КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Собственные внутримашинные информационные ресурсы предприятия
|
|
|
|
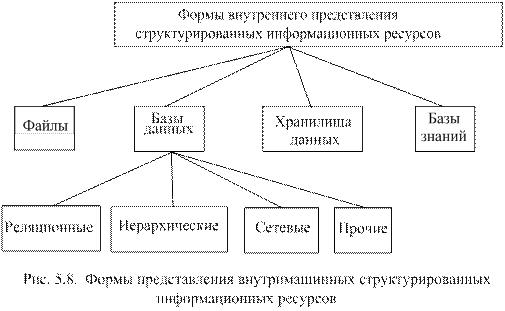
Внутримашинные структурированные информационные ресурсы – это множество бумажных управленческих документов, а также информации поступающей из вне, размещаемых в памяти компьютера в соответствии с некоторой моделью. Структуризация достигается благодаря модели, так как устанавливаются правила размещения данных и определяются возможные операции над ними. Формы внутримашинного представления информационных ресурсов иллюстрируются с помощью рис. 5.8.
Наиболее распространенными формами существования внутримашинных информационных вопросов являются:
- файлы;
- базы данных;
- хранилища данных;
- базы знаний.
Исторически первой среди перечисленных форм появилась файловая организация данных, ориентированная на обработку с помощью языков программирования под управлением какой-либо операционной системы. Файл – это последовательное отображение однородных управленческих документов на машинном носителе в виде записей. Запись отражает один документ, либо его строку, если документ многострочный. Запись состоит из полей, в которых находятся реквизиты документа (коды поставщиков, даты, суммы и т.д.).
Для обработки файл должен характеризоваться структурой, то есть:
- именем для его поиска;
- количеством полей в записи;
- последовательностью фиксации полей в записи;
- типом записи (постоянная или переменная длина записи);
- типом поля (символьное или числовое);
- длиной поля (количество разрядов);
- ключом доступа;
Ключи доступа могут быть первичными и вторичными. Они используются для поиска нужных записей. Ключ называется первичным, если с его помощью отыскивается одна запись и вторичным, если больше одной.
Для обращения каждый файл должен иметь имя (не более 8 символов) и расширение, уточняющее его назначение: EXE, COM – программные файлы, готовые к использованию, DBF – файлы базы данных, DOC, TXT – текстовые файлы и т.д. По содержанию выделяют: файлы данных и программные файлы.
Однако файловая система обладает рядом серьезных недостатков, первый из которых - это чрезмерная избыточность данных, являющаяся причиной возрастания затрат на их корректировку, а второй - это высокая зависимость прикладных программ от изменения структуры файлов.
Вслед за файлами появились базы данных, которые в определенной степени снижали остроту перечисленных недостатков. Главная особенность баз данных, существенно отличающая их от баз файловой системы, состоит в их ориентации на интерактивный режим работы с ними конечного пользователя (бухгалтера, финансиста, менеджера и т.д.). Понятие «персональный компьютер» появилось, во многом благодаря базам данных.
Широкое применение баз данных не профессионалами-программистами стало возможным благодаря специально созданному программному комплексу – системам управления базами данных (СУБД). Появление СУБД избавило пользователей от знания значительного объема тонкостей, связанных с решением экономических задач.
Дальнейшее развитие баз данных привело к появлению хранилищ данных, назначение которых отлично от баз данных. Если последние предназначены для оперативного отражения ежедневных производственно-хозяйственных, финансовых и других операций предприятия, то хранилища данных необходимы для долговременного хранения данных в специально создаваемых многомерных информационных кубах. Информационные кубы предназначены исключительно для аналитической обработки данных и формирования решений. Сегодня хранилища данных становятся неотъемлемой частью средств, необходимых для принятия корпоративных и других решений.
Знания также как и данные являются информационным ресурсом и хранятся в компьютере в соответствии с разработанной моделью. В результате получают базу знаний. Работа с базами знаний – это одно из направлений искусственного интеллекта, целью которого является разработка инструментальных средств, позволяющих решать задачи, традиционно считающиеся интеллектуальными.
Существуют различные модели представления знаний, среди которых наиболее популярными являются:
- продукционные модели (деревья вывода);
- семантические сети (ассоциативные сети),
- деревья целей;
- нечеткие множества.
Так как любая модель, и в том числе модель представления знаний, формальна, поэтому могут создаваться программные средства для их обработки. Знания, как и прочие формы представления информации, устаревают или становятся ненужными, поэтому должна быть система управления ими. Система управления знаниями (СУЗ) это совокупность программных средств, обеспечивающих поиск, ввод, обработку, использование и корректировку знаний.
