КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Міри подібності
|
|
|
|
Для проведення класифікації необхідно ввести поняття подібності об'єктів за спостережуваними змінними. У кожен кластер (клас, таксон) повинні потрапити об'єкти, що мають подібні характеристики.
У кластерному аналізі для кількісної оцінки подібності вводиться поняття метрики. Подібність або розходження між класифікованими об'єктами встановлюється залежно від метричної відстані між ними. Якщо кожен об'єкт описується k ознаками, то він може бути представлений як точка в k-вимірному просторі, і подібність з іншими об'єктами буде визначатися як відповідна відстань. У кластерному аналізі використовуються різні міри відстані між об'єктами:
евклідова відстань: 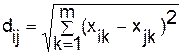 ; (7.1)
; (7.1)
зважена евклідова відстань: 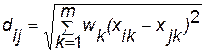 ; (7.2)
; (7.2)
відстань cite-blok: 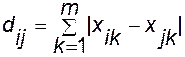 ; (7.3)
; (7.3)
відстань Мінковського: 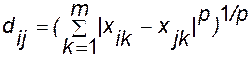 ; (7.4)
; (7.4)
відстань Махаланобіса: dij = (Xi-Xj)’S-1 * (Xi-Xj). (7.5)
де dij — відстань між i-м та j-м об'єктами;
xil, xjl — значення l-ї змінної відповідно i-го та j-го об'єктів;
Хi, Xj — вектори значень змінних у i-го та j-го об'єктів,
S — загальна ковариаційна матриця;
wk — вага k -ї змінної.
Оцінка подібності між об'єктами сильно залежить від абсолютного значення ознаки і від ступеня його варіації в сукупності. Щоб усунути подібний вплив на процедуру класифікації, можна значення вихідних змінних нормувати.
Якщо алгоритм кластеризації заснований на вимірі подібності між змінними, то як міри подібності можуть бути використані:
лінійні коефіцієнти кореляції;
коефіцієнти рангової кореляції;
коефіцієнти контингенції.
Залежно від типів вихідних змінних вибирається один з видів показників, що характеризують близькість між ними.
Існують такі групи методів кластерного аналізу:
1) ієрархічні методи;
2) ітеративні методи;
3) факторні методи;
4) методи згущень;
5) методи, що використовують теорію графів.
До найбільш розповсюджених в економіці відносять ієрархічні й ітеративні.
Сутність ієрархічних агломеративних методів полягає в тому, що на першому кроці кожен об'єкт вибірки розглядається як окремий кластер. Процес об'єднання кластерів відбувається послідовно: на підставі матриці відстаней або матриці подібності поєднуються найбільш близькі об'єкти. Якщо матриця подібності спочатку має розмірність т х т, то цілком процес кластеризації завершується за т- 1 кроків, у підсумку всі об'єкти будуть об'єднані в один кластер. Послідовність об'єднання легко піддається геометричній інтерпретації і може бути представлена у вигляді графи-дерева (дендрограми).
Безліч методів ієрархічного кластерного аналізу розрізняється не тільки використовуваними мірами подібності (розходження), але й алгоритмами класифікації. З них найбільш поширені: метод одиночного зв'язку, метод повних зв'язків, метод середнього зв'язку, метод Уорда.
Метод одиночного зв'язку. Алгоритм утворення кластерів наступний: на підставі матриці подібності (розходження) визначаються два найбільш схожі або близьких об'єкти, вони й утворять перший кластер. На наступному кроці вибирається об'єкт, що буде включений у цей кластер. Таким об'єктом буде той, котрий має найбільшу подібність хоча б з одним з об'єктів, уже включених у кластер.
За умови збігу даних на підставі однакових мір подібності (розходження) буде йти утворення відразу декількох кластерів.
До достоїнств цього методу варто віднести нечутливість алгоритму до перетворень вихідних змінних і його простоту. Недоліками є необхідність постійного збереження матриці подібності і неможливість визначення за результатами кластеризації, скільки ж кластерів можна утворити в досліджуваній сукупності об'єктів.
Метод повних зв'язків. Включення нового об'єкта у кластер відбувається тільки в тому випадку, якщо відстань між об'єктами не менше деякого заданого рівня.
Метод середнього зв'язку. Для рішення питання про включення нового об'єкта в уже існуючий кластер обчислюється середнє значення міри подібності, що потім порівнюється з заданим граничним рівнем.
Якщо мова йде про об'єднання двох кластерів, то обчислюють відстань між їхніми центрами і порівнюють її з заданим граничним значенням.
