КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
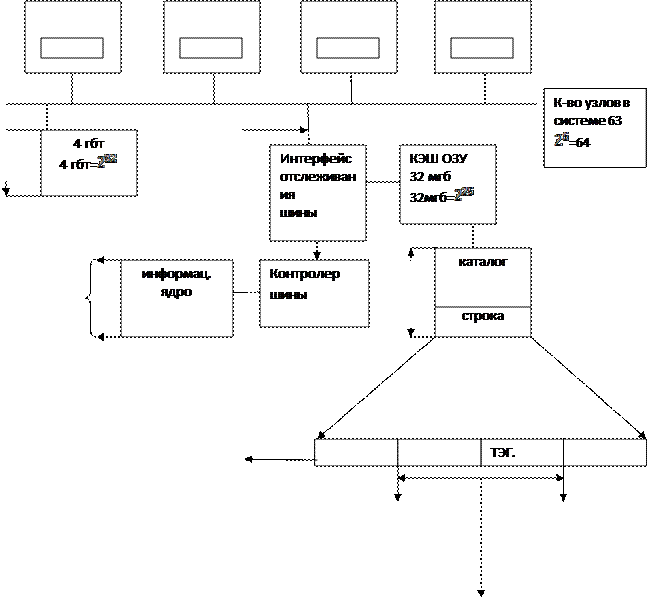
Структура узла мультипроцессора NOMA-Q
|
|
|
|
 |
ширина
строки
232/26= КЭШ 64 бит
226 64=26

К-во строк в кэш L2 узла 18 ра 219 225/26=219
К след. узлу: ширина шины Строка каталога
1 бит-синхронизация
1 бит-флаг, 16 бит адрес/данные
Формат строки каталога 6 бит 7 бит 13 бит 6 бит
емкость памяти составляет
232х63=238
емкость КЭШ = 225
13р. 19р. 6р.
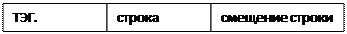
232х64=238
адрес шины 38 разрядов.
На рисунке показан информационный узел
Подобно любому кольцевому протоколу, использующих регистровые схемы, протокол SCI требует организации входных, транзитных и выходных очередей. Адресная логика определяет, будет ли входной пакет предназначен для узла или является транзитным. В зависимости от анализа, пакет маршрутизация в транзитную или входную очередь.
Когда узел имеет в выходной очереди пакеты, то для их передачи необходимо, чтобы в транзитной очереди были свободные места. Если транзитная очередь не имеет свободного места, узел должен задержать выдачу своего пакета до тех пор, пока на входе не будет входных пакетов для транзитной передачи.
Информационный узел NUMO-Q поддерживает протокол SCI. Связь между узлами поддерживается по 18-тиразрядной шине.
1 бит синхронизация
2-ой бит флаг – указывающий передачу адреса или данных
16 бит адрес/данные
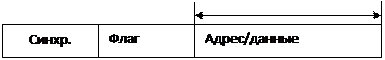 16 разрядов
16 разрядов
Структура пакета:
 0,16,64,256
0,16,64,256
Протокол основан на запросах и ответах к узлу.
 |
Стандарт протока по SCI (Skalable Coherent Interface)
1. Согласованность КЭШ достигается при помощи протокола на основе распределенного каталога.
2. Каждый процессорный узел, кэширующий блок из памяти помещает в строку каталога, соответствующий этому блоку адреса узлов, где содержится предыдущая и последующая копия при размножении. Тем самым организуя список.
3. Узел, организующий запрос за строкой, уже кэшированную ранее, ставя себя в начало очереди тем самым смещает все предыдущие узлы, заставляя их корректировать в случае необходимости значения адресов узла предыдущего и последующего узла в своих строках каталога.
4. Запись в строку, ее модификация разрешается только узлу в начале списка, поэтому если узел захочет модифицировать строку, он должен будет поставить себя в начало списка.
Организация передачи состояния строки в каталогах узла
1. Пусть к исходному узлу происходит обращение последовательно из узлов: A,B,C,D
Состояние строк каталога в узле:
| A | B | C | D | |||||||||
| t1 | исх. | |||||||||||
| t2 | B | исх | A | |||||||||
| t3 | B | C | A | исх | B | |||||||
| t4 | B | C | A | D | B | исх. | C |
Протокол SCI(РСИ – расширяющий связанный интерфейс)
Система SCI(РСИ) является модульной и немагистральной. Связь между узлами осуществляется по принципу «точка-точка». Для компоновки аппаратных средств предусмотрены команды 2-ух типов.
1. для передачи сообщения между узлами служат 18 параллельных линий
2. Передача между обособленными узлами выполняется последовательным кодом по коаксиальному кабелю.
Каналы синхронизируют с частотой 500мгц в параллельном канале, пропускная способность которого 500х2(1 гбайт/сек), в последовательном канале – 0,5 гбайт/сек
1 Передача осуществляется. пакетами. Пакет стоит:
14 байт 2 байта
  заголовок заголовок
| данные | кон. суммы |


 6 6 0,16,64,256 байт
6 6 0,16,64,256 байт
2 верхний программный уровень протокола форм. пакет с указанием адреса источника и получателя, в заголовке возможен фрейм-мультиплексный режим при передачи сообщения.
3 протокол использует трафик запросов и ответов.
Каждая строка системной памяти имеет фиксированную позицию только в одном блоке памяти (исходном) и фиксирует свое состояние в локальной таблице:
UNCACHED – означает, что строка не содержится ни в одном из КЭШей на плате IQ-Link, хотя может находится в локальной кэш-памяти исходного узла (ур. L1)
Shared – означает, что строка находится по крайней мере в одном из КЭШей на связной плате IQ-Link, а память содержит достоверные обновленные данные.
MODIFIED - означает, что строка находится в КЭШ памяти на одной из плат IQ-Link, и возможно изменяются.
Память КЭШ L2 хранит значения строк только из других узлов, запись этих строк в локальную память узлов запрещены. Поэтому обращению к ячейкам L2 и их изменение возможно только через программное обращение к L2.
Поэтому при обращении к узлу за строками из других узлов, затребованные строки выбираются из памяти узла (системной или L1).
Для того чтобы каждый узел использовал последнюю копию из других узлов, являющиеся собственником этих строк при обращении за строкой, он всегда ставится во главу очереди в запрашиваемом узле, о чем запрашиваемый узел информируется в ответе из запрашиваемого узла. А результат ответа- адрес последней копии фиксируется в строке (каталоге) для запрашиваемой строки в L2 при формировании связанного списка.
При этом каждый раз при обращении за строкой узлы, уже имеющие копии этой строки, обязаны по ротоколу корректировать свои строки в каталоге, указывающие на местонахождение в очереди.
В любом случае запрашивающий узел формирует запрос за строкой, даже если он первый узел в очереди потому, что за время после выборки строки в свою КЭШ(L2) исходный узел мог
изменить содержимое строки, так как состояние “INVALID” в протоколе отсутствует.
 | ||
 |
 |
|
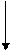

 Да нет
Да нет |
 да нет
да нет
 | |||
 | |||
Да нет
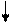
 | |||||
| |||||
| |||||
Рассмотренная нами ранее SMP система с шинной организацией не является единственным вариантом архитектуры таких систем. Альтернативой им являются системы с координатными коммутаторами и с межмодульными связями. Координатный коммутатор, его функциональное устройство как основной связующий элемент для передачи сообщений внутри системы между ее узлами мы рассмотрим позже, а сейчас остановимся на разборе организации межпроцессорных связей в системе с межмодульными непосредственными связями. Данная организация межпроцессорных связей используется, как уже упоминалось ранее, в серверах Zархитектуры, имеющей свое начало в архитектуре манфреймов линейки IBM360,370. Так называемый интерфейс прямого управления, который применялся для связи двух процессоров в двух процессорной системе был усовершенствован и стал в дальнейшем использоваться в моделях,позволяющих объединение нескольких. Протокол этого интерфейса содержит программные и аппаратные средства. Специальный набор системных команд, в который входит команда СИГНАЛ ПРОЦЕССОРУ является инициатором организации связи между процессорами. Данная команда реализует классический метод межпроцессорного соединения, в котором используется механизм внешних прерываний в процессоре.


