КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Критические значения коэффициента линейной корреляции Пирсона 1 страница
|
|
|
|
Критические значения коэффициента ранговой корреляции Спирмена
(по книге: Суходольский Г. В. Основы математической статистики для психологов. – Л., 1972. – С. 419)
Таблица 48
| N | a | |
| 0,05 | 0,01 | |
| 0,94 | — | |
| 0,85 | — | |
| 0,78 | 0,94 | |
| 0,72 | 0,88 | |
| 0,68 | 0,83 | |
| 0,64 | 0,79 | |
| 0,61 | 0,76 | |
| 0,58 | 0,73 | |
| 0,56 | 0,70 | |
| 0,54 | 0,68 | |
| 0,52 | 0,66 | |
| 0,50 | 0,64 | |
| 0,48 | 0,62 | |
| 0,47 | 0,60 | |
| 0,46 | 0,58 | |
| 0,45 | 0,57 | |
| 0,44 | 0,56 | |
| 0,43 | 0,54 | |
| 0,42 | 0,53 | |
| 0,41 | 0,52 | |
| 0,40 | 0,51 | |
| 0,39 | 0,50 | |
| 0,38 | 0,49 | |
| 0,38 | 0,48 | |
| 0,37 | 0,48 | |
| 0,36 | 0,47 | |
| 0,36 | 0,46 | |
| 0,36 | 0,45 | |
| 0,34 | 0,45 | |
| 0,34 | 0,44 | |
| 0,33 | 0,43 | |
| 0,33 | 0,43 | |
| 0,33 | 0,43 | |
| 0,32 | 0,41 | |
| 0,32 | 0,41 | |
| 0,31 | 0,40 |
(по книге: Суходольский Г. В. Основы математической статистики для психологов. – Л., 1972. – С. 418.)
Таблица 49
| N | a=0,05 | a=0,01 |
| 0,950 | 0,990 | |
| 0,878 | 0,959 | |
| 0,811 | 0,917 | |
| 0,754 | 0,874 | |
| 0,707 | 0,834 | |
| 0,666 | 0,798 | |
| 0,632 | 0,765 | |
| 0,602 | 0,735 | |
| 0,576 | 0,708 | |
| 0,553 | 0,684 | |
| 0,532 | 0,661 | |
| 0,514 | 0,641 | |
| 0,497 | 0,623 | |
| 0,482 | 0,606 | |
| 0,468 | 0,590 | |
| 0,456 | 0,575 | |
| 0,444 | 0,561 | |
| 0,433 | 0,549 | |
| 0,423 | 0,537 | |
| 0,413 | 0,526 | |
| 0,404 | 0,515 | |
| 0,396 | 0,505 | |
| 0,388 | 0,496 | |
| 0,381 | 0,487 | |
| 0,374 | 0,478 | |
| 0,367 | 0,470 | |
| 0,361 | 0,463 | |
| 0,332 | 0,435 | |
| 0,310 | 0,407 | |
| 0,292 | 0,384 | |
| 0,277 | 0,364 | |
| 0,253 | 0,333 | |
| 0,234 | 0,308 | |
| 0,219 | 0,288 | |
| 0,206 | 0,272 | |
| 0,196 | 0,258 | |
| 0,175 | 0,230 | |
| 0,160 | 0,210 | |
| 0,138 | 0,182 |
Приложение 2. Глоссарий
1. Альтернативная гипотеза — это гипотеза о значимости различий. Она обозначается как Н1. Альтернативная гипотеза — это то, что мы, как правило, хотим доказать; поэтому иногда ее называют экспериментальной гипотезой.
2. Вариационный (статистический) ряд — таблица, первая строка которой содержит в порядке возрастания значения признака, а вторая — меры возможности их появления (абсолютные частоты, или относительные частоты, или процентные частоты).
3. Вероятностная зависимость (стохастическая связь) — это такая связь между явлениями или событиями, при которой появление одного из событий изменяет вероятность появления другого события.
4. Вероятность — мера возможности появления признака (число, не превышающее единицу).
5. Гистограмма — график в виде столбиковой диаграммы, который отражает зависимость между значениями признака и мерами возможности их появления.
6. Диаграмма рассеяния — график, представляющий собой множество (совокупность) точек в двумерном пространстве; координатами этих точек являются значения двух признаков. Такой график отражает зависимость между этими двумя признаками.
7. Дискриминантный анализ («классификация с обучением») предсказывает принадлежность объектов (испытуемых) к одному из известных классов (шкала наименований) по измеренным метрическим (дискриминантным) переменным. Дискриминантные переменные должны быть измерены в количественной шкале, зависимая переменная — в шкале наименований.
