КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Геометричне тлумачення
|
|
|
|
 У площині змінних x,y побудуємо діаграму розкиду (відповідні пари значень x та y)
У площині змінних x,y побудуємо діаграму розкиду (відповідні пари значень x та y)
Для парної лінійної регресії лінія регресії – це пряма на площині, яка визначається рівнянням
ŷ = b 0 + b 1 x,
де b0 - перетин з віссю ординат, а b1 – нахил прямої.
Залишки ei визначаються наступним чином:
ei = yi – ŷi = yi – (b 0 + b 1· xi),
де i =1,…, n.
1.4. Оцінювання параметрів моделі.
Метод найменших квадратів.
Постає питання: Як провести лінію регресії, щоб вона найкращим чином відображала залежність залежної змінної від незалежної? Логічним є припущення про те, що пряма повинна проходити таким чином, щоб кількісна міра відхилення залишків від лінії регресії була мінімальною. Тобто, щоб була мінімальною дисперсія залишків. Дисперсія залишків пропорційна сумі квадратів залишків.
У відповідності з цим припущенням пред'явимо вимоги до параметрів b0 та b1: невідомі параметри b 0 та b 1 визначаються таким чином, щоб мінімізувати величину 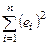 .
.
Таким чином, ми маємо критерій, за яким визначається оптимальність оцінок параметрів b 0 та b 1. Цей критерій є критерієм методу найменших квадратів:
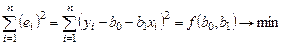 (7.2)
(7.2)
З курсу вищої математики відомо, що функція досягає екстремуму, у точці, де її перші часкові похідні дорівнюють нулю. Це дозволяє скласти систему рівнянь відносно невідомих параметрів b 0 та b 1:
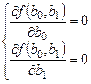
З урахуванням виразу (7.2) система рівнянь відносно b 0 та b 1 записується наступним чином:
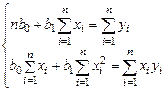 (7.3)
(7.3)
З урахуванням того, що оцінки середніх значень вектора спостережень за незалежною змінною xi та вектора спостережень за залежною змінною yi відповідно дорівнюють 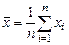 ,
, 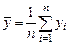 , рішення системи (7.3) для невідомих величин b 0 та b 1 будуть мати вигляд:
, рішення системи (7.3) для невідомих величин b 0 та b 1 будуть мати вигляд:
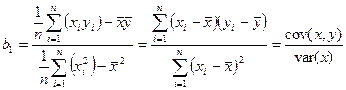
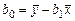
Властивості оцінок параметрів моделі лінійної регресії
1. Статистика b параметра β називається незміщеною, якщо математичне очікування оцінки дорівнює істинному значенню характеристики, тобто М(b)= β
2. Статистика b параметра β називається консистентною (спроможною), якщо зі збільшенням кількості спостережень n вона наближається до істинного значення характеристики, тобто 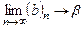
3. Статистика b параметра β називається ефективною, якщо вона має найменшу з усіх можливих (оцінок, отриманих за допомогою інших методів) дисперсію оцінки b.
Для лінійної регресії такі оцінки мають назву BLUE-оцінки.
Передумови застосування методу найменших квадратів
1. Гомоскедастичність залишків: Дисперсія залишків не залежить від незалежної змінної, тобто D(ei)=var(ei)=σ2 – const.
2. Незалежність залишків: cov(eiej)=0, для всіх i ≠ j.
3. Незалежність залишків та незалежної змінної: cov(eixj)=0, для всіх i, j.
4. Залишки нормально розподілені для всіх і.
Примітка: тут та далі оператор cov(x,y) означає операцію обчислення коваріації між двома випадковими змінними x та y, а оператор var(x) – операцію обчислення дисперсії від випадкової змінної х.
Теорема Гауса Маркова:
Для парної лінійної регресії з гомоскедастичними, некорельованими збуреннями оцінки МНК мають найменшу дисперсію в класі всіх лінійних незміщених оцінок.