Метод Уорда. Цей метод зумовлює, що на першому кроці кожний кластер складається з одного об'єкта. Спочатку об’єднуються два найближчих кластера. Для них визначається середнє значення кожної ознаки та розраховується додаток квадратів відхилень V k:
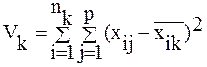 , (7.6)
, (7.6)
де k — номер кластера;
i — номер об’єкта;
j — номер ознаки;
р — кількість ознак, що характеризують кожен об'єкт;
nk — кількість об'єктів у k-му кластері.
Надалі на кожному кроці роботи алгоритму поєднуються ті об'єкти або кластери, що дають найменше збільшення величини V k. Метод Уорда приводить до утворення кластерів приблизно рівних розмірів з мінімальною усередині кластерною варіацією. У підсумку всі об'єкти виявляються об'єднаними в один кластер.
Міра подібності для об'єднання двох кластерів визначається чотирма методами:
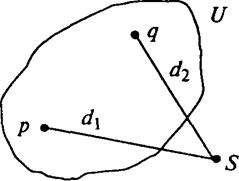
Метод "найближчого сусіда" — ступінь подібності оцінюється за ступенем подібності між найбільш схожими (найближчими) об'єктами цих кластерів (рис. 7.1).
Нехай d1і d2 — евклідові відстані, тоді якщо d1 > d2 , то S ввійде у кластер Uпо d2.
Метод "далекого сусіда" — ступінь подібності оцінюється за ступенем подібності між найбільш віддаленими (несхожими) об'єктами кластерів, тоді S ввійде у кластер U по d1.
Метод середнього зв'язку — ступінь подібності оцінюється як середня величина ступенів подібності між об'єктами кластерів. У цьому випадку S ввійде у кластер U по d=0,5(d1+d2).
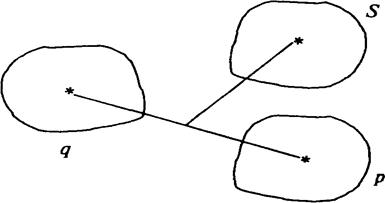
Метод медіанного зв'язку — відстань між будь-яким кластером S і новим кластером, що вийшов у результаті об'єднання кластерів р і q, визначається як відстань від центра кластера S до середини відрізка, що з'єднує центри кластерів р і q (рис. 7.2).
Використання різних алгоритмів об'єднання в ієрархічних агломеративних методах приводить до різних кластерних структур і сильно впливає на якість проведення кластеризації.
|
Рис. 7.1. Визначення відстані між кластерами методом "найближчого сусіда"
|
Рис. 7.2. Визначення відстаней між кластерами методом медіанного зв'язку
Тому алгоритм повинний вибиратися з урахуванням наявних зведень про існуючу структуру сукупності об'єктів, що спостерігаються, або з урахуванням вимог оптимізації математичних критеріїв.
Крім розглянутих агломеративних методів ієрархічного кластерного аналізу існують методи, протилежні їм за логічною побудовою процедур класифікації. Вони називаються ієрархічними дивізимними методами. Основною вихідною посилкою дивізимних методів є те, що спочатку всі об'єкти належать одному кластерові (класові). У процесі класифікації за визначеними правилами поступово від цього кластера відокремлюються групи схожих між собою об'єктів.
Поряд з ієрархічними методами класифікації існує численна група так званих ітеративних методів кластерного аналізу. Сутність їх полягає в тому, що процес класифікації починається з завдання деяких початкових умов (кількість утворених кластерів, поріг завершення процесу класифікації і т. д.). Ітеративні методи в більшому ступені, ніж ієрархічні, вимагають від користувача інтуїції під час вибору типу класифікаційних процедур і завдання початкових умов розбивки, тому що більшість цих методів дуже чуттєва до зміни параметрів, що задаються. Наприклад, обране випадковим чином число кластерів може не тільки сильно збільшити трудомісткість процесу класифікації, але і привести до утворення "розмитих" або малонаповнюваних кластерів. Тому доцільно спочатку провести класифікацію за одним з ієрархічних методів або на підставі експертних оцінок, а потім уже підбирати початкову розбивку і статистичний критерій для роботи ітераційного алгоритму. Як і в ієрархічному кластерному аналізі, в ітераційних методах існує проблема визначення числа кластерів. У загальному випадку їхнє число може бути невідомо. Не всі ітеративні методи вимагають первісного завдання числа кластерів. Але для остаточного рішення питання про структуру досліджуваної сукупності можна спробувати кілька алгоритмів, змінюючи або число утворених кластерів, або встановлений поріг близькості для об'єднання об'єктів у кластери. Тоді з'являється можливість вибрати найкращу розбивку за критерієм якості.
|
|
|
|
|
Дата добавления: 2014-11-29; Просмотров: 2525; Нарушение авторских прав?; Мы поможем в написании вашей работы!