8. Дисперсия — 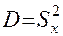 — это средний квадрат отклонений всех значений признака от среднего арифметического.
— это средний квадрат отклонений всех значений признака от среднего арифметического.
9. Дисперсионный анализ — это анализ изменчивости признака под влиянием каких-либо контролируемых переменных факторов. Признаки должны быть измерены в количественной шкале (интервальной или пропорциональной) и иметь нормальное распределение.
10. Доверительная вероятность — вероятность, с которой принимается нулевая гипотеза, или иначе: вероятность того, что нулевая гипотеза является истинной.
11. Зависимые выборки (связанные выборки) — это одна и та же группа людей, у которых были измерены одни и те же признаки в двух (или более) различных ситуациях, например, «до — после», «фон — стресс».
12. Измерение — это приписывание числовых форм объектам или событиям в соответствии с определенными правилами.
13. Квантили — значения признака, которые делят выборку на определенное количество равных частей. Наиболее распространенные квантили — это медиана; квартили Q1, Q2, Q3 (делят выборку испытуемых на 4 равные части); децили D1, D2, D3, D4, D5, D6, D7, D8, D9 (делят выборку испытуемых на 10 равных частей); процентили Р1 ……….Р99 (делят выборку испытуемых на 100 равных частей).
14. Кластерный анализ («классификация без обучения»): по измеренным характеристикам у множества объектов (испытуемых) либо по данным об их попарном сходстве (различии) разбивает это множество объектов на группы, в каждой из которых находятся объекты, более похожие друг на друга, чем на объекты других групп.
15. Корреляционное отношение — является мерой связи для оценки нелинейных взаимозависимостей между признаками, измеренными по интервальной или пропорциональной шкале.
16. Коэффициент асимметрии — As — параметр, характеризующий асимметричность распределения по сравнению с нормальным распределением.
17. Коэффициент вариации или коэффициент вариативности — V — параметр, показывающий соотношение стандартного отклонения и среднего арифметического.
18. Коэффициент контингенции или тетрахорический коэффициент или коэффициент четырехклеточной сопряженности — φ —является мерой связи между признаками, измеренными по дихотомической шкале наименований.
19. Коэффициент линейной корреляции Пирсона — rxy —является мерой связи для оценки линейных взаимозависимостей между признаками, измеренными по интервальной или пропорциональной шкале.
20. Коэффициент ранговой корреляции Спирмена — ρ = rs — является мерой связи между признаками, измеренными по шкале порядка или при сочетании шкалы порядка с интервальной или пропорциональной шкалой.
21. Коэффициент эксцесса — Ex — параметр, характеризующий выпуклость распределения по сравнению с нормальным распределением.
22. Критерий вообще — это решающее правило, обусловливающее поведение в ситуации выбора.
23. Критерий Вилкоксона — T — непараметрический критерий различий, который позволяет оценить различия между двумя зависимыми выборками: направление и выраженность изменений во втором замере по сравнению с первым. Применяется для сравнения признаков, измеренных по шкалам порядка, интервальной или пропорциональной.
24. Критерий Колмогорова-Смирнова — λ — непараметрический критерий, который позволяет оценить различия между двумя распределениями: найти точку, в которой они наиболее сильно различаются. Применяется для сравнения распределений признаков, измеренных по шкалам порядка, интервальной или пропорциональной.
25. Критерий Макнамары — M — непараметрический критерий, который позволяет оценить различия между двумя зависимыми выборками: два замера признака, измеренного по дихотомической шкале наименований и любым другим, если их результаты могут быть сведены к дихотомической шкале.
26. Критерий Манна-Уитни — U — непараметрический критерий различий, который позволяет оценить различия между двумя независимыми выборками: направление и выраженность значений признака. Применяется для сравнения признаков, измеренных по шкалам порядка, интервальной или пропорциональной.
27. Критерий Стьюдента — t — параметрический критерий различий, который позволяет сравнить два любых параметра распределений, полученных в двух выборках. Применяется для сравнения признаков, измеренных по интервальной или пропорциональной шкале при условии нормального распределения признака.
28. Критерий угловое преобразование Фишера — φ * — непараметрический критерий различий, который позволяет оценить различия между двумя процентными долями в двух независимых выборках. Применяется для сравнения признаков, измеренных по дихотомической шкале наименований и любым другим, если их результаты могут быть сведены к дихотомической шкале.