Статистичні властивості оцінок МНК
- Математичне очікування залишків дорівнює нулю, M(ei)=0
- M(b 0)=β0;
- M(b 1)=β1;
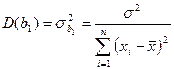 ;
;
5. 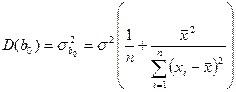 ;
;
де 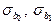 – стандартне відхилення оцінок параметрів регресії b 1 та b 0 відповідно;
– стандартне відхилення оцінок параметрів регресії b 1 та b 0 відповідно;
s2 – дисперсія залишків регресійної моделі. На практиці значення s2 замінюють її оцінкою 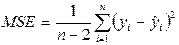 .
.
Коефіцієнт еластичності
Середній коефіцієнт еластичності 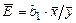 показує наскільки відсотків у середньому зміниться значення у при зміні змінної х на 1 відсоток від свого середнього значення.
показує наскільки відсотків у середньому зміниться значення у при зміні змінної х на 1 відсоток від свого середнього значення.
2. Загальна модель багатофакторної лінійної регресії
Загальна багатофакторна лінійна регресійна модель, що відображає залежність якогось економічного показника (y) від деякої множини економічних факторів (x 1, x 2, … xm) може бути записана у такому вигляді:
y = M(y|x 1, x 2, … xm) + ε i,= β0+ β1 x 1+ β2 x 2 + … + β mxm + ε, (7.4)
де y – залежна змінна (економічний показник),
x 1, x 2, … xm – незалежні змінні (економічні фактори),
β i – параметри моделі,
ε – неспостережна випадкова величина,
M(y|x 1, x 2, … xm) = β0+ β1 x 1+ β2 x 2 + … + β mxm – умовне математичне очікування залежної змінної y, при умові, що незалежні змінні прийняли відповідні значення, тобто регресія y на x 1, x 2, … xm.
Припустимо, що ми маємо деяку вибірку (таблицю) розмірністю n спільних значень m +1 економічних показників, один з яких приймається лінійно залежним від решти m незалежних змінних x 1,…, xm. Моделі (7.4) ставиться у відповідність вибіркова модель, яка будується для певної вибірки. Невідомі статистики вибіркової моделі є випадковими величинами, математичне очікування яких дорівнює параметрам узагальненої моделі. Вибіркова модель лінійної багатофакторної регресії має такий вигляд:
yi = b0+ b1 x 1 i + b2 x 2 i + … + b mxmi + ei, (7.5)
де b i – оцінки невідомих параметрів β i; ei – вектор випадкових величин (залишків) моделі.
Для отримання оцінок b i застосуємо МНК на випадок багатофакторної регресії. З цією метою визначимо ряд передумов МНК.
Основні передумови в багатофакторному регресійному аналізі.
1. M(εi) = 0. Математичне очікування випадкової величини ε дорівнює 0.
2. cov(εi, εj)=0 i¹j. Випадкові величини незалежні між собою. Відсутність автокореляції
3. var(εi,)=s2=const для всіх xi , умова гомоскедастичності.
4. cov(εi, xjk)=0 " i, j; k= 1,…, m. Независимость возмущений и регрессоров
5. Випадкова величина ε має нормальний закон розподілу.
6. Відсутність мультиколінеарності.
2.1. Матричний підхід до багатофакторної лінійної регресії
Вибірку залежної змінної yi представимо у виді вектора Y розмірністю (n´1). Аналогічно визначимо вектор E залишків моделі розмірністю (n´1)
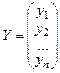 ;.
;.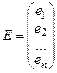
Вибірка незалежних змінних може бути представлена як матриця розмірністю (n´m). Але, для того щоб вибіркову модель лінійної багатофакторної регресії (7.5) подати в загальному вигляді з урахуванням коефіцієнта b0, введемо додаткову незалежну змінну х0, всі значення якої у вибірці будуть дорівнювати 1. Коефіцієнтом пропорційності при цій змінній і буде параметр b0. У цьому разі матриця Х доповнюється стовпчиком, який складається з одиниць. Якщо коефіцієнт перетину b0 у багатофакторній моделі не визначається, то стовпчик з одиницями у матриці Х, повинен бути відсутнім. Таким чином матриця Х розмірністю [n´(m+1)] та вектор B оцінок параметрів моделі розмірністю [(m+1)´1] можуть бути представлені наступним чином.
