КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Идеология организации без упорядоченного выполнения 8 страница
| ||||||||||||||||||||||||

| ||||||||||||||||||||||||
|
|
|
| |||||||||||||||||||||
|
|

| 
|
|
| |||||||||||||||||||
| ||||||||||||||||||||||||
| ||||||||||||||||||||||||
| ||||||||||||||||||||||||
строгая согласованность- самая простая модель. В такой модели при любом обращении к ячейке памяти за данными из нее считывается самая последняя запись. На практике это реализуется путем простого алгоритма: первый пришел- первым обслужен. Кэширование и дублирование в основной памяти блоков данных запрещено. Такая последовательность применяется для областей памяти,предназначенных для ввода вывода,характеризуемые как не кэшируемые.
Согласованность по последовательности- этот алгоритм реализует последовательность записей и операций чтения при одновременном их поступлении от процессоров согласно правилам, установленными аппаратными средствами системы, при этом все процессоры наблюдают один и тот же порядок.
Процессорная согласованность- данная последовательность записей осуществляется согласно следующим двум правилам:
1Все процессоры воспринимают запись любого процессора в том порядке, они начинаются.
2.Все процессоры видят записи в котором они происходят.
Два этих правила устанавливают порядок при котором контроллер шины не гарантирует непрерывность цепочки записей от процессора, то есть контроллер может с согласия процессора задержать запись в своих буферных регистрах и пропустить запись вперед от другого процессора при представлении последнему шины согласно арбитража. Контроллер шины только гарантирует процессору, что его записи попадут в память согласно программной последовательности. Данная модель используется при реализации протокола когерентности MESI и при обращении к областям памяти, в которых можно реализовать политику обратной записи WB.
Для наглядности рассмотрим пример.
Пусть процессор1 осуществляет последовательность записей:
1А,1В,1С
Соответственно процессор2
2А,2В,2C
тогда контроллер шины имеет право произвести записи в память согласно следующей последовательности:
1A, 2A, 1B, 2B, 1C, 2C
из которой видно, что записи от процессоров произведены в программном порядке, хотя нарушена непрерывность их цепочек.
Слабая согласованность, при ней операции записей и чтения могут производиться в любом порядке, при этом аппаратные средства не гарантируют и не поддерживают какого- либо порядка поэтому, чтобы устранить хаос в обращениях к памяти и соблюсти алгоритм программы,
в программы вводят специальные команды синхронизации, при выполнении которых процессор заканчивает все ранее начатые операции обращения в память, таким образом, производится контроль за содержимым данных в системе.
Тема лекции: Организация межпроцессорных связей в симметричных мультипроцессорных системах.
1.Расширенный механизм прерываний как основной канал для передачи управляющей информации между процессорами в мультипроцессорной системе. Расширенный контроллер прерываний. Блок- схема.
2. Виды и форматы сообщений в мультипроцессорных системах. Протокол инициализации мультипроцессорной системы. (на примере SMP на базе процессоров INTEL).
Каждая модель мультипроцессорной спецификации в зависимости от архитектуры системы решает вопрос о межпроцессорных связях по-своему. В симметричных мультипроцессорных системах основным каналом обмена информацией является общая разделяемая память, которая дает возможность использовать системные команды LOAD и STORE при обмене данными между процессорами.
Но помимо этого канала для передачи управляющей информации как во время инициализации системы так и во время работы, для обработки ситуаций,вызывающих прерывания в системе используют расширенный механизм обработки прерываний, который кроме обработки прерываний, характерных для однопроцессорного режима осуществляет обработку так называемых внешних или межпроцессорных запросов на прерывания. В состав расширенного механизма прерывания входит отдельный физический интерфейс, через который связаны все процессора в мультипроцессорной системе.
Физическая организация такого интерфейса может быть различной и быть реализована как в виде шины, так и в виде многоточечных соединений: от каждого процессора ко всем остальным.
Топология соединения определяет и протокол межпроцессорного обмена. Так шинная организация обязательно должна предполагать наличие цикла арбитража, прежде чем будет передача сообщения от одного процессора к другому. В случае же многоточечного соединения в каждый момент времени каждый процессор имеет информацию о каждом и поэтому арбитраж осуществляется аппаратными средствами внутри каждого процессора в результате чего обрабатывается запрос на прерывание от самого приоритетного агента в данном такте, после обработки которого изменяется приоритет каждого процессора в системе.Обычно используется кольцевая схема приоритета, когда процессор имеющий высший приоритет “падает на дно”, а все остальные увеличивают значения своих арбитражных номеров на единицу.