29. Критерий Фишера — F — параметрический критерий различий, который позволяет сравнить две дисперсии, полученные в двух выборках. Применяется для сравнения признаков, измеренных по интервальной или пропорциональной шкале при условии нормального распределения признака.
30. Критерий хи-квадрат Пирсона — χ 2 — непараметрический критерий, который позволяет сравнить два распределения признака: согласованность изменений в распределениях. Таким методом оцениваются различия между распределениями, а также взаимосвязь между признаками. Применяется для сравнения признаков, измеренных по шкале наименований, шкалам порядка, интервальной или пропорциональной.
31. Кумулята — график, отражающий зависимость между значениями признака и соответствующими им накопленными частотами. с которой отвергается нулевая гипотеза (истинная) и принимается альтернативная гипотеза (ложная),
32. Медиана — Ме — это значение признака, которое делит выборку испытуемых на две равные части: 50 % испытуемых имеют значения признака меньше медианы, 50 % испытуемых имеют значения признака больше медианы; медиана является частным видом квантилей.
33. Мера связи — числовая величина, отражающая тесноту (силу для всех типов измерений) и направленность (для качественно-количественного и количественного измерения) зависимости между признаками.
34. Многомерное шкалирование выявляет шкалы как критерии, по которым поляризуются объекты при их субъективном попарном сравнении.
35. Множественный регрессионный анализ предсказывает значения метрической «зависимой» переменной по множеству известных значений «независимых» переменных, измеренных у множества объектов (испытуемых). Все переменные должны быть измерены в количественной шкале.
36. Мода — Мо — это значение признака, которое имеет наибольшую частоту.
37. Мощность критерия — его способность критерия правильно отбрасывать ложную гипотезу. Она определяется эмпирическим путем.
38. Независимые выборки (не связанные выборки) — это две выборки, составленные из разных людей, у которых были измерены одни и те же признаки по одним и тем же методикам.
39. Непараметрические критерии— критерии, не включающие в формулу расчета параметры распределения и основанные на оперировании частотами или рангами (например, критерий знаков, критерий Ван-дер-Вардена и др.).Непараметрические критерииприменяются для любых шкал и любых распределений признаков.
40. Нулевая гипотеза — это гипотеза об отсутствии зависимости между признаками или отсутствии различий между выборками. Она обозначается как Н0.
41. Ошибка первого рода (р-уровень) — вероятность, с которой отвергается нулевая гипотеза, являющаяся истинной, и принимается альтернативная гипотеза, являющаяся ложной.
42. Параметрические критерии служат для проверки гипотез о параметрах распределений или для их оценивания, то есть, является ли параметр, полученный на выборке испытуемых, и параметром генеральной совокупности. Параметрические критерии применяются для оценки параметров признаков, измеренных по интервальной и пропорциональной шкале при условии нормального распределения признаков.
43. Параметры распределений — числовые характеристики, отражающие основные тенденции выраженности и изменчивости исследуемых признаков в исследуемой выборке.
44. Полигон частот или многоугольник частот — график в виде прямой ломаной линии, отражающий зависимость между значениями признака и мерами возможности их появления.
45. Распределение — график, отражающий зависимость между значениями признака и мерами возможности их появления (вероятностями или частотами).
46. Регрессия — график в виде линии, которая отражает зависимость между условными средними значениями одной переменной и значениями другой переменной.
47. Репрезентативность выборки — свойство выборочной совокупности, заключающееся в ее способности адекватно представлять основные характеристики генеральной совокупности (воспроизводятся основные свойства генеральной совокупности).
48. Среднее арифметическое значение — 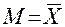 — это то значение признака, которое отражает средний уровень выраженности признака в выборке испытуемых.
— это то значение признака, которое отражает средний уровень выраженности признака в выборке испытуемых.
49. Стандартное отклонение (или среднеквадратическое отклонение) — 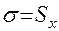 — это среднее отклонение каждого значения признака от среднего арифметического.
— это среднее отклонение каждого значения признака от среднего арифметического.
50. Статистическая гипотеза — это предположения о свойствах и параметрах генеральной совокупности, различии выборок или зависимости между признаками.
51. Статистический критерий — правило, обеспечивающее надежное поведение, т. е. принятие истинной и отклонение ложной гипотезы с высокой вероятностью. Слова статистический критерий обозначают также метод расчета определенного числа и само это число.
52. Уровень значимости — вероятность ошибочного отклонения нулевой гипотезы.