9. Базы данных и их применение для решения
экономических задач
База данных – это ориентированное на пользователя-непрограммиста множество взаимосвязанных данных, структурированных таким образом, что достигается их минимальная избыточность и максимальная независимость от прикладных программ.
Данные в базе находятся в памяти в соответствии с некоторой моделью. Распространенными моделями баз данных являются: реляционная, сетевая и иерархическая. Так как в процессе управления предприятиями и организациями широко используются таблицы, поэтому наиболее распространенной моделью баз данных в настоящее время является реляционная модель.
Реляционная модель основывается на понятии “отношение”, и представляется совокупностью таблиц. На рис. 5.9 приведены базовые понятия данной модели.
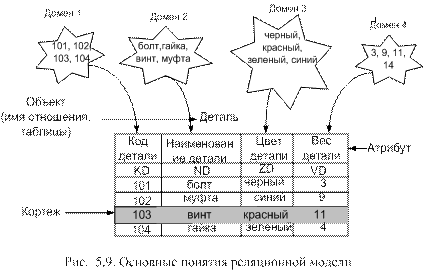
Домен – это множество значений, принимаемых свойствами (характеристиками) отражаемого объекта.
Атрибут – это имя множества значений, входящих в домен. Атрибуты используются в качества средства для обращения к доменам.
Кортеж – это множество элементов из доменов, составляющих одну строку отношения (таблицы).
Отношение – это множество кортежей, отражающих свойства объекта.
Таблицы, входящие в реляционную модель, строятся в рамках ограничений, диктуемых операциями их обработки. Это следующие ограничения:
- таблица должна иметь имя (например, ДЕТАЛЬ, ПОСТАВЩИК,
ПОСТАВКИ);
- таблица должна быть простой, то есть не содержать составных столбцов, например, у поставщика должен быть только один номер телефона, указанный в одной строке;
- в таблице не должно быть одинаковых строк;
- должен быть известен первичный ключ, используемый для поиска или выполнения других логических операций.
Таблицы реляционной модели обрабатываются с помощью операций реляционной алгебры. Выделяют три основных операций: ВЫБОРКА, ПРЕКЦИЯ, СОЕДИНЕНИЕ. Операцию ВЫБОРКА продемонстрируем с помощью базы данных ПОСТАВКИ, представленной на рис. 5.10.
ПОСТАВКИ
| Код поставщика | Код детали | Количество (шт.) |
| КР | KD | Q |
| П1 | ||
| П1 | ||
| П2 | ||
| П3 | ||
| П3 | ||
| П4 | ||
| П4 |
Рис. 5.10. База данных «ПОСТАВКИ»
Данный оператор применяется к одной таблице. В результате получают новую таблицу, в которой находятся лишь те строки, которые удовлетворяют заданному условию. Общая форма оператора, используемого СУБД, имеет вид:
ВЫБОРКА ИЗ <имя исходной таблицы>
ГДЕ <условие>
ПОЛУЧАЯ <имя результирующей таблицы>
Допустим, из базы данных ПОСТАВКИ необходимо выбрать тех поставщиков, которые поставляли детали с кодом 101.
Заполнив общую форму оператора получим:
ВЫБОРКА ИЗ ПОСТАВКИ
ГДЕ KD = 101
ПОЛУЧАЯ ПОСТАВЛЕННЫЕ ДЕТАЛИ
В результате будет получена таблица, представленная на рис. 5.11.
ПОСТАВЛЕННЫЕ ДЕТАЛИ
| Код поставщика | Код детали | Количество (шт.) |
| КР | KD | Q |
| П1 | ||
| П2 | ||
| П4 |
Рис. 5.11. Результат выполнения оператора «ВЫБОРКА»
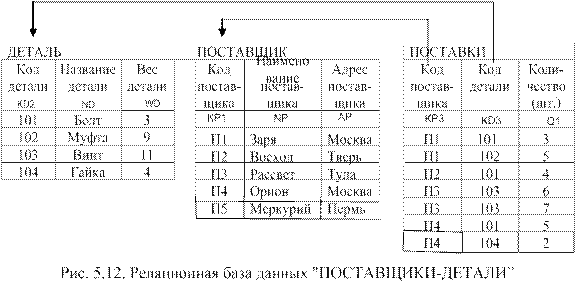
Для обработки нескольких таблиц устанавливаются связи. Связи между первичными ключами, то есть теми атрибутами таблиц, которые однозначно определяют их строки, определяются с помощью указателей. На рис. 5.12 эти связи указаны с помощью стрелок.