Что же касается межпроцессорного обмена в рассматриваемой нами Z архитектуре серверов, то каждый процессор для этой цели имеет набор регистров, в которые микрокод, реализующий эту команду, размещает соответствующую информацию:
Регистр управления- в него помещается приказ или управляющая информация вызываемому процессору.
Выходной регистр данных и регистр адреса содержат соответственно передаваемые данные и адрес памяти, сформированный в команде и указывающий на место- нахождение управляющей информации вызываемому процессору.
Два входных регистра служат для приема данных и от вызываемого процессора о его состоянии и о результате операции.
До тех пор пока не будет получен ответ от вызываемого процессора, микрокод, реализующий команду, удерживает процессор в состоянии ожидания и только после получения ответа от вызываемого процессора формирует признак результата.
Следует отметить, особенностью серверов Zархитектуры является наличие внутренней сети, которая дает возможность управляющему компьютеру (SE) и сервисным процессорам, расположенным на модулях системы иметь доступ к регистрам, не только через которые осуществляются межпроцессорные связи, но и к регистрам, которые входят в состав узлов системы: системному контроллеру, контроллеру кэш, контроллеру памяти, а это дает возможность организации связи между другими чипами в системе.
Для этой цели каждый чип в системе имеет встроенный хаб, через который и осуществляется связь с этими регистрами.Кроме того эти регистры подключены к приемникам и передатчикам, являющихся частью интерфейсов для межмодульных связей.
Организация таких связей потребовала от разработчиков такой архитектуры при большом количестве интерфейсов внедрение специального протокола между чипами системы.
Для удобства управления все регистры, участвующие в межмодульных связях были разбиты на группы, в которых каждый регистр имеет свой адрес.
Каждая группа регистров должна была реализовать набор интерфейсов целевого назначения.
Так,например, для организации межпроцессорных сообщений была выделена группа регистров на каждом процессорном чипе, доступ к которым возможен не только со стороны сети, но и по команде СИГНАЛ ПРОЦЕССОРУ и другим командам,активизирующим межпроцессорные связи.
Протокол, к примеру, сервера Z9, имея трехбитную адресацию групп для каждого чипа и двухбитную адресацию для регистров, дает возможность иметь на каждом чипе до восьми групп и по четыре регистра в каждой из них. Для организации широковещательного режима используются все пять разрядов адреса, причем адрес группы в этом режиме выражается в позиционном коде, таким образом, позволяет сформировать пять групп для широковещательного опроса. Каждая из групп с индивидуальным адресом может входить сразу в несколько групп широковещательного опроса. Для того чтобы реализовать аппаратно эту методику,необходимо иметь 40 триггеров для фиксации состава каждой из широковещательных групп в каждом чипе.
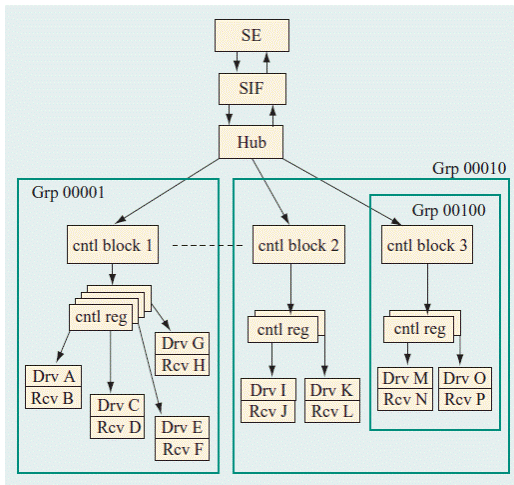
На данной блок-схеме показан чип с тремя индивидуальными группами регистров, каждая из которых представляет набор целевых интерфейсов. Каждому регистру в индивидуальной группе назначается пара состоящая из приемника и передатчика сигналов интерфейса,причем расположенных на разных чипах, таким образом формируя однонаправленную связь между чипами. Дешифрация адреса регистров реализована в два этапа. На первом этапе в хабе определяется адрес группы, а на втором блоком контроллера адрес регистра в группе.
Блок-схема SMP с межмодульными связями.
Независимо от того, является ли SMP с общей шиной или с межмодульными связями основные информационные потоки направлены в/из оперативной памяти и естественно центром диспетчеризации, управления этими потоками является контроллер памяти. При проектировании многопроцессорных систем класса CC-NUMA с межмодульными связями, когда между процессорами и оперативной памятью расположены КЭШи, для обеспечения когерентности данных в системе и управления их потоками целесообразно перемещение диспетчера из контроллера памяти в аппаратный узел, размещая его на “перекрестке”потоков между SMP узлами и потоками от “своих” процессоров в каждом узле в их память.
Примером такой архитектуры является SMP Z9 с возможностью объединения до четырех узлов в общей сумме имеющей 64 процессора.
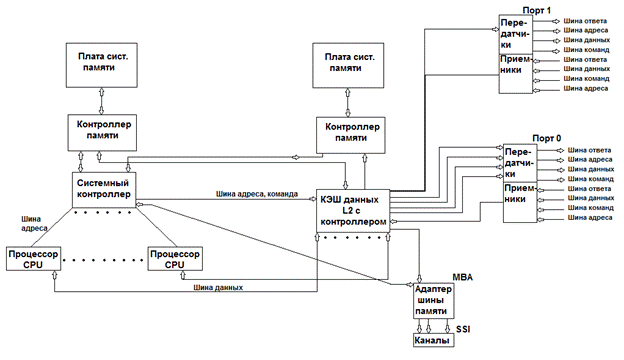
как видно из блок-схемы системный контроллер связан с кэш контроллером шиной адреса и командой этот тракт используется как для обращения в память своего узла,так и отдаленные через две группы приемо-передатчиков, служащих для организации двух кольцевого интерфейса для передачи информации в разных направлениях, структура которого изображена на нижеприведенной схеме.
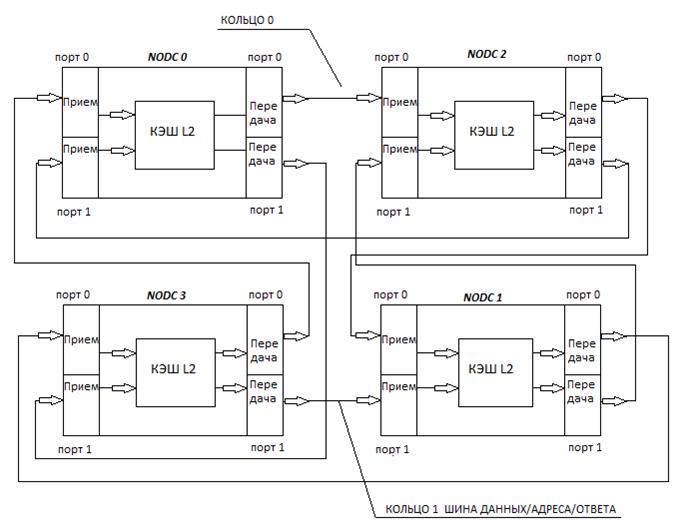
Для объединения узлов (модулей, на каждом из которых конструктивно расположены отдельные SMP) в системах CC-NUMA была использована кольцевая технология, причем в данной архитектуре отсутствуют конструктивно «связные» платы, а другие передачи сообщений (запросов за данными) в удаленные узлы возложены на системный контроллер в каждом узле и контролеры КЭШ L2. Кольцевая схема соединения узлов между собой состоит из 2х «колец» причем передача запросов за данным исходным узлом осуществляется одновременно в обоих кольцах, в которых сообщение передается в противоположных направлениях. Для организации 2х кольцевой схемы системный контроллер и КЭШ L2 имеют по 2 приема/передающих порта, которые и позволяют организовывать выше упомянутой архитектуре соединение узлов. То есть каждый кольцевой порт состоит из входных и выходных шин предназначенных для приема/передачи адреса/команды/данных и ответа. Одним из преимуществ такого соединения от других кольцевых топологий переключающих схем является сокращение ожидания времени выборки при обращении в КЭШ L2 или память другого узла. Так как было отмечено выше запрос состоящей из команды, и адреса одновременно передается в противоположных направлениях из запрашивающегося узла, то каждый узел, обрабатывает запрос в своей собственной директории (таблице) сравнивает результат обработки с входным соответствием, сформированным в предыдущем узле по ходу передачи запроса на кольце. Результат сравнения используется для формирования ответа для передачи его в следующий узел, так как в системе имеется два кольца, то каждый узел формирует ответ дважды во время передачи запроса в системе. Ответ, формируемый на 1ом кольце, содержит состояние только тех узлов, к которым было уже обращение за данными, другими словами говоря, ответ, формируемый на 1-ом кольце содержит указатель на «хозяина» затребованных данных. Ответ, продвигаемый по второму кольцу узлами, который они сформировали на полученный запрос, содержит состояние, касающиеся данного запроса в системе. Иначе результатом ответа на втором кольце является информация о движении и состоянии запрашиваемой строки в системе.