53. Факторный анализ направлен на выявление структуры переменных как совокупности факторов, каждый из которых — это скрытая, обобщающая причина взаимосвязи группы переменных. Надежные результаты получаются, если переменные измерены в количественной шкале (интервальной или пропорциональной). Число испытуемых должно превышать число переменных (или, по крайней мере, должно быть равно ему).
54. Число степеней свободы — ν = df — количество возможных направлений изменчивости переменной.
55. Шкала наименований (номинативная, номинальная) является результатом использования при измерении метода регистрации; относится к качественному измерению.
56. Шкала порядка (порядковая, ординальная) является результатом использования при измерении метода упорядочивания; относится к качественно-количественному измерению.
57. Шкала равных интервалов (интервальная) является результатом измерения методом соотнесения (с эталонной единицей измерения), нулевая точка шкалы произвольна и не указывает на отсутствие измеряемого свойства; является метрической шкалой и относится к количественному измерению.
58. Шкала равных отношений (пропорциональная) является результатом измерения методом соотнесения (с эталонной единицей измерения), существует абсолютный нуль, который означает отсутствие измеряемого свойства; является метрической шкалой и относится к количественному измерению.
Приложение 3. Ответы на задачи для самоконтроля усвоения знаний
Тема 5. Практическое задание № 1
| xi | 134 42 | 125 29 | 126 33 | 124 27 | 126 34 | 121 22 | 109 8 | 125 30 | 143 49 | 106 6 | 134 43 | 103 5 | 128 37 | ∑ |
| Ri | 42,5 | 30,5 | 33,5 | 27,5 | 33,5 | 30,5 | 42,5 | 4,5 | ||||||
| xi | 131 40 | 141 48 | 127 35 | 125 31 | 103 4 | 117 16 | 107 7 | 133 41 | 111 9 | 127 36 | 122 25 | 147 50 | 125 32 | |
| Ri | 35,5 | 30,5 | 4,5 | 16,5 | 35,5 | 25,5 | 30,5 | 374,5 | ||||||
| xi | 140 47 | 137 45 | 118 18 | 114 13 | 120 19 | 121 23 | 122 26 | 121 24 | 111 10 | 135 44 | 129 38 | 116 14 | 124 28 | |
| Ri | 25,5 | 38,5 | 14,5 | 27,5 | ||||||||||
| xi | 120 20 | 93 1 | 100 2 | 117 17 | 129 39 | 112 12 | 111 11 | 116 15 | 120 21 | 102 3 | 139 46 | |||
| Ri | 16,5 | 38,5 | 14,5 | 183,5 |
Расчетная сумма рангов 
Реальная сумма проставленных рангов ∑R=368+374,5+349+183,5=1275
Тема 5. Практическое задание № 2
Для а=2 Та= (23–2)/12=1,5
Для а=3 Та= (33–3)/12=2,0
Для а=4 Та= (43–4)/12=5,0
Для а=5 Та= (53–5)/12=10,0
Для а=6 Та= (63–6)/12=17,5
Тема 9. Практическое задание № 2
φрасч. = – 0,508 χ2расч. = 3,096
Оценку значимости расчетного значения коэффициента контенгенции производим с помощью критерия хи-квадрат Пирсона.
χ2табл. = 3,84 для р = 0,95
χ2расч=3,0,96 < χ2табл=3,84
Следовательно, статистически значимой взаимосвязи между признаками нет, то есть семейное положение студентов не влияет на их отчисление из ВУЗа.
Тема 9. Практическое задание № 3
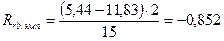
Оценку значимости рангово-бисериального коэффициента корреляции производим с помощью критерия Стьюдента.
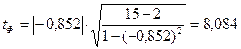
tФ=8,084 ≥ tтабл .= 3,01 при р= 0,99 Следовательно, между признаками существует статистическая значимая связь, то есть существует взаимосвязь между полом и развитием вервальных способностей.
Тема 9. Практическое задание № 4
С поправкой на связанные ранги
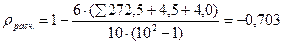
ρрасч.=|–0,703| > ρрасч.= 0,64 при р=0,95 Следовательно, корреляция достоверно отличается от 0, т.е. взаимосвязь между выраженностью акцентуируемых у матери и сына существует и она обратно пропорциональная.
Приложение 4. Англо-русский словарь статистических терминов
Словарь позаимствован из пособия, написанного А. Д. Наследовым.