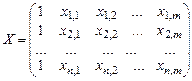 ;
; 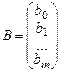 . (7.6)
. (7.6)
У цьому випадку вираз (7.5) може бути представленим у матричному вигляді
Y = XB + E
Умова мінімуму сіми квадратів залишків в матричному вигляді набуває виду
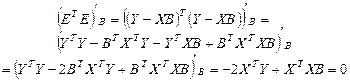 (7.7)
(7.7)
Рішенням системи (7.7) буде
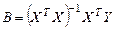
Властивості оцінок параметрів регресії, отриманих за допомогою МНК
- M(b i)=βi;
- Для характеристики отриманих значень оцінок bi, поряд з математичним очікуванням застосовуються також їх дисперсії
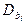 і коваріації кожної пари оцінок
і коваріації кожної пари оцінок 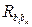 Усі ці характеристики економетричної моделі утворюють дисперсійно-коваріаційну матрицю
Усі ці характеристики економетричної моделі утворюють дисперсійно-коваріаційну матрицю
 (7.8)
(7.8)
Оцінки коваріаційної матриці 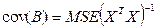 використовуються для знаходження стандартних помилок та обчислення довірчих інтервалів оцінок параметрів bi. Вони використовуються й при перевірці їх статистичної значущості. На головній діагоналі матриці
використовуються для знаходження стандартних помилок та обчислення довірчих інтервалів оцінок параметрів bi. Вони використовуються й при перевірці їх статистичної значущості. На головній діагоналі матриці 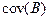 містяться оцінки дисперсій , а недіагональні елементи
містяться оцінки дисперсій , а недіагональні елементи 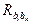 (i ¹ k) є оцінками коваріації між bi та bk. У виразі (7.8) MSE — незміщена оцінка дисперсії залишків, яка на випадок багатофакторної регресії визначається виразом (7.9).
(i ¹ k) є оцінками коваріації між bi та bk. У виразі (7.8) MSE — незміщена оцінка дисперсії залишків, яка на випадок багатофакторної регресії визначається виразом (7.9).
Після того, як отримані оцінки параметрів регресії bi, можна отримати значення вектору залишків та визначити їх властивості:
E = Y – XB
2.2. Аналіз дисперсій
Визначення числа степенів вільності
Кожна сума квадратів пов'язана з числом, яке називається «степінь вільності». В статистиці кількістю степенів вільності певної величини часто називають різницю між кількістю різних дослідів і кількістю констант, уже визначених в результаті цих дослідів.
1. Визначення сум квадратів SST=SSR+SSE, де
§ Загальна сума квадратів визначається виразом
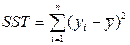 ,
,
і має n–1 степінь вільності, оскільки один степінь вільності використовується на визначення середнього значення залежної змінної у.
§ Сума квадратів залишків визначається виразом
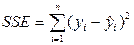
і має n-m-1 степінь вільності, оскільки (m +1) степінь вільності використовується на визначення оцінок параметрів регресії bi.
§ Сума квадратів регресії визначається виразом

і має m степенів вільності, оскільки вона визначається через m незалежних параметрів b i.
2. Визначення середніх квадратів
MSR=SSR/m;
MSE=SSE/ (n-m- 1). (7.9)
3. Коефіцієнт детермінації
R 2= SSR/SST.
Коефіцієнт детермінації змінюється в діапазоні 0≤ R 2≤1.
Коефіцієнт детермінації є кількісною мірою сили зв'язку між залежною та незалежною змінною. Чим сильніший зв'язок, тим ближче коефіцієнт детермінації до одиниці. І, навпаки, при відсутності лінійного зв'язку коефіцієнт детермінації наближається до нуля. Таким чином, якщо розраховане значення коефіцієнта детермінації наближається до одиниці, можна стверджувати про адекватність регресійної моделі. Якщо розраховане значення коефіцієнта детермінації наближається до нуля, то модель не адекватна; тобто між залежною і незалежною змінними відсутня лінійна залежність.