Данные же к запрашиваемому узлу передаются от источника по одному из колец в зависимости от их физического расположения на кольце по кротчайшему пути.
Для поддержания протокола когерентности КЭШ в данной архитектуре не используется протокол SCI, основанный на формировании связанных списков, отражающих перемещение строк в системе, а используется расширенный протокол MESI с вводом 2х дополнительных состояний строк, отражающих их перемещение в системе и их достоверность.
IM -(intervertcon master) Когда IM=1 для адреса строки, это состояние указывает, этот данный узел является последним, получившим право собственности на содержимое строки и записав её содержимое в свою КЭШ L2. По определению не может быть больше одного узла в системе с такими состояниями строки. Более того если состояние строки (данных) по данному адресу будет изменено этим узлом, то бит IM остается активным, так как данные содержатся только в одном КЭШ L2 системы.
При этом если IM=1, то это указывает на то что, копии этой строки могут быть использованы в других узлах только для чтения.
MC=1 IM=0 Строка находится в КЭШ L2 и может быть использовано только одно чтение для одного CP, или для всех в узле.
MC=1 IM=1 Строка может быть изменена или изменена в самом источнике КЭШ L2.
MC=0 IM=1 Строка может быть изменена или соответствовать содержимому в памяти, находится только в КЭШ L2 источника использована в одном или во всех процессорах узла-источника или предназначена для передачи в другие узлы.
Комбинация состояний дополнительных битов отражает выше приведенные ситуации размещения и состояния строки в системе.
Директория когерентности памяти в Z -серверах
Для контроля над когерентностью данных в системе SMP в Z -серверах имеются, так называемые, директории когерентности памяти (таблицы), в которых отслеживается достоверность данных блоков памяти в системе и их перемещение между узлами SMP. Для этого таблицы содержат биты RAT (Remote access tag), которые фиксируют кэширование блоков источника-узла в других узлах системы.
Директории (таблицы), которые содержатся в каждом из узлов в контроллерах кэшей L2, отражают истинное состояние и местонахождения блоков памяти. Если фиксировать состояние и перемещение данных каждого адреса памяти в системе, то структура такой директории будет причиной перегрузки трафика в системе. Поэтому для исключения такой ситуации осуществляют контроль над перемещением блоков данных большого размера, достаточных для размещения целых приложений. То есть обмен между SMP в Z -архитектуре осуществляется даже не строкой, являющейся единицей обмена между памятью и кэшами внутри SMP, а блоками размером 16Мбт
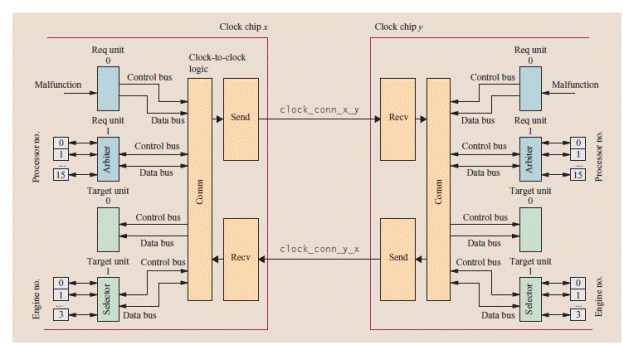
ОсобенностьюSMP c межмодульными связями на базе процессоров Zархитектуры является наличие канальной системы и сервисного процессора,который выполняет функции координатора системы.Для обеспечения этих функций сервисный процессор имеет своих “помощников”,так называемых FSP- сервисных процессоров,которые находятся в каждой отдельной SMP. Именно через эти процессора основной координатор SE и осуществляет управление и контролирует состояние системы.
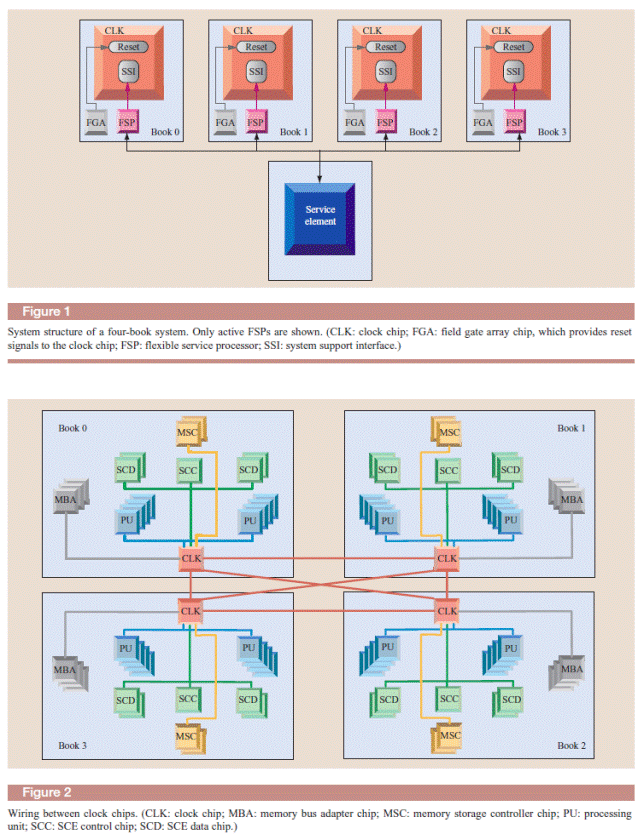
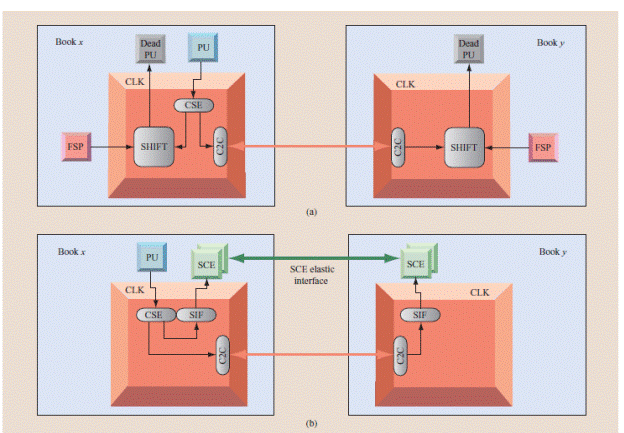
Из второго приведенного рисунка видно,что связь между SMP осуществляется через коммуникационные узлы- блоки синхронизации,к которым подключены все функциональные блоки внутри каждой SMP. Эти блоки соединены между собой перекрестными связями, осуществляющие объединение четырех SMP в одну систему. Для каких же целей используются эти связи? Да, основной поток данных для обмена междуSMP осуществляется на уровне КЭШей второго уровня,объединенных между собой в кольцевую схему. А вот интерфейс между блоками синхронизации используется для передачи конфигурационной и управляющей информации между SMP.Конфигурационная информация содержит данные о наличии чипов в системе и их состоянии. Так каждый блок синхронизации получает информацию не только о состоянии чипов в своей SMP,но и в других без привлечения для этой цели сервисного процессора.Связь между любыми двумя блоками двунаправленная и осуществляется посылкой длинных и коротких сообщений. Длинные сообщения предназначаются для передачи приема данных,короткие служат для подтверждения их приема и содержат информацию состояния идентификаторов на шине.Данная топология соединения дает возможность выполнять функции контроля и управления из любого процессора в системе как в собственной SMP,так и лбой без привлечения для этой цели сервисного процессора в своей SMPили основного сервисного процессора системы. Например.,при выходе из строя одного из процессоров возникает ситуация,требующая ввод в работу запасного с предварительной выгрузкой даныых из сбойного в системную память. Эта работа может быть выполнена аппаратной логикой в блоке синхронизации без участия сервисных процессоров и привлечения их в работу уже на этапе диагностики.Другим примером использования перекрестных связей между блоками синхронизации для выполнения операции управления может служить передача данных между SMP узлами предварительно требующая синхронизации, то есть подготовки целевой кэш для приема запроса в нее.Так как процессор который формирует запрос за данными в другуюSMP может иметь только непосредственную связь со своим контроллером,то для того чтобы осуществить связь с другой кэш L2 на кольце и используется перекрестная связь
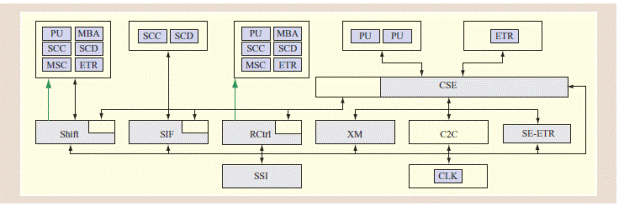
CSE-clock support element-интерфейс для связи между процессорами
SHIFT-интерфейс ко всем чипам в SMP для передачи данных
RCtrl-интерфейс ко всем чипам в SMP для передачи управляющих функций
XM- внутренняя логика блока синхронизации ответственная за передачу сообщений (сервисных слов)
SSI- интерфейс для связи с сервисным процессором
Лекция N14
1.Организация мультипроцессорных систем с координатными коммутаторами.