Этот словарь может быть полезен при работе с компьютерными пакетами математико-статистического анализа (SРSS или STATISTICA).
| 1- Sample K-S Test— | критерий (тест) Колмогорова-Смирнова |
| 1-tailed— | односторонний (направленный) уровень значимости |
| 2-tailed— | двусторонний (ненаправленный) уровень значимости |
| Absolute value— | абсолютное значение |
| Actual (value, group) — | действительное, реальное (значение, группа) |
| Add — | добавить |
| Adjusted— | исправленный (улучшенный) |
| Advanced (Model)— | специальная, более совершенная (модель) |
| Agglomeration schedule— | последовательность агломерации (объединения) |
| ALSCAL— | программа неметрического многомерного шкалирования |
| Amalgamation— | слияние, объединение |
| Analyze— | анализировать |
| ANOVA— | дисперсионный анализ |
| Approach— | подход |
| Assume— | принятие (допущение, предположение) |
| Asymmetric— | асимметричная |
| Asymp. Sig.— | примерный (приближенный) уровень значимости |
| Average Linkage— | средней связи (метод кластеризации) |
| Averaged— | усредненный |
| Axis— | ось (координат) |
| Bartlett's Test of Sphericity — | тест сферичности Бартлета |
| Based on— | основанный на (исходящий из) |
| Beta-Coefficient— | стандартизированный коэффициент регрессии |
| Between (objects, variables)— | между (объектами, переменными) |
| Between Groups Linkage — | межгрупповой (средней) связи (метод кластеризации) |
| Between-Group — | межгрупповой |
| Between-Subject— | между объектами (межгрупповой) |
| Binary Measures— | количественные показатели (меры) для бинарных данных |
| Binomial Test— | биномиальный критерий |
| Bivariate — | двумерный |
| Box's M-test— | М-тест Бокса |
| Canonical Analysis— | канонический анализ |
| Case— | случай (испытуемый) |
| Casewise deletion— | исключение из анализа случая (строки), в котором имеется пропуск хотя бы одного значения |
| Categories— | категории (номинативного признака) |
| Categorization— | операция выделения интервалов квантования (или значений переменной) при построении гистограммы и составлении таблицы частот |
| Cell— | ячейка (таблицы) |
| Central Tendency— | центральная тенденция (мера) |
| Centroid — | центроид |
| Chi I — | хи-квадрат |
| Chi-square (Test)— | хи-квадрат (критерий) |
| Classify— | классифицировать |
| Cluster Combined— | объединенные кластеры |
| Cluster Method— | метод кластеризации |
| Coefficient (s)— | коэффициент(ы) |
| Column— | столбец |
| Combine— | объединение, объединять |
| Communality— | общность |
| Compare— | сравнивать |
| Compare Means— | сравнение средних |
| Comparison — | сравнение |
| Complete Linkage — | полной связи (метод кластеризации) |
| Compute— | вычисление, вычислять |
| Conditionality— | условность, обусловленность (подгонки) |
| Confidence (Interval) — | доверительный (интервал) |
| Constant— | константа |
| Contrast— | контраст |
| Controlling for...— | контролировать (фиксировать) для... |
| Convergence— | сходимость (при подгонки) |
| Corrected (Model)— | исправленная, скорректированная (модель) |
| Correlate— | коррелировать (определять совместную изменчивость) |
| Correlation matrix— | корреляционная матрица |
| Count Measure— | количественный показатель (мера) частоты |
| Covariance— | ковариация |
| Covariate— | ковариата |
| Criteria (Criterion)— | условие (критерий) |
| Crosstabulation (Crosstab)— | сопряженность, кросстабуляция |
| Cumulative frequencies — | —кумулятивные (накопленные) частоты |
| Custom Model— | специальная модель |
| Cut Point — | точка деления |
| Data— | данные |
| Data Editor— | редактор (таблица) исходных данных в SPSS |
| Data Reduction— | сокращение данных (метод) |
| Define (Groups)— | определение, задание (групп) |
| Degrees of freedom (df)— | число степеней свободы |
| Deletion— | удаление (исключение) |
| Dendrogram— | дендрограмма (древовидный график) |
| Density Function— | функция плотности вероятности |
| Dependent Sample— | зависимая выборка |
| Dependent-Samples T Test — | критерий t-Стьюдента для зависимых выборок |
| Derived— | производный |
| Descriptive Statistics— | описательные статистики |
