего анализа.
не зависят от переменной времени, их можно использовать для дальнейшего анализа.
Если временной ряд содержит тенденцию в форме параболы второго порядка, то для ее устранения можно заменить исходные уровни ряда на вторые разности: 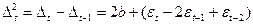 .
.
Если тенденции временного ряда соответствует экспоненциальной, или степенной, тренд, метод последовательных разностей следует применять не к исходным уровням ряда, а к их логарифмам.
Модель вида: 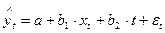 также относится к группе моделей, включающих фактор времени. Преимущество данной модели перед методами отклонений от трендов и последовательных разностей состоит в том, что она позволяет учесть всю информацию, содержащуюся в исходных данных, поскольку значения и – это уровни исходных временных рядов. Кроме того, модель строится по всей совокупности данных за рассматриваемый период в отличие от метода последовательных разностей, который приводит к потере числа наблюдений. Параметры этой модели определяются обычным МНК.
также относится к группе моделей, включающих фактор времени. Преимущество данной модели перед методами отклонений от трендов и последовательных разностей состоит в том, что она позволяет учесть всю информацию, содержащуюся в исходных данных, поскольку значения и – это уровни исходных временных рядов. Кроме того, модель строится по всей совокупности данных за рассматриваемый период в отличие от метода последовательных разностей, который приводит к потере числа наблюдений. Параметры этой модели определяются обычным МНК.
Пример. Построим уравнение тренда по исходным данным таблицы 4.4.
Таблица 4.4
Расходы на конечное потребление и совокупный доход (усл. ед.)
| Год | ||||||||
| Расходы на конечное потребление,
| ||||||||
| Совокупный доход,
|
Система нормальных уравнений имеет вид:
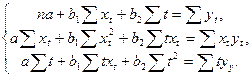
По исходным данным рассчитаем необходимые величины и подставим в систему:
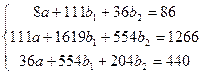
Уравнение регрессии имеет вид: 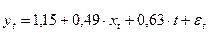 .
.
Интерпретация параметров уравнения следующая: 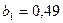 характеризует, что при увеличении совокупного дохода на 1 д.е. расходы на конечное потребление возрастут в среднем на 0,49 д.е в условиях существования неизменной тенденции. Параметр
характеризует, что при увеличении совокупного дохода на 1 д.е. расходы на конечное потребление возрастут в среднем на 0,49 д.е в условиях существования неизменной тенденции. Параметр 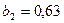 означает, что воздействие всех факторов, кроме совокупного дохода, на расходы на конечное потребление приведет к его среднегодовому абсолютному приросту на 0,63 д.е.
означает, что воздействие всех факторов, кроме совокупного дохода, на расходы на конечное потребление приведет к его среднегодовому абсолютному приросту на 0,63 д.е.
Рассмотрим уравнение регрессии вида: 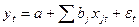 . Для каждого момента времени значение компоненты
. Для каждого момента времени значение компоненты 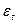 определяются как
определяются как 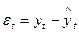 или
или 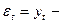
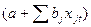 . Рассматривая последовательность остатков как временной ряд, можно построить график их зависимости от времени. В соответствии с предпосылками МНК остатки должны быть случайными (рис. 4.4).
. Рассматривая последовательность остатков как временной ряд, можно построить график их зависимости от времени. В соответствии с предпосылками МНК остатки должны быть случайными (рис. 4.4).

 |  |  |









 t
t
Рис. 4.4 Случайные остатки
Однако при моделировании временных рядов нередко встречаются ситуации, когда остатки содержат тенденцию или циклические колебания (рис. 4.5). Это говорит о том, что каждое следующее значение остатков зависит от предшествующих. В этом случае говорят о наличии автокорреляции в остатках.