2.Многопроцессорные системы на базе процессоров POWER.
Раннее рассмотренная нами симметричная мультипроцессорная система с шинной организацией по своим функциональным и физическим характеристикам не может обеспечить число агентов больше пятнадцати. Для увеличения числа агентов приходится организовывать несколько шин и связывать их между собой специальными коммутирующими устройствами. Такое построение системы приводит к организации кластерной архитектуры, как это сделано в спецификации SMP процессоров PENTIUM фирмы INTEL.
Для увеличения количества агентов на шине в SMP пришлось отказаться от шинной организации и использовать координатные коммутаторы, эта топология позволила увеличить количество процессоров на шине до 512.
Логическая организация координатного коммутатора очень схожа с организацией матрицы запоминающих элементов в модуле памяти, с той лишь разницей, что коммутатор решает обратную задачу.
Если запоминающий элемент в матрице выбирается при одновременной активизации горизонтальной и вертикальной линий выборки, то в координатном коммутаторе при активизации коммутирующего устройства происходит гальваническая связь двух координат находящихся в узле, таким образом, происходит связь одной из входных линий с любой другой выходной линией.
Если входные линии коммутатора подсоединить к процессорным элементам, а выходные к модулям памяти, то в результате каждый процессор будет иметь возможность соединения с любым модулем памяти.
Если осуществлять не статическое подключение к входам коммутатора, а динамическое то при ситуации, когда уже будет установлено N-1соединение и абоненту потребуется модуль памяти, который не занят, всегда найдется свободный координатный узел, через который будет произведено соединение.
По этой причине координатный коммутатор относят к категории неблокируемых сетей. Недостатком коммутатора является число коммутационных узлов, которое растет как N*2, где N число входов/выходов коммутатора.
Существуют другие архитектуры соединения, которые являются блокируемыми, но их достоинство- это меньшее наличие коммутационных узлов. Примером такого соединения может служить сеть OMEGA, представляющая из себя набор коммутаторов с двумя входными и двумя выходными линиями,
.
__
ВЫХ1= ВХ1^Xi V ВХ2^Хi
__
ВЫХ2 = ВХ2^Хi V ВХ1^Хi
Количество уровней, на которых происходит сравнение i-тых разрядов адресов приемника, определяется величиной log2N, где N число коммутируемых процессоров с N числом модулей памяти. Количество же узлов коммутации на каждом уровне будет определятся как N/2. То есть общее число коммутирующих узлов сети будет N/2log2N.
Рассмотрим в качестве примера построение сети для соединения восьми процессоров с восемью модулями памяти.
Для адресации потребуется трехразрядный двоичный код с кодированием 000-111. Процессор 0 и блок его модуля кодируем кодом 000 и так далее до конца то есть процессор7 и его модуль памяти имеют код 111. И так на первом этапе коммутационной сети имеем четыре коммутирующих узла, которые в зависимости от значения старших разрядов адресов модулей памяти будут осуществлять коммутацию пакетов от процессоров к модулям памяти на ВЫХ1,имеющих адреса 0XX, а на ВЫХ2 1XX.
То есть на первом этапе определяется, в какой из двух групп по четыре модуля памяти в каждой группе находится адресуемый модуль.
Коммутируя выходы ВЫХ1 коммутирующих узлов первого уровня соответственно на входы ВХ1,ВХ2 двух коммутирующих узлов второго уровня, а ВЫХ2 на входы ВХ1,2 двух других узлов того же уровня, формируем вторую ступень коммутационной сети с выходов которой, будут следовать сообщения к модулям памяти с адресами 00X, 01X, 10X, 11X. Третий уровень коммутации, анализируя младший разряд адресуемого модуля памяти, направляет к нему сообщение.
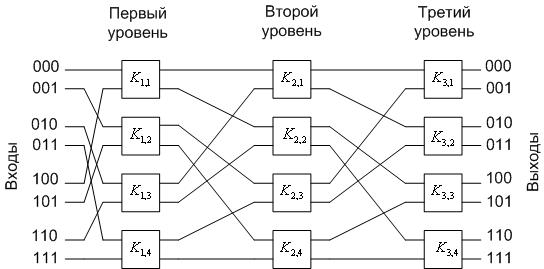
Пример 1
Положим, что входу 011 необходимо соединение с выходом 110. Тогда коммутатор 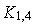 анализирует первый (старший) разряд номера выхода. Он равен «1», поэтому коммутатор соединяет вход 011 со своим нижним выходом, т.е. с коммутатором
анализирует первый (старший) разряд номера выхода. Он равен «1», поэтому коммутатор соединяет вход 011 со своим нижним выходом, т.е. с коммутатором 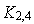 . Аналогично, на основе анализа второго разряда требуемого номера входа коммутатор соединяет свой вход со своим нижним выходом, т.е. с коммутатором
. Аналогично, на основе анализа второго разряда требуемого номера входа коммутатор соединяет свой вход со своим нижним выходом, т.е. с коммутатором 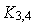 . Наконец, на основе анализа третьего (младшего) разряда коммутатор соединяет свой вход со своим верхним выходом
. Наконец, на основе анализа третьего (младшего) разряда коммутатор соединяет свой вход со своим верхним выходом
Омега-коммутатор также представляет собой блокирующую коммуникационную сеть.
Составные коммутаторы.
Основная идея создания составных коммутаторов состоит в объединении простых коммутаторов каналами типа «точка - точка». Составной коммутатор требует меньше оборудования, чем простой коммутатор с таким же количеством входов – выходов. Однако составной коммутатор при этом имеет большую задержку на коммутацию, которая растет пропорционально количеству уровней коммутации (см. ниже).
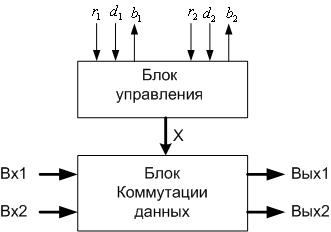
Чаще всего составные коммутаторы строятся на основе 2*2 простых коммутаторов с пространственным разделением - см. Рис.3.
|
Рис. 3. Упрощенная схема 2*2 простого коммутатора с пространственным разделением.