| df— | число степеней свободы (сокр.) |
| Difference— | разность, различие |
| Dimension — | шкала |
| Discriminant Analysis— | дискриминантный анализ |
| Dispersion— | изменчивость |
| Dissimilarity — | различие |
| Distance— | расстояние |
| Distribution — | распределение |
| Distribution Function — | функция распределения (вероятности) |
| Effect— | влияние (фактора) |
| Eigenvalue— | собственное значение |
| Enter— | исходный (метод) |
| Entry— | включение |
| Epsilon Corrected— | с Эпсилон-коррекцией |
| Equal — | одинаковые |
| Equal Variances— | одинаковые (эквивалентные) дисперсии |
| Equality (of Variances) — | эквивалентность, равенство (дисперсии) ошибка |
| Error— | оценка |
| Estimate — | Евклидово расстояние |
| Euclidean Distance— | точный, точно |
| Exact— | точный уровень значимости |
| Exact Sig.— | исключение (объектов) |
| Exclude (cases)— | ожидаемая (теоретическая) частота (значение) |
| Expected Frequency (Value) — | «объясненная» (дисперсия) |
| Explained (Variance)— | метод факторизации (экстракции факторов) |
| Extraction Method— | фактор |
| Factor— | факторный анализ |
| Factor Analysis— | факторные нагрузки |
| Factor Loadings— | коэффициенты факторных оценок |
| Factor Score coefficients— | факторные оценки |
| Factor Scores — | точный критерий Фишера |
| Fisher's Exact Test— | постоянный, фиксированный (фактор) |
| Fixed (Factor)— | для всей матрицы |
| For Matrix— | значение Р-критерия (Р-отношения) для дисперсий |
| F-ratio Variances— | частота |
| Frequency— | таблицы частот |
| Frequency tables— | критерий Фридмана |
| Friedman test (ANOVA) — | модель, включающая все факторы |
| Full factorial model— | дальнего соседа (метод кластеризации) |
| Furthest Neighbor— | общая линейная модель |
| General Linear Model— | обобщенный метод |
| Generalized least squares— | наименьших квадратов |
| GLM — | общая линейная модель (сокр.) |
| Goodness-of-fit — | качество подгонки |
| Group Membership— | принадлежность к группе |
| Group Plots— | график(и) для всей группы |
| Grouping Variable— | группирующая переменная |
| Han Hierarchical Cluster Analysis — | иерархический кластерный анализ |
| Histogram— | гистограмма |
| Homogeneity of Variances— | гомогенность (однородность) дисперсий горизонтальная (ориентация) |
| Horizontal— | факторный анализ образов |
| Image Factoring— | улучшение (с поправкой) |
| Improvement— | включение |
| Independent Sample— | независимая выборка |
| Independent-Samples T Test— | критерий t-Стьюдента для независимых выборок |
| Individual Differences (model) — | индивидуальных различий (модель) |
| INDSCALE— | программа многомерного шкалирования индивидуальных различий |
| Initial (conditions)— | начальные (условия) |
| Input File— | исходный, входящий файл |
| Interaction— | взаимодействие |
| Intercept— | свободный член (уравнения) |
| Interval— | интервальная (шкала) |
| Interval data— | данные в интервальной шкале |
| Interval Scale— | интервальная шкала |
| Inverse distribution function— | обратная функция распределения итерация |
| Iteration— | итерация |
| Iteration history— | «история» (последовательность) итераций |
| Iterations stopped...— | итерации остановлены... |
| Joining— | объединение, связь |
| Kendall's tau— | тау-Кендалла (корреляция) |
| Kendall's tau-b— | тау-b Кендалла (корреляция) |
| Kruskal-Wallis H— | критерий Н-Краскала Уоллеса |
| Kruskal-Wallis one-way analysis of variance — | однофакторный дисперсионный анализ Краскала-Уоллеса |
| Kurtosis— | эксцесс |
| Label— | метка, обозначение |
| Level — | уровень |
| Level of Measurement— | уровень (шкала) измерения |
| Levene's Test— | критерий Ливена |
| Linear Regression— | линейный регрессионный |
| Linkage— | соединение, связь |
| List— | список |
| Listwise — | построчно |
| Listwise Deletion— | исключение из анализа случая (строки), в котором имеется пропуск хотя бы одного значения |
| Loading— | нагрузка |
| Mann-Whitney U— | критерий U-Манна-Уитни |
| MANOVA— | многомерный дисперсионный анализ |
| Marginal (Means)— | отдельные (средние значения) |