 | |||||||||||||
 | |||||||||||||
 | |||||||||||||
 |  | ||||||||||||
 |  | ||||||||||||





 t t
t t
|  |  | |||||||||||||||
| |||||||||||||||||
 | |||||||||||||||||
 | |||||||||||||||||
 | |||||||||||||||||
 | |||||||||||||||||
|
а) б)
Рис. 4.5 Убывающая тенденция (а) и циклические колебания (б)
в остатках
Автокорреляция случайной составляющей 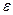 - корреляционная зависимость текущих и предыдущих значений случайной составляющей. Последствия автокорреляции случайной составляющей:
- корреляционная зависимость текущих и предыдущих значений случайной составляющей. Последствия автокорреляции случайной составляющей:
- коэффициенты регрессии становятся неэффективными;
- стандартные ошибки коэффициентов регрессии становятся заниженными, а значения t –критерия завышенными.
Для определения автокорреляции остатков известны два наиболее распространенных метода определения автокорреляции остатков. Первый метод – это построение графика зависимости остатков от времени и визуальное определение наличия или отсутствия автокорреляции. Второй метод – это использование критерия Дарбина-Уотсона, который сводится к проверке гипотезы:
- Н0 (основная гипотеза): автокорреляция отсутствует;
- Н1 и Н2 (альтернативные гипотезы): присутствует положительная или отрицательная автокорреляция в остатках соответственно.
Для проверки основной гипотезы используется статистика критерия Дарбина-Уотсона:
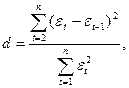 где
где 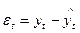 .
.
На больших выборках d≈2(1-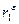 ), где - коэффициент автокорреляции 1-го порядка.
), где - коэффициент автокорреляции 1-го порядка.
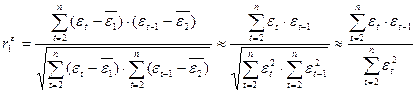 .
.
Если в остатках существует полная положительная автокорреляция и =1, то d=0; если в остатках есть полная отрицательная автокорреляция, то = -1 и d=4; если автокорреляция остатков отсутствует, то = 0, то d=2. Следовательно, 0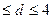 .
.
Существуют специальные статистические таблицы для определения нижней и верхней критических границ d -статистики – dL и dU. Они определяются в зависимости от n, числа независимых переменных k и уровня значимости 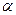 .
.
Если dнабл‹dL, то принимается гипотеза Н1: положительная автокорреляция.
Если dи‹dнабл‹2, то принимается гипотеза Н0: автокорреляции нет.
Если 2‹dнабл‹4-dи, то принимается гипотеза Н0: автокорреляции нет.
Если dнабл›4-dL, то принимается гипотеза Н2: отрицательная автокорреляция.
Если 4-dи‹dнабл‹4-dL, и dL‹dнабл‹dи, то имеет место случай неопределенности.
 |
0 dL dU 2 4- dU 4- dL 4
Рис. 4.6 Алгоритм проверки гипотезы о наличии автокорреляции остатков
Для применения критерия Дарбина-Уотсона есть ограничения. Он неприменим для моделей, включающих в качестве независимых переменных лаговые значения результативного признака, т.е. к моделям авторегрессии. Методика направлена только на выявление автокорреляции остатков первого порядка. Результаты являются более достоверными при работе с большими выборками.
В тех случаях, когда имеет место автокорреляция остатков, для определения оценок параметров a, b используют обобщенный метод МНК, который заключается в последовательности следующих шагов:
1. Преобразовать исходные переменные yt и xt к виду
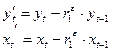
2. Применив обычный МНК к уравнению 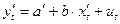 , где
, где 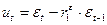 определить оценки параметров
определить оценки параметров 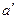 и b.
и b.
3. Рассчитать параметр a исходного уравнения из соотношения как 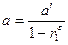 .
.
4. Выписать исходное уравнение .
Среди эконометрических моделей, построенных по временным данным, выделяют динамические модели.