Для объединения таблиц используется оператор СОЕДИНЕНИЕ, общий вид которого следующий:
СОЕДИНЕНИЕ <имя таблицы 1> И <имя таблицы 2>
ПО <атрибут таблицы 1> и <атрибут таблицы 2>
ПОЛУЧАЯ<имя результирующей таблицы>
Допустим необходимо для расшифровки кодов поставщиков в таблице ПОСТАВЛЕННЫЕ ТОВАРЫ (рис. 5.11) соединить ее с таблицей ПОСТАВЩИК (см. рис.5.12). Тогда данный оператор приобретает вид:
СОЕДИНЕНИЕ ПОСТАВЛЕННЫЕ ТОВАРЫ И ПОСТАВЩИК
ПО KP B KP1
ПОЛУЧАЯ ПОСТАВЩИКИ ДЕТАЛЕЙ
На рис. 5.13 представлены результаты выполнения оператора СОЕДИНЕНИЕ.
ПОСТАВЩИКИ ДЕТАЛЕЙ
| Код поставщика | Код детали | Количество | Код поставщика | Наименование поставщика | Адрес поставщика |
| KP | KD | Q | KP1 | NP | AP |
| П1 | П1 | Заря | Москва | ||
| П2 | П2 | Восход | Тверь | ||
| П3 | П3 | Рассвет | Тула |
Рис. 5.13. Результат выполнения оператора «СОЕДИНЕНИЕ»
Теперь рассмотрим, каким образом в базе данных ликвидируются недостатки, присущие файловой системе.
Согласно приведенному выше определению базы данных должны создаваться таким образом, чтобы выполнялось два условия:
- достигался минимум затрат на корректировку данных;
- достигался минимум затрат на перепрограммирование, необходимое в случае изменения структуры базы данных (добавление новых или сокращение старых атрибутов).
Для удовлетворения этих условий базы данных создаются на основе двух принципов:
- неизбыточность;
- независимость.

Требование первого принципа означает сокращение до минимума объема дублируемых данных. Для этого над таблицами выполняют процедуру нормализации. Пусть имеется ненормализованная таблица СЛУЖАЩИЙ-НАЧАЛЬНИК-ТЕЛЕФОН, в которой имеется излишне дублируемые данные (см. рис. 5.14). Для их ликвидации данная процедура требует деления исходной таблицы таким образом, чтобы в результате получились более простые таблицы.
Существует несколько уровней ликвидации дублирования данных – чем выше уровень, тем меньше дублирования. Первый уровень соответствует 1-й нормальной форме Кодда (1НФ), 2-й уровень – 2-й нормальной форме Кодда и третий уровень – 3-й нормальной форме Кодда (уровни названы в честь их создателя). Целесообразный уровень зависит от специфики информации, находящейся в базе данных. В результате нормализации избыточные номера телефонов (3051, 2222) из таблицы НАЧАЛЬНИК исчезли, так как получен достаточно высокий уровень нормализации (3-я нормальная форма Кодда).
Реализация второго принципа, требует максимальной независимости прикладных программ от структуры базы данных. Независимость достигается за счет отделения процедурной части программы от описания структуры базы данных. Отделение происходит с помощью системы управления базами данных (СУБД). СУБД – это комплекс программ, предназначенный для создания и хранения базы данных, обеспечения логической и физической целостности данных, предоставления санкционированного доступа конечных пользователей.
Иерархические и сетевые модели баз данных имеют более сложную структуру и для выдачи нужных отчетов содержат свои наборы селекционных, навигационных и иных операций.
Существует несколько режимов взаимодействия пользователей СУБД:
- режим конечного пользователя с применением конструктора баз данных и запросов;
- программный режим, предполагающий знание пользователем языка СУБД и позволяющий создавать прикладные программы.
Конечный пользовать, как правило, пользуется конструктором, с помощью которого задается структура БД, формулы для расчетов и структура отчета. Достаточно популярной СУБД для данного класса является MS Access.
Программный режим предполагает создание программ с помощью программистов-профессионалов.
Профессиональные (промышленные) СУБД представляют собой программную основу для создания и функционирования крупных экономических объектов. На их базе создаются комплексы управления и обработки информации на крупных предприятиях, банках или даже целых отраслей.
|
|
|
|
Дата добавления: 2014-01-06; Просмотров: 1569; Нарушение авторских прав?; Мы поможем в написании вашей работы!