Коефіцієнт детермінації є простою і досить надійною мірою оцінки адекватності регресійної моделі. Але він мало прийнятний у цій якості при його значеннях близьких до 0,5. Більш конкретним у цьому випадку є критерій Фішера.
2.3. Верифікація моделі
Перевірка моделі на адекватність за F-критерієм Фішера
Досить часто виникає потреба перевірити, чи мають дві незалежні випадкові величини однакову дисперсію. Якщо вони мають однакову дисперсію, то ми можемо стверджувати, що ці випадкові величини породжені одним і тим самим випадковим процесом і не відрізняються одна від одної.
Перевірка відмінності дисперсій двох генеральних сукупностей заснована на дослідженні їх відношення. Встановлено що, якщо кожна генеральна сукупність є нормально розподіленою, відношення їх вибіркових дисперсій S12/S22 підкоряється F-розподілу, який ще називається розподілом Фішера.
Розподіл Фішера визначає щільність ймовірності відношення вибіркових дисперсій (сум квадратів) двох вибірок, які мають відповідно обсяги n 1 та n 2, відібраних з однієї генеральної сукупності, що мають дисперсію σ2.
Критичне значення F-розподілу залежить від двох множин степенів вільності. Степені вільності чисельника відносяться до першої вибірки, а степені вільності знаменника – до другої. Для перевірки рівності двох дисперсій у статистичному відношенні в критерії використовується F-статистика:
F=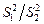 ,
,
де 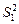 и
и 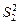 - дисперсии выборок з першої та другої генеральних сукупностей, n 1, n 2 – обсяги вибірок з першої та другої генеральних сукупностей відповідно, n 1 – 1 и n 2 – 1 кількість степенів вільності чисельника та знаменника відповідно.
- дисперсии выборок з першої та другої генеральних сукупностей, n 1, n 2 – обсяги вибірок з першої та другої генеральних сукупностей відповідно, n 1 – 1 и n 2 – 1 кількість степенів вільності чисельника та знаменника відповідно.
F -статистику можна розглядати також як відношення оцінок дисперсій двох незалежних випадкових процесів, і тому на практиці F – розподіл Фішера найчастіше використовується для тестування рівності цих оцінок дисперсій.
Так для лінійної регресії статистична рівність оцінок дисперсій MSR і MSE за критерієм Фішера свідчить про те що детермінована частина загальної суми квадратів з заданою вірогідністю не буде відрізнятись від частини загальної суми квадратів, що визначається випадковою складовою.
Тестування за критерієм Фішера значущості впливу на залежну змінну y незалежнних змінних xi або адекватності моделі складається з наступних етапів:
Формулюється ноль-гіпотеза
Н0: β1 = …= βm = 0,
(тобто гіпотеза про те, що всі параметри регресії дорівнюють нулю)
проти альтернативної гіпотези
Н1: хоча б одне значення β i ¹0,
Гіпотеза Н0 приймається з рівнем надійності 1–α, якщо розраховане значення відношення
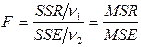
менше Fкр = Fзвор (1 -α, ν1, ν2) – критичне значення розподілу Фішера з ν1 = m та ν2 = n-m- 1 степенями вільності і рівнем надійності (1 - α)100%.
Якщо F > Fкр то Н0 гіпотеза відкидається і приймається гіпотеза Н1.
Критичне значення розподілу Фішера визначається за таблицями, або обчислюється за допомогою стандартних функцій, що існують у різних програмних середовищах. В Excel це функція FРАСПОБР.