Эконометрическая модель является динамической, если в данный момент времени t она учитывает значения входящих в нее переменных, относящихся как к текущему, так и к предыдущим моментам времени, т.е. эта модель отражает динамику исследуемых переменных в каждый момент времени.
Существует два основных типа динамических эконометрических моделей. К моделям первого типа относятся модели авторегрессии и модели с распределенным лагом, в которых значение переменной за прошлые периоды времени (лаговые переменные) непосредственно включены в модель. Модели второго типа учитывают динамическую информацию в неявном виде. В эти модели включены переменные, характеризующие ожидаемый и желаемый уровень результата, или один из факторов в момент времени t.
Модель с распределенным лагом имеет вид:
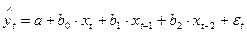
Модель авторегрессии имеет вид:
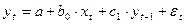
Построение моделей с распределенным лагом и моделей авторегрессии имеет свою специфику. Во-первых, оценка параметров моделей авторегрессии, а в большинстве случаев и моделей распределенным лагом не может быть проведена с помощью обычного МНК ввиду нарушения его предпосылок и требует специальных статистических методов. Во-вторых, исследователям приходится решать проблемы выбора оптимальной величины лага и определения его структуры. Наконец, в третьих, между моделями с распределенным лагом и моделями авторегрессии имеется определенная взаимосвязь, и в некоторых случаях необходимо осуществить переход от одноного типа моделей к другому.
Рассмотрим модель с распределенным лагом в предположении, что максимальная величина лага конечна: 
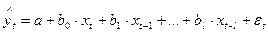 .
.
Даная модель говорит о том, что если в некоторый момент времени t происходит изменение независимой переменной x, то это изменение будет влиять на значения переменной y в течение l следующих моментов времени.
Коэффициент регрессии b0 при переменной xt характеризует среднее абсолютное изменение yt при изменении xt на 1 ед. своего измерения в некоторый фиксированный момент времени t, без учета воздействия лаговых значений фактора x. Этот коэффициент называется краткосрочным мультипликатором.
В момент t+1 воздействие факторной переменной xt на результат yt составит (b0+b1) условных единиц; в момент времени t+2 это воздействие можно охарактеризовать суммой (b0+b1+b2) и т.д. Полученные таким образом суммы называются промежуточными мультипликаторами.
С учетом конечной величины лага можно сказать, что изменение переменной xt в момент времени t на 1 условную единицу приведет к общему изменению результата через l моментов времени (b0+b1+b2+…+bl).
Введем следующее обозначение: b=(b0+b1+b2+…+bl). Величину b называется долгосрочным мультипликатором, который показывает абсолютное изменение в долгосрочном периоде t+l результата y под влиянием изменения на 1 ед. фактора x.
Величины 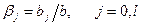 называются относительными коэффициентами модели с распределенным лагом. Если все коэффициенты bj имеют одинаковые знаки, то
называются относительными коэффициентами модели с распределенным лагом. Если все коэффициенты bj имеют одинаковые знаки, то 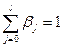 . Относительные коэффициенты
. Относительные коэффициенты 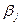 являются весами для соответствующих коэффициентов bj. Каждый из них измеряет долю общего изменения результативного признака в момент времени t+j.
являются весами для соответствующих коэффициентов bj. Каждый из них измеряет долю общего изменения результативного признака в момент времени t+j.
Зная величины , с помощью стандартных формул можно определить еще две важные характеристики модели множественной регрессии: величину среднего и медианного лагов.
Средний лаг рассчитывается по формуле средней арифметической взвешенной:
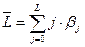
и представляет собой средний период, в течение которого будет происходить изменение результата под воздействием изменения фактора x в момент t. Если значение среднего лага небольшое, то это говорит о довольно быстром реагировании y на изменение x. Высокое значение среднего лага говорит о том, что воздействие фактора на результат будет сказываться в течение длительного периода времени.
Медианный лаг (LMe) – это величина лага, для которого период, в течение которого 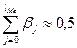 . Это тот период времени, в течение которого с момента времени t будет реализована половина общего воздействия фактора на результат.