| Matrices— | матрицы |
| Matrix— | матрица |
| Mauchly's Test of Sphericity — | тест сферично сти |
| MoynjiM Maximum Likelihood — | максимального правдоподобия (метод) |
| McNemar Test— | критерий Мак-Нимара |
| Mean — | среднее |
| Mean of Squares (MS) — | средний квадрат |
| Mean Substitution— | замена пропущенных значений средними |
| Means Plot— | график средних значений |
| Measurement — | измерение |
| Median — | медиана |
| Missing (Values)— | пропущенные (значения) |
| M-L (Maximum likelihood) — | максимального правдоподобия (метод, оценка) |
| Mode — | мода |
| Monte Carlo Method — | статистический метод «Монте-Карло» |
| Multidimensional Scaling — | многомерное шкалирование |
| Multiple— | множественный |
| Multiple comparisons — | множественные сравнения (средних) |
| Multivariate— | многомерный |
| Multivariate Approach— | многомерный подход |
| Nearest Neighbor— | ближайшего соседа (метод кластеризации) |
| Negative — | отрицательный |
| Next — | следующий |
| Nominal— | номинальная (шкала) |
| Nonparametric Test— | непараметрический критерий |
| Normal Curve— | нормальная кривая |
| Number— | количество (численность), номер |
| Observed Frequency— | наблюдаемая (эмпирическая) частота |
| Observed Prop.— | наблюдаемое (эмпирическое) соотношение |
| One-Sample Kolmogorov-SmirnovTest — | критерий (тест) Колмогорова-Смирнова |
| One-Sample T Test— | критерий t-Стьюдента для одной выборки |
| One-tailed (one-sided) — | односторонний критерий (для проверки односторонних гипотез); one-tailed — дословно однохвостый |
| One-Way ANOVA— | однофакторный дисперсионный анализ |
| Ordinal (Rank order)— | порядковая (ранговая) (шкала) |
| Paired-Samples T Test— | критерий t-Стьюдента для зависимых выборок |
| Pairwise— | попарно, попарный |
| Partial Correlation— | частная корреляция (коэффициент) |
| Pearson Chi-Square — | критерий хи-квадрат Пирсона |
| Pearson correlation— | корреляция Пирсона |
| Pearson r— | корреляция Пирсона |
| Percentage— | процент |
| Percentiles— | процентили |
| Mean of Squares (MS) — | фи-коэффициент сопряженности |
| Phi 4-points correlation — | (четырехклеточный) фи—коэффициент сопряженности (Пирсона) |
| Pillai's Trace— | след Пиллая |
| P-Ievel— | статистическая значимость (р-уровень) |
| Plot— | диаграмма |
| Polynomial— | полином (многочлен) |
| Post Hoc — | апостериорный (после подтверждения гипотезы) |
| P-P Plot— | график накопленных частот |
| Predicted (value, group)— | предсказанное (значение, группа) |
| Principal Axis Factoring — | факторный анализ методом главных осей |
| Principal Components— | главных компонент (анализ) |
| Prior probabilities— | априорные вероятности |
| Probability— | вероятность |
| Probability of group membership—Proximity— | вероятность принадлежности к группе |
| Proximality — | близость |
| PROXSCAL— | программа неметрического многомерного шкалирования |
| Q-Q Plot— | квантильный график |
| Quantile — | квантиль |
| Quartile — | квартиль |
| R Square (R2)— | коэффициент детерминации (квадрат коэффициента корреляции) |
| Random (Factor)— | случайный (фактор) |
| Range — | размах |
| Rank — | ранг |
| Rank (Cases)— | ранжировать (объекты) |
| Ratio— | абсолютная шкала (равных отношений) |
| Raw — | строка |
| Raw Data— | данные в строках (типа «объект-признак») |
| Rectangular (matrix)— | прямоугольная (матрица) |
| Regression— | регрессионный |
| Regression Coefficient— | коэффициент регрессии |
| Regression Line — | линия регрессии |
| Related Samples— | зависимые (связанные) выборки |
| Removal— | удаление |
| Repeated Measures— | повторные измерения |
| Repeated Measures ANOVA — | дисперсионный анализ с повторными измерениями |
| Residual— | остаток, отклонение (ошибка модели) |
| Residual analysis— | анализ остатков (ошибок) |
| Rotation (Factors)— | вращение (факторов) |
| Rotation Method— | метод вращения |
| Row — | строка |
| RSQ (R-square)— | квадрат коэффициента корреляции, коэффициент дискриминации (г-квадрат) |
| Run — | серия |
| Runs Test— | критерий серий |
| Sample— | выборка |
| Scaling model— | модель шкалирования |