Гіпотеза про значимість одного з коефіцієнтів регресії
Нуль-гіпотеза Н0: β i = 0, проти альтернативної гіпотези Н1: β i ¹0 приймається з рівнем надійності (1–α), якщо практичне значення статистики Ст'юдента: 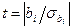 менше табличної статистики t кр = t звор (1-α, n-m -1) з n-m- 1 степенями вільності, яке визначається з таблиці, або за допомогою стандартної функції (у Excel це функція СТЬЮДРАСПОБР)
менше табличної статистики t кр = t звор (1-α, n-m -1) з n-m- 1 степенями вільності, яке визначається з таблиці, або за допомогою стандартної функції (у Excel це функція СТЬЮДРАСПОБР)
Якщо t > tкр, то нуль-гіпотеза відкидається, і приймається гіпотеза Н1, що коефіцієнт β i в багатофакторній регресії статистично значимий, тобто змінна y залежить від незалежної змінної xi.
Інтервальні оцінки коефіцієнтів регресії
Використовуючи отримані статистики регресії bi та їх середні квадратичні відхилення 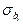 , можна обчислити інтервали, всередині яких з заданою вірогідністю (надійністю) будуть знаходитись значення параметрів регресії β i. Довірчі інтервали з надійністю (1–α)100% для кожного з коефіцієнтів регресії β i визначаються з використанням табличної статистики Ст'юдента t кр = t звор (1-α, n-m -1) наступним чином:
, можна обчислити інтервали, всередині яких з заданою вірогідністю (надійністю) будуть знаходитись значення параметрів регресії β i. Довірчі інтервали з надійністю (1–α)100% для кожного з коефіцієнтів регресії β i визначаються з використанням табличної статистики Ст'юдента t кр = t звор (1-α, n-m -1) наступним чином:
b і:[ bi - 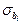 × t кр; bi + × t кр ]
× t кр; bi + × t кр ]
де 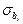 є коренем квадратним відповідного діагонального елемента коваріаційної матриці, що визначається виразом (7.8).
є коренем квадратним відповідного діагонального елемента коваріаційної матриці, що визначається виразом (7.8).
Визначення довірчого інтервалу для умовного середнього значення ŷ генеральної сукупності
Для визначення умовного середнього значення залежної змінної у при заданих значеннях вектора незалежних змінних Хпр, користуються наступним виразом
ŷ 0 = b0+ b1 x 1, пр + b2 x 2, пр + … + b mxm,пр = BХпр
Довірчий інтервал для умовного середнього значення генеральної сукупності визначається при заданих значеннях вектора незалежних змінних Хпр
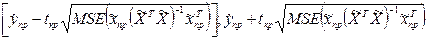 ,
,
де 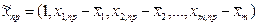 – вектор-рядок центрованих координат точки, в якій здійснюється прогнозування,
– вектор-рядок центрованих координат точки, в якій здійснюється прогнозування,
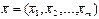 - вектор середніх значень незалежних змінних. Під операцією центрування ми будемо розуміти операцію віднімання від кожного з заданих значень незалежних змінних відповідних середніх значень;
- вектор середніх значень незалежних змінних. Під операцією центрування ми будемо розуміти операцію віднімання від кожного з заданих значень незалежних змінних відповідних середніх значень;
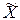 - матриця центрованих незалежних змінних;
- матриця центрованих незалежних змінних;
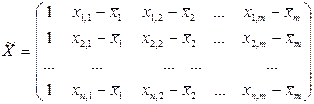
Зокрема для парної лінійної регресії цей вираз матиме вигляд:
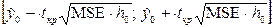 ,
,
де 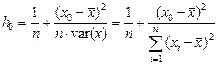 .
.
2.4. Прогнозування за допомогою багатофакторної регресійної моделі
Довірчий інтервал для прогнозу реального значення залежної змінної з рівнем надійності (1–α) визначається як
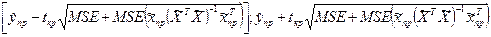 ,
,
Зокрема для парної лінійної регресії довірчий інтервал для отриманого прогнозного значення ŷ 0 визначається наступним чином
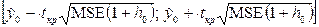
|
|
|
|
Дата добавления: 2014-01-04; Просмотров: 1131; Нарушение авторских прав?; Мы поможем в написании вашей работы!