КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Средняя и предельная ошибки выборки. Расчет доверительного интервала выборки
|
|
|
|
Выборочную совокупность можно сформировать по количественному признаку статистических величин, а также по альтернативному или атрибутивному. В первом случае обобщающей характеристикой выборки служит выборочная средняя величина, обозначаемая 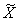 , а во втором — выборочная доля величин, обозначаемая w. В генеральной совокупности соответственно: генеральная средняя
, а во втором — выборочная доля величин, обозначаемая w. В генеральной совокупности соответственно: генеральная средняя 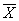 и генеральная доля р.
и генеральная доля р.
Разности — и W — р называются ошибкой выборки, которая делится на ошибку регистрации и ошибку репрезентативности. Первая часть ошибки выборки возникает из-за неправильных или неточных сведений по причинам непонимания существа вопроса, невнимательности регистратора при заполнении анкет, формуляров и т.п. Она достаточно легко обнаруживается и устраняется. Вторая часть ошибки возникает из-за постоянного или спонтанного несоблюдения принципа случайности отбора. Ее трудно обнаружить и устранить, она гораздо больше первой и потому ей уделяется основное внимание.
Величина ошибки выборки может быть разной для разных выборок из одной генеральной совокупности, поэтому в статистике определяется средняя ошибка повторной и бесповторной выборки по формулам:
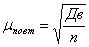 - повторная;
- повторная;
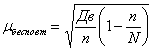 - бесповторная;
- бесповторная;
где Дв — выборочная дисперсия.
Например, на заводе с численностью работников 1000 чел. проведена 5%-ая случайная бесповторная выборка с целью определения среднего стажа работников. Результаты выборочного наблюдения приведены в первых двух столбцах следующей таблицы:
| X, лет (стаж работы) | f, чел. (число работников в выборке) | X и | X и f | 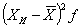
|
| до 1 | 0,5 | 3,5 | 38,987 | |
| 1-2 | 1,5 | 12,0 | 14,797 | |
| 2-3 | 2,5 | 25,0 | 1,296 | |
| 3-4 | 3,5 | 45,5 | 5,325 | |
| 4-5 | 4,5 | 40,5 | 24,206 | |
| более 5 | 5,5 | 16,5 | 20,909 | |
| Итого | 143,0 | 105,520 |
В 3-м столбце определены середины интервалов X (как полусумма нижней и верхней границ интервала), а в 4-м столбце - произведения XИf для нахождения выборочной средней по формуле средней арифметической взвешенной:
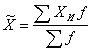 = 143,0/50 = 2,86 (года).
= 143,0/50 = 2,86 (года).
Рассчитаем выборочную дисперсию взвешенную:
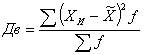 = 105,520/50 = 2,110.
= 105,520/50 = 2,110.
Теперь найдем среднюю ошибку бесповторной выборки:
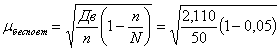 = 0,200 (лет).
= 0,200 (лет).
Из формул средних ошибок выборки видно, что ошибка меньше при бесповторной выборке, и, как доказано в теории вероятностей, она возникает с вероятностью 0,683 (то есть если провести 1000 выборок из одной генеральной совокупности, то в 683 из них ошибка не превзойдет средней ошибки выборки). Такая вероятность (0,683) является невысокой, поэтому она мало пригодна для практических расчетов, где нужна более высокая вероятность. Чтобы определить ошибку выборки с более высокой, чем 0,683 вероятностью, рассчитывают предельную ошибку выборки:
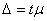
где t – коэффициент доверия, зависящий от вероятности, с которой определяется предельная ошибка выборки.
Значения коэффициента доверия t рассчитаны для разных вероятностей и имеются в специальных таблицах (интеграл Лапласа), из которых в статистике широко применяются следующие сочетания:
Вероятность 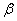
| 0,683 | 0,866 | 0,950 | 0,954 | 0,988 | 0,990 | 0,997 | 0,999 |
| t | 1,5 | 1,96 | 2,5 | 2,58 | 3,5 |
Задавшись конкретным уровнем вероятности, выбирают из таблицы соответствующую ей величину t и определяют предельную ошибку выборки по формуле.
При этом чаще всего применяют = 0,95 и t = 1,96, то есть считают, что с вероятностью 95% предельная ошибка выборки в 1,96 раза больше средней. Такая вероятность (0,95) считается стандартной и применяется по умолчанию в расчетах.
В нашем примере про средний стаж работников, определим предельную ошибку выборки при стандартной 95%-ой вероятности (из таблицы берем t = 1,96 для 95%-ой вероятности):  = 1,96*0,200 = 0,392 (года).
= 1,96*0,200 = 0,392 (года).
После расчета предельной ошибки находят доверительный интервал обобщающей характеристики генеральной совокупности. Такой интервал для генеральной средней величины имеет вид
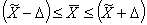
а для генеральной доли аналогично:
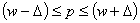 .
.
Следовательно, при выборочном наблюдении определяется не одно, точное значение обобщающей характеристики генеральной совокупности, а лишь ее доверительный интервал с заданным уровнем вероятности. И это серьезный недостаток выборочного метода статистики.
В нашем примере про средний стаж работников, определим доверительный интервал генеральной средней - среднего стажа работников:
2,86 - 0,392 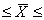 2,86 + 0,392 или 2,468 лет 3,252 лет.
2,86 + 0,392 или 2,468 лет 3,252 лет.
То есть средний стаж работников на всем заводе лежит в интервале от 2,468 года до 3,252 года.
|
|
|
|
|
Дата добавления: 2015-04-24; Просмотров: 1824; Нарушение авторских прав?; Мы поможем в написании вашей работы!