| Scatter Plot— | диаграмма рассеивания |
| Scheffé test— | метод Шеффе (множественных сравнений средних) |
| Scree plot— | график собственных значений |
| Scree-test— | критерий отсеивания |
| Scrollsheet— | таблица результатов статистического анализа |
| Separate (Line)— | отдельная (линия) |
| Set — | множество |
| Shape — | уточнить |
| Sig. — | уровень значимости (р-уровень) |
| Sign— | знак |
| Sign Test — | критерий знаков |
| Significance Level— | уровень статистической значимости (р-уровень) |
| Significant— | статистически значимый |
| Similarity— | сходство |
| Simple— | простой |
| Simple Matching— | простой коэффициент совстречаемости (бинарный) |
| Single Linkage— | одиночной связи (метод кластеризации) |
| Size difference— | величина различий (бинарная) |
| Skewness— | асимметрия |
| Slope— | уклон, наклон (прямой по отношению к оси X), значение коэффициента регрессии |
| Solution— | решение (выбор) |
| Source— | источник (изменчивости, влияния) |
| Spearman's rho (r)— | корреляция Спирмена (коэффициент) |
| Specify— | определять |
| Spreadsheet— | электронная таблица для исходных данных |
| SPSS— | компьютерная программа «Статистический пакет для социальных наук» (сокр.) |
| Square asymmetric (symmetric) matrix — | квадратная асимметричная (симметричная) матрица |
| Squared (Euclidean distance) — | квадрат (Евклидова расстояния) |
| S-stress convergence— | величина сходимости 8-стресса |
| Stage — | ступень (этап, шаг) |
| Standard deviation— | стандартное отклонение (сигма) |
| Standard error— | стандартная ошибка |
| Standardized (Beta-) Coefficients — | стандартизированные (бета-) коэффициенты регрессии |
| STATISTICA— | компьютерная программа для статистического анализа данных |
| Statistical Test— | статистический критерий (тест) |
| Std. Deviation— | стандартное отклонение (сигма) |
| Std. Error— | стандартная ошибка |
| Step— | шаг |
| Stepwise Method— | пошаговый метод |
| Stimulus— | стимулы |
| Stress — | стресс, в многомерном шкалировании |
| Stub-and-Banner Tables— | таблицы сопряженности для двух и более признаков |
| Subject— | субъект |
| Subject Weight— | индивидуальный вес |
| Subset— | подмножество |
| Sum — | сумма |
| Sum of Squares(SS) — | сумма квадратов |
| Summary — | итог |
| Suppress— | скрыть |
| Symmetric— | симметричная |
| Syntax— | командный файл в SPSS |
| Table— | таблица |
| Test— | статистический критерий |
| Test Prop.— | ожидаемое (теоретическое) соотношение |
| Test Statistics— | результаты статистической проверки |
| Test Value— | заданное (тестовое) значение |
| Tied Ranks— | связанные (повторяющиеся) ранги |
| Ties (of ranks)— | связи, повторы (рангов) |
| Total— | итог (сумма) |
| Transform (Values, Measures)— | преобразование (значений, мер) |
| Tree Diagram— | древовидная диаграмма |
| Two-tailed (two-sided)— | двусторонний критерий (для проверки двусторонних гипотез) |
| Univariate (procedure, approach) — | одномерный (метод, подход) |
| Unrotated— | до вращения |
| Unstandardized Coefficient — | коэффициент регрессии (не стандартизированный) |
| Untie tied observation — | разъединять (различать) связанные (одинаковые) данные |
| Unweighted least squares — | метод не взвешенных наименьших квадратов |
| Valid n— | число случаев, по которому были проведены расчеты |
| Value — | значение |
| Var — | переменная (сокр.) |
| Variable— | переменная (признак) |
| Variable List— | список переменный |
| Variance— | дисперсия |
| Varimax | метод варимакс (вращения факторов) |
| Vertical— | вертикальная (ориентация) |
| Weight— | вес |
| Wilcoxon Signed-rank (Matched pairs) test — | критерий Т-Вилкоксона |
| Wilcoxon test— | критерий Вилкоксона |
| Wilks' Lambda— | лямбда Вилкса |
| Within— | внутри |
| Within-Group— | внутригрупповой |
| Within-Subject— | внутри объектов (внутригрупповой) |
| XI — | хи-квадрат критерий |
| Yates' corrected— | с поправкой Йетса |
| Yule's Q— | Юла Q-коэффициент |
| Z-score — | z-значение |
|
|
|
|
|
Дата добавления: 2014-12-26; Просмотров: 2153; Нарушение авторских прав?; Мы поможем в написании вашей работы!