Функционированием блока коммутации управляет блок управления с помощью бинарной переменной 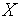 : если =0 - выполняется прямое соединение входов и выходов (Вход 1 – с Выходом 1, а Вход 2 – с Выходом 2); если =1 - выполняется перекрестное соединение входов и выходов (Вход 1 – с Выходом 2, а Вход 2 – с Выходом 1). Блок управления также производит арбитраж запросов входов, если они требуют соединения с одним выходом.
: если =0 - выполняется прямое соединение входов и выходов (Вход 1 – с Выходом 1, а Вход 2 – с Выходом 2); если =1 - выполняется перекрестное соединение входов и выходов (Вход 1 – с Выходом 2, а Вход 2 – с Выходом 1). Блок управления также производит арбитраж запросов входов, если они требуют соединения с одним выходом.
Управление производится на основе бинарных управляющих сигналов 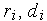 . К примеру,
. К примеру, 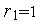 означает запрос Входа 1 на коммутацию;
означает запрос Входа 1 на коммутацию; 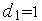 при означает, что требуется соединение Входа 1 с Выходом 1. В случае конфликта (когда и , и
при означает, что требуется соединение Входа 1 с Выходом 1. В случае конфликта (когда и , и 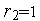 ), выполняется запрос
), выполняется запрос 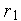 , а источнику второго входного сигнала передается сигнал занятости
, а источнику второго входного сигнала передается сигнал занятости 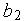 =1. Заметим, что управляющие сигналы
=1. Заметим, что управляющие сигналы 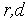 могут быть выработаны в самом блоке управления, если данные, поступающие на вход коммутатора, предварить требуемым номером выхода (в составных коммутаторах именно так и делается).
могут быть выработаны в самом блоке управления, если данные, поступающие на вход коммутатора, предварить требуемым номером выхода (в составных коммутаторах именно так и делается).
Коммутатор Клоза. В качестве примера составного коммутатора рассмотрим коммутатор Клоза. Коммутатор состоит из трех уровней коммутации – входного, промежуточного и выходного. Коммутатор Клоза имеет одинаковое количество входов и выходов 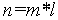 и состоит из
и состоит из 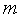 входных
входных  простых коммутаторов, из таких же выходных коммутаторов и из
простых коммутаторов, из таких же выходных коммутаторов и из  промежуточных
промежуточных 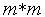 простых коммутаторов.
простых коммутаторов.
|
Рис. 4. Пример коммутатора Клоза (управляющие сигналы не показаны). m =3, l =4. K – простой коммутатор.
Соединения простых коммутаторов в коммутаторе Клоза выполняется по следующему правилу (см. рис. 4):
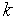 -й выход коммутатора
-й выход коммутатора 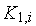 соединяется с
соединяется с 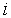 -м входом коммутатора
-м входом коммутатора 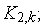
-й вход коммутатора 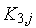 соединяется с
соединяется с 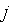 -м выходом коммутатора
-м выходом коммутатора 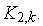
Общее количество простых коммутаторов в коммутаторе Клоза равно 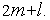
Коммутатор Клоза представляет собой блокирующую коммуникационную сеть. Вход здесь может получить отказа от соединения из-за занятости какого-либо простого коммутатора.
Симметричные мультипроцессорные системы на базе процессоров POWER.
Отличительной особенностью этой архитектуры является отказ от шинной организации и использование топологии точка-точка для соединения узлов системы между собой. Мы уже рассматривали подобную архитектуруSMP,используемую в Zсерверах. Может возникнуть вопрос. Чем же интересна архитектура SMP на базе процессоров POWER и чем она отличается от SMP в Zархитектуре? Ну, в первых, процессора линейки POWER являются RISC процессорами и имеют структуру системы ввода вывода отличную от используемой в SMP Zархитектуры. ВZархитектуре используется, как мы говорили, канальная система, а в POWER-шинная организация.
Zархитектура является дальнейшим развитием архитектуры манфреймов IBM360,370 поэтому увеличение вычислительных мощностей в направлении создания многопроцессорных систем и многомашинных комплексов исторически шло по пути эволюционного развития, включающего в себя модернизацию межпроцессорных связей, связей на уровне каналов и внешних устройств.
Линейка процессоров POWER была разработана намного позже, представляющая из себя RISC процессора в основном использующими шинную организацию как для связи с внешними устройствами и памятью,так и организации SMP.Но фирма IBM, верная своим традициям, не пошла по пути шинной организации SMP,как например INTEL, а осталась верна им, то есть использовала технологию межмодульных связей между узлами в системе.
С другой стороны интерес к SMPна базе процессоров POWER можно объяснить тем, что данная архитектура была разработана с учетом иметь возможность их объединения через внешние коммутаторы, таким образом, являясь базовыми узлами для построения мультикомпьютеров класса MPP, которые мы рассмотрим позже.
SMP на базе POWER имеют возможность расширения для формирования структур CC-NUMA,как и SMP в Zархитектуре, как мы убедимся позже. Основная первоначальная цель увеличения узлов SMP на базе процессоров POWER была- это организация MPP структур,хотя в дальнейшем эти SMP стали с успехом использоваться для построения кластеров. Увеличение узлов SMP в системе с Z архитектурой имеет основную цель- формирование кластерных структур за счет того, чтоSMP Zархитектуры имеет мощную систему ввода вывода с сетевой топологией, позволяющей их организацию, как на логическом, так и физическом уровнях.
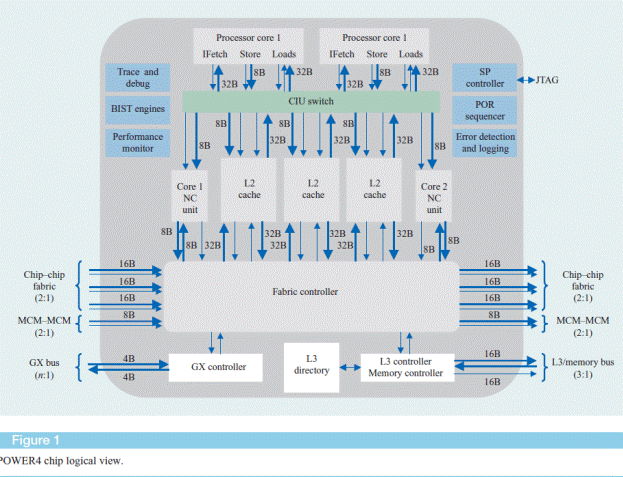
На рисунке показаны логические связи 4х POWER4 чипов,использующих четыре логические шины для формирования 8 канальнойSMP. Каждый чип,представляющий 2х процессорную SMP,производит запись на собственную шину, осуществляя арбитраж между агентами шины: L2, I/Oконтроллером,и L3 контроллером.
Каждый из 4х чипов контролирует все шины и если он определяет, что транзакция должна быть выполнена им,он берет управление на себя.
Запросы за данными из L2 отслеживаются всеми чипами с целью
- находятся ли затребованные данные в его L2 и состоянии,которое позволяет их передавать в запрашиваемый чип L2.
-находятся ли затребованные данные в его L3или системной памяти
Если так, то чип возвращает данные на шину запрашиваемого чипа.
Топология с точки зрения внутренних соединений внутри чипа представляет из себя шинную организацию, но за счет того,что каждый чип имеет дополнительные шины адреса данных и управления в 3х комплектах для соединения с 3мя подобными чипами, то с точки зрения внутри модульного соединения между чипами связи эти трактуютcя как соединения точка- точка.
И так 8канальная SMP формируется путем объединения 2х процессорных чипов,каждый из которых имеет Switch для соединения с другими чипами.