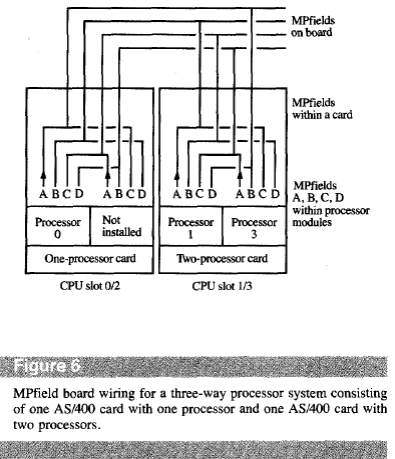
Примером такой организации может служить спроектированная в свое время мультипроцессорная система AS400. Имея общую шину связи процессоров с разделяемой памятью, то есть архитектуру SMP с общей шиной, но в отличии отSMP INTEL, осуществляла связь между процессорами по принципу межмодульных связей, причем степень глубины связей была достаточно высокой с точки зрения информационной емкости в межпроцессорных сообщениях. Связь осуществлялась по параллельному интерфейсу,формат межпроцессорного сообщения: поле данных, тип команды, поле идентификаторов процессоров, указатель на прерывание. Каждый раз, обращаясь в память, процессор обязан был по протоколу передавать всем другим процессорам код команды, с которой он обращается в общую память. Таким образом,буферизируя эти команды, каждый процессор имел очередь не только своих запросов к памяти, но и всех агентов системы.
Для того, чтобы активизировать прерывание в другом процессоре инициатор –процессор в сообщении устанавливал указатель и идентификатор процессора, который должен был выполнить прерывание. Выполнив прерывание, целевой процессор обязан был сбросить в своем регистре межпроцессорной связи свой идентификатор. Таким образом, процессор-инициатор, анализируя соответствующий бит на своей входной шине от целевого процессора, определял окончание операции в целевом процессоре.
Инициализация межпроцессорных сообщений в разных системах происходит по-разному. Так, например, в свое время в системе IBM370 и ей подобным ЭВМ отечественного производства класса ЕС передача межпроцессорных сообщений осуществлялась через специальный интерфейс прямого управления и для активизации, которых использовалась системная команда “СИГНАЛ ПРОЦЕССОРУ”. Формат этой команды был
трех адресный и имел следующий вид.
| 
| ||||||||||
А[B2,D2]-адрес ячейки оперативной памяти, в которой находится байт управляющей информации для адресуемого процессора.
[ R1]- байт состояния адресуемого процессора после выполнения приказа
[R2]- адрес процессора, которому предназначен приказ.
При выполнении данной команды, процессор после считывания байта управляющей информации из памяти формирует запрос на прерывание на интерфейсе прямого управления, выставляет на шины адреса и данных соответствующую информацию, таким образом активизирует запрос на внешнее прерывание в адресуемом процессоре.
Обработчик прерываний в адресуемом процессоре считывает байт управляющей информации с шины данных интерфейса прямого управления, активизируя соответствующие аппаратные средства в соответствии с приказом. Если для выполнения действий в адресуемом процессоре требуется дополнительная информация,то для этого используются ячейки оперативной памяти, специально выделенные для этой цели.
Для организации межпроцессорных связей в модели мультипроцессорной спецификации на базе процессоров фирмы INTEL используется расширенный контроллер прерываний (APIC), имеющий распределенную архитектуру то есть часть его оборудования размещается по-блочно в каждом из процессоров системы, являясь частью аппаратных средств каждого процессора. Каждый такой блок называется локальный APIC, состав и работу которого рассмотрим позже.
Отдельная часть расширенного контроллера прерываний размещается на системной плате в “южном мосте”, в котором размещены аппаратные средства для обеспечения ввода вывода. Часть эта носит название IOAPIC и предназначена для приема запросов на прерывания от всех источников на системной плате, включая, безусловно, и запросы от внешних устройств в системе. Общая структурная схема представлена ниже.
| ||||||||||||
| ||||||||||||
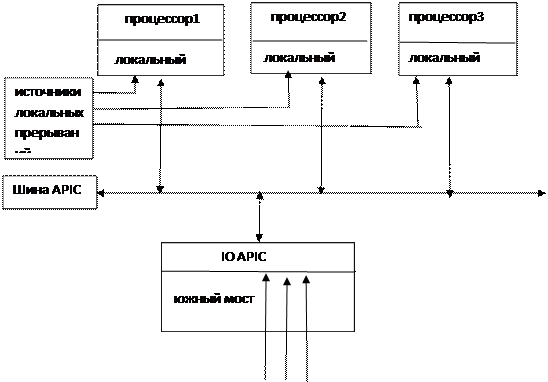
Как видно из структурной схемы,локальные APIC принимают запросы на прерывания от локальных источников для каждого процессора, которые могут находиться в системе. Помимо этого все внутренние источники прерываний в процессоре также направляют свои запросы в локальный блок APIC
|
|
Дата добавления: 2014-01-03; Просмотров: 332; Нарушение авторских прав?; Мы поможем в написании вашей работы!