. Это тот период времени, в течение которого с момента времени t будет реализована половина общего воздействия фактора на результат.
Изложенные выше приемы анализа параметров модели с распределенным лагом действительны только в предположении, что все коэффициенты при текущем и лаговых значениях исследуемого фактора имеют одинаковые знаки. Это предположение вполне оправдано с экономической точки зрения: воздействие одного и того же фактора на результат должно быть однонаправленным независимо от того, с каким временным лагом измеряется сила или теснота связи между этими признаками. Однако на практике получить статистически значимую модель, параметры которой имели бы одинаковые знаки, особенно при большой величине лага l, чрезвычайно сложно.
Применение обычного МНК к таким моделям в большинстве случаев затруднительно по следующим причинам:
- текущие и лаговые значения независимой переменной, как правило, тесно связаны друг с другом, тем самым оценка параметров модели проводится в условиях высокой мультиколлинеарности;
- при большой величине лага снижается число наблюдений, по которому строится модель, и увеличивается число ее факторных признаков, что ведет к потере числа степеней свободы в модели;
- в моделях с распределенным лагом часто возникает проблема автокорреляции остатков.
Рассмотрим модель авторегрессии например: 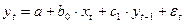 .
.
Как и в модели с распределенным лагом, b0 в этой модели характеризует краткосрочное изменение yt под воздействием изменения xt на 1 ед. Однако промежуточные и долгосрочный мультипликаторы в модели авторегрессии несколько иные. К моменту времени t+1 результат yt изменился под воздействием изменения изучаемого фактора в момент времени t на b0 единиц, а yt+1 – под воздействием своего изменения в непосредственно предшествующим момент времени на с1 единиц. Таким образом, общее абсолютное изменение результата в момент t+1 составит b0с1. Аналогично в момент времени t+2 абсолютное изменение результата составит b0с12 единиц и т.д. Следовательно, долгосрочный мультипликатор в модели авторегрессии можно рассчитать как сумму краткосрочного и промежуточного мультипликаторов:
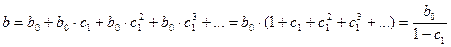 ,
,
где 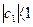 .
.
Такая интерпретация коэффициентов модели авторегрессии и расчет долгосрочного мультипликатора основаны на предпосылке о наличии бесконечного лага в воздействии текущего значения зависимой переменной на ее будущие значения.
Пример. Предположим, по данным о динамике показателей потребления и дохода в регионе была получена модель авторегрессии, описывающая зависимость среднедушевого объема потребления за год (С, млн. руб.) от среднедушевого совокупного годового дохода (Y, млн. руб.) и объема потребления предшествующего года:
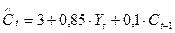 .
.
Краткосрочный мультипликатор равен 0,85. В этой модели он представляет собой предельную склонность к потреблению в краткосрочном периоде. Следовательно, увеличение среднедушевого совокупного дохода на 1 млн. руб. приводит к росту объема потребления в тот же год в среднем на 850 тыс. руб. Долгосрочную предельную склонность к потреблению в данной модели можно определить как
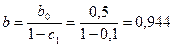 .
.
В долгосрочной перспективе рост среднедушевого совокупного дохода на 1 млн. руб. приведет к росту объема потребления в среднем на 944 тыс. руб. Промежуточные показатели предельной склонности к потреблению можно определить, рассчитав необходимые частные суммы за соответствующие периоды времени. Например, для момента времени t+1 получим:
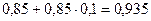 .
.
Это означает, что увеличение среднедушевого совокупного дохода в текущем периоде на 1 млн. руб. ведет к увеличению объема потребления в среднем на 935 тыс. руб. в ближайшем следующем периоде.
|
|
|
|
Дата добавления: 2014-01-03; Просмотров: 2282; Нарушение авторских прав?; Мы поможем в написании вашей работы!