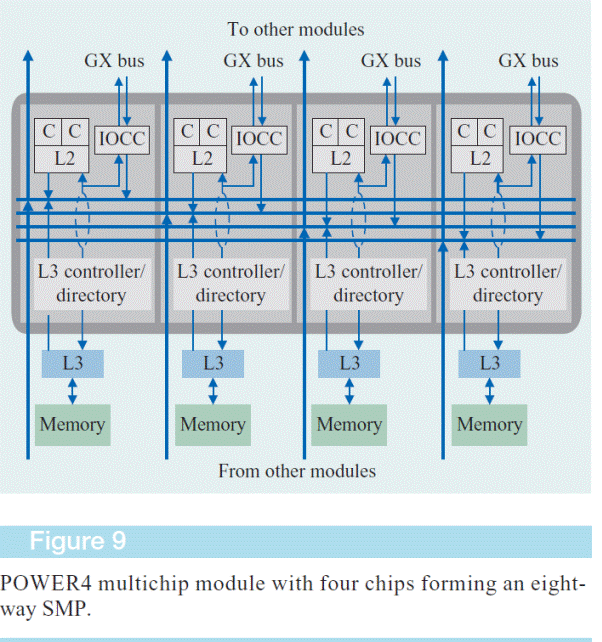
Для формирования архитектуры CC-NUMA свитчи имеют каналы межмодульных связей, таким образом давая возможность расширения числа SMPв системе. Так как в модуле находятся 4 свитча, а каждый свитч, как уже мы сказали,имеет входную и выходную шину для межмодульной связи с другими модулями,то максимальное количество модулей в системе с POWER4 может быть тоже 4 или формировать 8х4=32процессорную систему путем объединения одноименных чипов в кольцо в результате чего в системе формируется 4 кольца, связи между которыми осуществляются в свитчах, благодаря наличию меж точечных соединений внутри модуля. Для пояснения работы ниже приведена схема
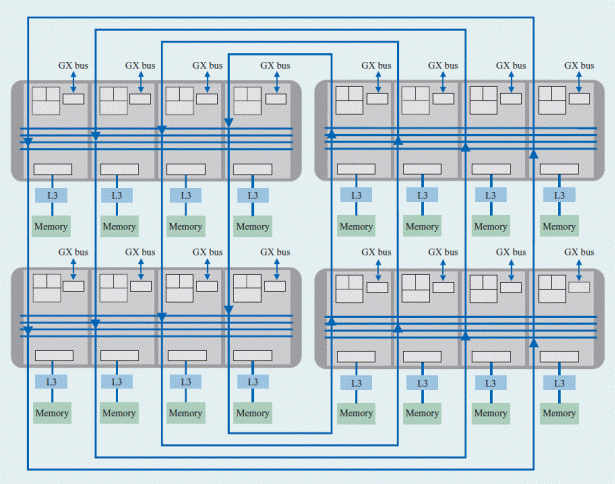
SMPна базе процессоровPOWER5 первого уровня, как для SMPна базе процессоров POWER4 объединяет 4 чипа. Звенья когерентности поддерживают топологию точка-точка, а вот тракты данных каждого свитча чипа объединены между собой в модуле по кольцевой схеме, причем по двум кольцам,передающим данные между свитчами в противоположных направлениях.
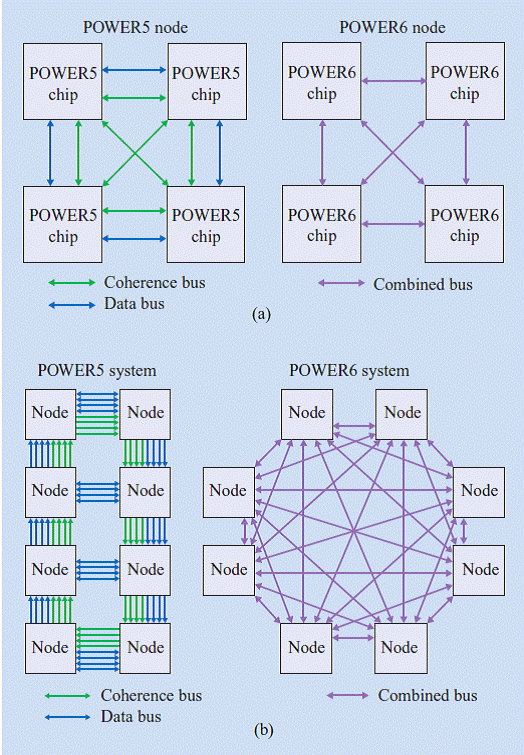
Структура SMPYF на базе POWER6 также как и POWER5,4 состоит из 4х чипов, но имеет несколько другую топологию. Во первых для передачи сигналов когерентности и данных используется одно и то же физическое звено путем мультиплексирования то есть временного разделения. Внутри модуля каждый чип соединен с другими чипами по технологии точка-точка то есть каждый чип со всеми другими.
Многопроцессорная система на базе POWER5дает возможность объединения до 8 модулей с параллельной кольцевой топологией с общим числом процессоров до 64. В соответствии с архитектурным решением как звенья когерентности,так и данных организованы так, что каждый чип внутри модуля подсоединен к чипам в других модулях,имеющими связь с аналогично расположенными физически шинами то есть формируется однонаправленное кольцо. Для системы с 4 чипами в каждом модуле формируется 4 параллельных кольца, проходящих через каждый модуль. Каждый свитч чипа имеет дополнительный выход (КООРДИНАТА Y) для соединения между модулями.
Для POWER6 топология была изменена и в основе соединения модулей была использована технология точка-точка то есть в каждом свитче чипа были введены два входных и два выходных звена для соединения между модулями. Таким образом каждый модуль стал иметь возможность для подсоединения по 8 направлениям.7 из 8 направлений используется для к 7 остальным модулям в 8модульной системе, имеющей 64 процессора.
Лекция n15
Мультикомпьютеры классаMPP. Общие понятия.Принципы организации.
Примеры архитектур мультикомпьютеров класса MPP.
Системы с массовым параллелизмом (MPP-системы)
Основным признаком, по которому вычислительную систему относят к архитектуре с массовой параллельной обработкой (МРР, Massively Parallel Processing), служит количество процессоровn. Строгой границы не существует, но обычно при n >=128 считается, что это уже МРР, а приn<=32 — еще нет. Обобщенная структура МРР-системы показана ниже.
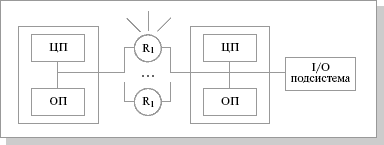
Схематический вид архитектуры MPP-системы
MPP – массивно-параллельная архитектура. Главная особенность такой архитектуры состоит в том, что память физически разделена. В этом случае система строится из отдельных модулей, содержащих процессор, локальный банк операционной памяти (ОП), коммуникационные процессоры (роутеры) или сетевые адаптеры, иногда – жесткие диски и/или другие устройства ввода/вывода. По сути, такие модули представляют собой полнофункциональные компьютеры. Доступ к банку ОП из данного модуля имеют только процессоры (ЦП) из этого же модуля. Модули соединяются специальными коммуникационными каналами. Пользователь может определить логический номер процессора, к которому он подключен, и организовать обмен сообщениями с другими процессорами.
Используются два варианта работы операционной системы (ОС) на машинах MPP-архитектуры. В одном полноценная операционная система (ОС) работает только на управляющей машине (front-end), на каждом отдельном модуле функционирует сильно урезанный вариант ОС, обеспечивающий работу только расположенной в нем ветви параллельного приложения. Во втором варианте на каждом модуле работает полноценная UNIX-подобная ОС, устанавливаемая отдельно.
Главные особенности, по которым вычислительную систему причисляют к классу МРР, можно сформулировать следующим образом:
стандартные микропроцессоры;
физически распределенная память;
сеть соединений с высокой пропускной способностью и малыми задержками;
хорошая масштабируемость (до тысяч процессоров);
асинхронная MIMD-система с пересылкой сообщений;
программа представляет собой множество процессов, имеющих отдельные адресные пространства.
Главным преимуществом систем с раздельной памятью является хорошая масштабируемость: в отличие от SMP-систем, в машинах с раздельной памятью каждый процессор имеет доступ только к своей локальной памяти, в связи с чем не возникает необходимости в потактовой синхронизации процессоров. Практически все рекорды по производительности на сегодня устанавливаются на машинах именно такой архитектуры, состоящих из нескольких тысяч процессоров (TOP 500).
