КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Получение случайных чисел с заданным законом распределения
|
|
|
|
Псевдослучайные числа могут быть использованы в качестве исходного материала для моделирования любых вероятностных объектов (случайные события и связанные с ними процессы).
Пусть, например, событие А имеет вероятность Р(А), тогда процедура его моделирования с помощью равномерно распределенных в интервале (0, 1) чисел производится так:
1) Выбирается очередное случайное число xi.
2) Проверкой неравенства xi £ Р(А) устанавливается принадлежность этого числа отрезку [0, Р(А)]. Если неравенство выполнено, то говорят, что событие А наступило, в противном случае – не наступило.
Аналогично выглядит процедура моделирования на ЭВМ дискретной случайной величины с заданным законом распределения:

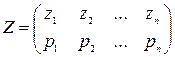
Разобьем интервал (0, 1) на n интервалов, длины которых выберем равными р1, р2, …, рn.
 |

Координаты точек 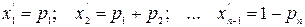
Моделирование сводится к следующему: для получения очередного значения Z вырабатывается очередное xi и при попадании его в j -ый интервал считается, что Z приняло значение Zj.
Все разнообразие методов получения случайных чисел можно разделить на 2 группы: точные и приближенные методы.
Пусть равномерно распределенная в интервале (0, 1) величина X получается из случайной величины Y с помощью неслучайной функции h(y), тогда очевидно неравенство:
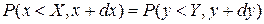 .
.
Выражая левую и правую части через соответствующие плотности распределения и учитывая, что f(x)=1, получаем:
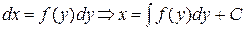 .
.
Учитывая далее, что по определению 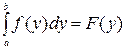 , где а – произвольное число, F(y) – интегральная функция распределения случайной величины Y. Кроме того, очевидно, что F(a)=0.
, где а – произвольное число, F(y) – интегральная функция распределения случайной величины Y. Кроме того, очевидно, что F(a)=0.
Найдем окончательно вид функции h(y) = F(y), совпадающее с интегральным законом. Для получения очередного значения yi случайной величины Y, распределенной в интервале (a, b) с законом распределения f(y) соответствующего значению xi необходимо решить уравнение:
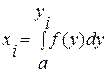 (1).
(1).
Пример. Пусть необходимо получить случайные числа с последовательным законом распределения, т.е. 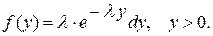 используя соотношение (1), имеем:
используя соотношение (1), имеем:
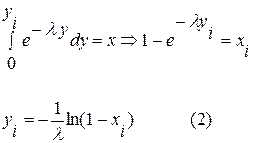
Можно привести другие примеры использования выражения (1). Однако, подобная методика находит ограниченное применение благодаря двум обстоятельствам:
1) Для многих законов распределения интеграл правой части уравнения (1) в конечном виде не берется, например, нормальный закон.
2) Даже когда интеграл (1) удается взять в конечном виде, формулы получаются слишком громоздкими, требующими больших затрат машинного времени, поэтому используют приближенные методы.
Рассмотрим один из универсальных приближенных способов.
Пусть закон распределения случайной величины Y, предложенной для моделирования, задан функцией плотности f(y), возможные значения которой в интервале (a, b). Если этот интервал с бесконечными границами, то целесообразно перейти к усеченному распределению, оставив лишь существенную часть.
Представим f(y) на участке (a, b) в виде кусочно-постоянной функции, т.е. разобьем (a, b) на n интервалов и будем считать f(y) на каждом интервале постоянной, тогда случайную величину Y можно представить в виде: Y=ak + Xk, т.е. на каждом участке (ak, ak+1) величина Xk считается распределенной равномерно (см. рисунок).
 |
Чтобы аппроксимировать f(y) наиболее удобным способом целесообразно разбить (a, b) на интервалы таким образом, чтобы вероятность попадания случайной величины Y в любой интервал (ak, ak+1) была постоянной, т.е. не зависела от номера интервала k. Для вычисления пользуются следующим соотношением: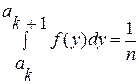 , где n – количество интервалов обычно принимаемое равным 2m, где m – целое положительное число.
, где n – количество интервалов обычно принимаемое равным 2m, где m – целое положительное число.
Процедура моделирования предполагает следующее:
1) Выбирается случайное равномерно распределенное число xi.
2) С помощью xi выбирается интервал (ak, ak+1).
3) Берется следующее равномерно распределенное число xi+1 и масштабируется с целью приведения к интервалу (ak, ak+1), т.е. xi+1 становится случайной величиной, равномерно распределенной в интервале (ak, ak+1). Случайное число yi с требуемым законом распределения находится по формуле: yi = ak + xi+1 (ak+1 - ak).
Рассмотрим процесс выборки интервала (ak+1 - ak) с помощью xi. Случайное число xi получается на ЭВМ в виде последовательности 0 и 1. Если m – разрядность двоичного числа, то всего чисел будет 2m и каждому интервалу (ak+1 - ak) можно поставить в соответствие только одно двоичное число, что значительно упрощает процедуру выбора интервала (ak+1 - ak).
Для реализации данного метода на ЭВМ требуется небольшое количество операций, причем число операций не зависит от точности аппроксимации, т.е. от количества интервалов n. Точность аппроксимации (количество n) влияет только на размеры участка памяти, куда помещается таблица закодированных значений ak. Этот способ находит широкое распространение в практике имитационного моделирования.
Метод Неймана (разыгрывания случайной величины)
Д. Нейман предложил способ получения заданного закона распределения, не требующий решения интегрального уравнения (1) и в то же время являющийся точным, т.е. не использующим никаких приближений.
Метод основан на имитационном моделировании закона распределения. Суть его сводится к следующему.
Пусть X распределена на интервале (a, b) и моделируемая плотность ограничена: f(x)£M0. Выбираем два значения g1 и g2, равномерно распределенных в интервале (0, 1) случайной величины g и на плоскость (x, f(x)) наложим точку N с координатами: a=a + g1 (b-a); b=g2 M0.
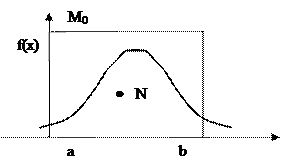 |
Если точка N лежит под кривой, то разыгранное полученное значение X считается равным a. Если точка оказалась под кривой, то пару g1, g2 отбрасывают и выбирают новую пару g3 и g4.
Покажем, что указанный алгоритм приводит к закону f(x). Случайная точка N равномерно распределена в прямоугольнике с площадью (b-a)´M0.
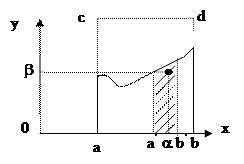 |
Вероятность того, что точка N окажется ниже прямой f(x) равна отношению:
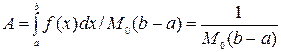
Вероятность того, что точка окажется под кривой f(a) и окажется внутри интервала (a’, b’) выражается соотношением:
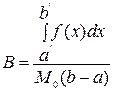 .
.
Следовательно, среди всех отобранных (перешедших в X) a доля попавших в интервал (a’, b’) равна частному:
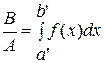 .
.
Если же вероятность того, что P(a’ £ X £ b’) находится через плотность f(x), то это значит, что X имеет плотность f(x).
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 1246; Нарушение авторских прав?; Мы поможем в написании вашей работы!