КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Статистические меры информации
|
|
|
|
Недостатком структурного метода измерения информации является то, что в нем не учитывается вероятность наступления того или иного исхода. Для определения количества информации в случае, если исходы опыта имеют разную вероятность, используется статистическая мера К.Шеннона, предложенная им в 1948 году.
В основе статистического метода определения информации лежит положение о том, что получение информации снимает часть некоторой (априорной, до опытной) неопределенности.
Большинство источников информации характеризуется неопределенностью, связанной с неодинаковой вероятностью происходящих событий. Естественно, что с ростом числа возможных исходов неопределенность должна возрастать. Меру степени неопределенности называют энтропией.
Пусть мы имеем опыт, имеющий "N" равновероятных исходов.
Такую неопределенность называют равной:
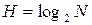 ;
;
Это выражение можно записать в виде:
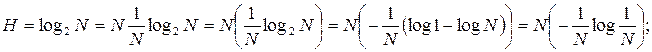 Из теории вероятностей известно, что
Из теории вероятностей известно, что 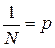 - вероятность любого из N возможных исходов опыта, поэтому выражение (1) переписываем в виде:
- вероятность любого из N возможных исходов опыта, поэтому выражение (1) переписываем в виде:
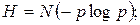
При N=2 имеем:
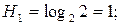 (бит))
(бит))
Бит - это единица для измерения степени неопределенности опыта.
А как же измерить неопределенность в случае разновероятных исходов?
Пусть некоторый опыт характеризуется следующей таблицей вероятности:
Исходы опыта: A1 A2 A3... Ai... AN
Вероятность: p1 p2 p3... pi... pN
Естественно, что p1 + p2 + p3 +... + pi + pN = 1.
Тогда в соответствии с формулой (2) меру неопределенности этого опыта запишем в виде:
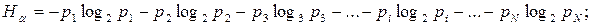
или
 (1.2.5)
(1.2.5)
Полученное выражение имеет вид, совпадающий с видом выражения для энтропии в статистической физике, причем это несет не только формальный, но и содержательный характер.
Поэтому величину 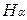 называют энтропией опыта a.
называют энтропией опыта a.
Свойства выражения (1.2.5): Любое слагаемое всегда положительно, т.к. 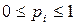 , а следовательно
, а следовательно 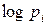 всегда отрицателен. При
всегда отрицателен. При 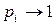 выражение
выражение 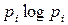 убывает и стремиться к 0, т.к.
убывает и стремиться к 0, т.к. 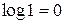 .
.
Пример. Пусть мы имеем следующий опыт: к нам пришло следующее сообщение: А1 А3 А1 А3 А3 А2 А3А4
Требуется определить количество информации в данном сообщении.
Алфавит этого сообщения состоит из 4 букв: А1, А2, А3, А4.
Следовательно, для кодирования этих букв достаточно будет двух двоичных разрядов: А1 – 00, А2 – 01, А3 – 10, А4 – 11.
Если применить меру Хартли, то для передачи данного сообщения при применении равномерного кода необходимо будет 16 двоичных разрядов, т.е. 16 бит. Причем на одну букву приходится 2 бита: 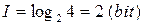
Однако такой подход не учитывает неравной вероятности появления букв в сообщении и поэтому не может считаться правильным.
Определим вероятности появления букв в сообщении:
P1 = 0,25; P2 = 0,125; P3 = 0,5; P4 = 0,125;
В этом случае количество информации, приходящейся на одну букву в этом сообщении, равно:
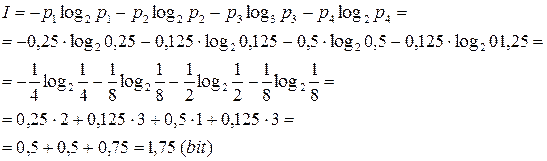
И таким образом, общие количество информации в этом сообщении составляет 8*1,75 = 14 (bit), что меньше, чем при равномерном коде.
 Отсюда следует, что неравная вероятность появления букв в сообщении приводит к уменьшению избыточности количества информации.
Отсюда следует, что неравная вероятность появления букв в сообщении приводит к уменьшению избыточности количества информации.
В том же 1948 году К.Шеннон (на фото) доказал теорему о том, что возможен такой способ кодирования, который приводит к уменьшению длины двоичного кода сообщения, в котором наблюдается неравная вероятность появления букв. Тогда же он совместно с Фано предложил алгоритм оптимального кодирования, позволяющий уменьшать длину сообщения. Этот алгоритм широко применяется в программах архивирования данных.
Мера Шеннона и алгоритмы, разработанные им для кодирования информации, широко применяются в практике программирования, в частности, при разработке алгоритмов архивации файлов, например таких, как pkzip, arj, zip, 7zip, rar и ряда других, а также в системах обнаружения и исправления ошибок при передаче данных.
|
|
|
|
|
Дата добавления: 2014-11-29; Просмотров: 971; Нарушение авторских прав?; Мы поможем в написании вашей работы!