Недостатки:
отсутствие общей памяти заметно снижает скорость межпроцессорного обмена, поскольку нет общей среды для хранения данных, предназначенных для обмена между процессорами. Требуется специальная техника программирования для реализации обмена сообщениями между процессорами;
каждый процессор может использовать только ограниченный объем локального банка памяти;
вследствие указанных архитектурных недостатков требуются значительные усилия для того, чтобы максимально использовать системные ресурсы. Именно этим определяется высокая цена программного обеспечения для массивно-параллельных систем с раздельной памятью.
Системами с раздельной памятью являются суперкомпьютеры МВС-1000, IBM RS/6000 SP, SGI/CRAY T3E, системы ASCI, Hitachi SR8000, системы Parsytec.
Машины последней серии CRAY T3E от SGI, основанные на базе процессоров Dec Alpha 21164 с пиковой производительностью 1200 Мфлопс/с (CRAY T3E-1200), способны масштабироваться до 2048 процессоров.
При работе с MPP-системами используют так называемую Massive Passing Programming Paradigm – парадигму программирования с передачей данных (MPI, PVM, BSPlib).
Основные причины появления систем с массовой параллельной обработкой — это, во-первых, необходимость построения ВС с гигантской производительностью и, во-вторых, стремление раздвинуть границы производства ВС в большом диапазоне, как производительности, так и стоимости. Для МРР-системы, в которой количество процессоров может меняться в широких пределах, всегда реально подобрать конфигурацию с заранее заданной вычислительной мощностью и финансовыми вложениями.
Если говорить о МРР как о представителе класса MIMD с распределенной памятью и отвлечься от организации ввода/вывода, то эта архитектура является естественным расширением кластерной на большое число узлов. Отсюда для МРР-систем характерны все преимущества и недостатки кластеров, причем в связи с повышенным числом процессорных узлов как плюсы, так и минусы становятся гораздо весомее.
Характерная черта МРР-систем – наличие единственного управляющего устройства (процессора), распределяющего задания между множеством подчиненных ему устройств, чаще всего одинаковых (взаимозаменяемых), принадлежащих одному или нескольким классам. Схема взаимодействия в общих чертах довольно проста:
центральное управляющее устройство формирует очередь заданий, каждому из которых назначается некоторый уровень приоритета;
по мере освобождения подчиненных устройств им передаются задания из очереди;
подчиненные устройства оповещают центральный процессор о ходе выполнения задания, в частности о завершении выполнения или о потребности в дополнительных ресурсах;
у центрального устройства имеются средства для контроля работы подчиненных процессоров, в том числе для обнаружения нештатных ситуаций, прерывания выполнения задания в случае появления более приоритетной задачи и т. п.
В некотором приближении имеет смысл считать, что на центральном процессоре выполняется ядро операционной системы (планировщик заданий), а на подчиненных ему — приложения. Подчиненность между процессорами может быть реализована как на аппаратном, так и на программном уровне.
Вовсе не обязательно, чтобы МРР-система имела распределенную оперативную память, когда каждый процессорный узел владеет собственной локальной памятью. Так, например, системы SPP1000/XA и SPP1200/XA являют собой пример ВС с массовым параллелизмом, память которых физически распределена между узлами, но логически она общая для всей вычислительной системы. Тем не менее большинство МРР-систем имеют как логически, так и физически распределенную память.
Проблемы MPP-систем:
Приращение производительности с ростом числа процессоров обычно вообще довольно быстро убывает (по закону Амдала).
Достаточно трудно найти задачи, которые сумели бы эффективно загрузить множество процессорных узлов. Проблема переносимости программ между системами с различной архитектурой.
Эффективность распараллеливания во многих случаях сильно зависит от деталей архитектуры МРР-системы, например топологии соединения процессорных узлов.
Самой эффективной была бы топология, в которой любой узел мог бы напрямую связаться с любым другим узлом, но в ВС на основе МРР это технически трудно реализуемо. Как правило, процессорные узлы в современных МРР-компьютерах образуют или двухмерную решетку (например, в SNI/Pyramid RM1000) или гиперкуб (как в суперкомпьютерах nCube). Поскольку для синхронизации параллельно выполняющихся процессов необходим обмен сообщениями, которые должны доходить из любого узла системы в любой другой узел, важной характеристикой является диаметр системы D. В случае двухмерной решетки D - sqrt(n), в случае гиперкуба D - ln(n). Таким образом, при увеличении числа узлов более выгодна архитектура гиперкуба. Время передачи информации от узла к узлу зависит от стартовой задержки и скорости передачи. В любом случае, за время передачи процессорные узлы успевают выполнить много команд, и это соотношение быстродействия процессорных узлов и передающей системы, вероятно, будет сохраняться — прогресс в производительности процессоров гораздо весомее, чем в пропускной способности каналов связи. Поэтому инфраструктура каналов связи в МРР-системах является объектом наиболее пристального внимания разработчиков. Слабым местом МРР было и есть центральное управляющее устройство (ЦУУ) - при выходе его из строя вся система оказывается неработоспособной. Повышение надежности ЦУУ лежит на путях упрощения аппаратуры ЦУУ и/или ее дублирования. Несмотря на все сложности, сфера применения ВС с массовым параллелизмом постоянно расширяется. Различные системы этого класса эксплуатируются во многих ведущих суперкомпьютерных центрах мира. Следует особенно отметить компьютеры Cray T3D и Cray T3E, которые иллюстрируют тот факт, что мировой лидер производства векторных суперЭВМ, компания Cray Research, уже не ори-ентируется исключительно на векторные системы. Наконец, нельзя не вспомнить, что суперкомпьютерный проект министерства энергетики США основан на МРР-системе на базе Pentium.
CRAY T3D
 Компьютер CRAY T3D - это массивно-параллельный компьютер с распределенной памятью, объединяющий от 32 до 2048 процессоров. Распределенность памяти означает то, что каждый процессор имеет непосредственный доступ только к своей локальной памяти, а доступ к данным, расположенным в памяти других процессоров, выполняется другими, более сложными способами.
Компьютер CRAY T3D - это массивно-параллельный компьютер с распределенной памятью, объединяющий от 32 до 2048 процессоров. Распределенность памяти означает то, что каждый процессор имеет непосредственный доступ только к своей локальной памяти, а доступ к данным, расположенным в памяти других процессоров, выполняется другими, более сложными способами.
CRAY T3D подключается к хост-компьютеру (главному или ведущему), роль которого, в частности, может исполнять CRAY Y-MP C90. Вся предварительная обработка и подготовка программ, выполняемых на CRAY T3D, проходит на хосте (например, компиляция). Связь хост-машины и T3D идет через высокоскоростной канал передачи данных с производительностью 200 Mбайт/с.
Массивно-параллельный компьютер CRAY T3D работает на тактовой частоте 150MHz и имеет в своем составе три основных компонента: сеть межпроцессорного взаимодействия (или по-другому коммуникационную сеть), вычислительные узлы и узлы ввода/вывода.
Вычислительные узлы и процессорные элементы
Вычислительный узел состоит из двух процессорных элементов (ПЭ), сетевого интерфейса контроллера блочных передач. Оба процессорных элемента, входящие в состав вычислительного узла, идентичны и могут работать независимо друг от друга.
Процессорный элемент. Каждый ПЭ содержит микропроцессор, локальную память и некоторые вспомогательные схемы.
Микропроцессор - это 64-х разрядный RISC (Reduced Instruction Set Computer) процессор ALPHA фирмы DEC, работающий на тактовой частоте 150 MHz. Микропроцессор имеет внутреннюю кэш-память команд и кэш-память данных.
Объем локальной памяти ПЭ - 8 Mслов. Локальная память каждого процессорного элемента является частью физически распределенной, но логически разделяемой (или общей), памяти всего компьютера. В самом деле, память физически распределена, так как каждый ПЭ содержит свою локальную память. В тоже время, память разделяется всеми ПЭ, так как каждый ПЭ может обращаться к памяти любого другого ПЭ, не прерывая его работы.
Обращение к памяти другого ПЭ лишь в 6 раз медленнее, чем обращение к своей собственной локальной памяти.
Сетевой интерфейс формирует передачи перед посылкой через коммуникационную сеть другим вычислительным узлам или узлам ввода/вывода, а также принимает приходящие сообщения и распределяет их между двумя процессорными элементами узла.
Контроллер блочных передач - это контроллер асинхронного прямого доступа в память, который помогает перераспределять данные, расположенные в локальной памяти разных ПЭ компьютера CRAY T3D, без прерывания работы самих ПЭ.
Коммуникационная сеть
Коммуникационная сеть обеспечивает передачу информации между вычислительными узлами и узлами ввода/вывода с максимальной скоростью в 140M байт/с. Сеть образует трехмерную решетку, соединяя сетевые маршрутизаторы узлов в направлениях X, Y, Z. Каждая элементарная связь между двумя узлами - это два однонаправленных канала передачи данных, что допускает одновременный обмен данными в противоположных направлениях.
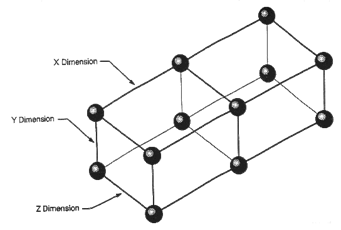
Маршрутизация в сети и сетевые маршрутизаторы.
При выборе маршрута для обмена данными между двумя узлами сетевые маршрутизаторы всегда сначала выполняют смещение по размерности X, затем по Y, а в конце по Z. Так как смещение может быть как положительным, так и отрицательным, то этот механизм помогает минимизировать число перемещений по сети и обойти поврежденные связи.
Сетевые маршрутизаторы каждого вычислительного узла определяют путь перемещения каждого пакета и могут осуществлять параллельный транзит данных по каждому из трех измерений X, Y, Z.
Нумерация вычислительных узлов.
Каждому ПЭ в системе присвоен уникальный физический номер, определяющий его физическое расположение, который и используется непосредственно аппаратурой.
Не обязательно все физические ПЭ принимают участие в формировании логической конфигурации компьютера. Например, 512-процессорная конфигурация компьютера CRAY T3D реально содержит 520 физических ПЭ, 8 из которых находятся в резерве. Каждому физическому ПЭ присваиваится логический номер, определяющий его расположение в логической конфигурации компьютера, которая уже и образует трехмерный тор.
Каждой программе пользователя из трехмерной решетки вычислительных узлов выделяется отдельный раздел, имеющий форму прямоугольного параллелепипеда, на котором работает только данная программа (не считая компонент ОС). Для последовательной нумерации ПЭ, выделенных пользователю, вводится виртуальная нумерация.
Особенности синхронизации процессорных элементов
Для поддержки синхронизации процессорных элементов предусмотрена аппаратная реализация одного из наиболее «тяжелых» видов синхронизации - барьеров синхронизации. Барьер - это точка в программе, при достижении которой каждый процессор должен ждать до тех пор, пока остальные также не дойдут до барьера, и лишь после этого момента все процессы могут продолжать работу дальше
Cистема RS/6000SP2
В 2008 году IBM объявила о создании процессорных систем реализованных в серверах серии «Power». эта серия появилась в результате объединения двух независимых друг от друга серий «Power» и серверов I серии, возникновение которых имело достаточно интересную историю. Обе эти серии имеют одинаковую аппаратную платформу, в которой в качестве базовых узлов используются последние модели линейки процессоров POWER, что и послужило, в конечном счете, объединения этих двух серий в одну.
Началом появления серверов «Power» считается 1991 год, которые были созданы на базе системы RS/6000 SP, представляющую многопроцессорную систему класса MPP, узлами которой были процессоры «Power» 3, объединенные между собой через высокоскоростной свитч SP2 c пропускной способностью портов в дуплексном режиме
700 мгб/сек и задержкой в 17 мсек. Прежде чем давать краткую характеристику этой системе, на базе которой и появилось линейка серверов р серии, необходимо отметить что, архитектура RS/6000 SP – это результат многолетнего сотрудничества не только подразделений фирмы IBM.
В 1990 году подразделение фирмы IBM – AWD(Advanced Workstation Division), занимающиеся разработкой рабочих станций представила на рынок RS/6000 с операционной системой UNIX
С использованием аппаратной платформы на базе расширенной RISC архитектуры процессоров Power.
В это время лаборатория HPSSDL (High Performance Supercomputer System Development Laboratory), основанная в 1980 году занимается разработкой суперкомпьютеров и имея, богатый опыт в разработке технологий манфреймов заинтересовалась RS/6000 и стала экспериментировать с объединением этих рабочих станций в систему, используя для этого ESCON директор.
В 1991 году подразделение IBM в Нью-Йорке занимаясь разработкой высокоскоростного свитча совместно с другим подразделением, занимающегося программным обеспечением и выше упомянутой лабораторией HPSSDL, объединившись за 12 месяцев, разработали систему, в которой стандартные рабочие станции RS/6000 были адаптированы для совместного использования с новой версией свитча, разработанного в Нью-Йорке на базе ESCON технологии. Данная система была зарегистрирована в 1993 году как SP1.
В 1994 году объединенная группа, занимающаяся разработкой SP1 прекратила свое существование ввиду окончания выпуска на рынок продукции, а Нью-Йоркская часть объединенной группы, взяв из системы наработки по управлению системой и внедрив в ней новые поддержки для параллельной обработки программ создала новую версию SP2, которая открыла путь для разработки высокоскоростного свитча HIPS с пропускной способностью
48 мб/сек и задержкой в 30 мсек. Группа, занимающаяся разработкой SP2, выйдя из состава объединенной группы, вновь стала подчиненной фирмы IBM. К концу 1994 года было выпущено 352 системы, а концу 1995 – 1023.
В 1996 году система SP2 была переименована в SP и формально стала частью системы RS/6000.
SP-SMP узлы были введены в состав системы, а SP свитч к концу 1999 года имел пропускную способность 180 мгб/сек и задержку в 21 мсек.
Краткая характеристика RS6000/ SP
Базовым блоком системы являлся процессорный узел, представляющий SMP из Power3 или Power PС память, шину PСI, и диски.
В зависимости от типа узлов система могла содержать до 16 узлов, размещаемых в одном фрейме.
Фреймы в свою очередь могли соединяться между собой, организуя кластер, состоящий из 128 узлов. Каждый узел содержал свою собственную копию операционной системы AIX. Система управлялась AIX операционной системой и комплектом управляющих программ, предназначенных для параллельной обработки приложений (PSSP-Parallel System Support Programs), из узла так называемого CWS (Control Work Station). Это был один из первых шагов к внедрению технологии кластеризации в системе с параллельной обработкой.
Управляемая AIX и PSSP из центра управления CWS система представляет из себя классическую структуру, узлы которой соединялись через SP SWitch. В системе могла производиться обработка как последовательных, так и параллельных программных приложений одновременно. Для научных и технических приложений система SP/CES представляла широкую область вычислений от задач структурного анализа и обработки систематических данных до молекулярного моделирования.
Открытая архитектура базируется на AIX операционной системе. Это давало возможность интеграции SP/CES системы в уже существующее оборудование. И так работающие станции RS6000 процессоров Power-3 были переименованы в серверов р серии.
Продолжая традиции внедрения достижений в области функциональных возможностей из других направлений средств вычислительной техники, IBM создала сервер Р690, ставший базовым для системы IBM LPAR UNIX. В этом сервере в качестве базового узла стала архитектура, которая дала возможность организации логических партаций и имела для связи с другими чипами сетевой коммутатор, дающий возможность, как и Power3 организацию SMP.
С другой стороны возросшая мощность конечных узлов, представляющие отдельные SMP стала причиной конфликтов между ними и SP со своим программным об
|
|
|
|
|
Дата добавления: 2014-01-03; Просмотров: 1493; Нарушение авторских прав?; Мы поможем в написании вашей работы!