КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Методические указания
|
|
|
|
Корреляционный анализ, разработанный К. Пирсоном и Дж. Юлом, является одним из методов статистического анализа взаимозависимости нескольких признаков.
Связь, при которой каждому значению аргумента соответствует не одно, а несколько значений функций и между аргументом и функцией нельзя установить строгой зависимости, называется корреляционной.
В настоящее время корреляционный анализ (корреляционная модель) определяется как метод, применяемый тогда, когда данные наблюдений или эксперимента можно считать случайными и выбранными из генеральной совокупности, распределенной по многомерному нормальному закону.
После того, как с помощью корреляционного анализа выявлено наличие статистически значимых связей между переменными и оценена степень их тесноты, обычно переходят к математическому описанию конкретного вида зависимостей с использованием регрессионного анализа. С этой целью подбирают класс функций, связывающий результативный показатель y и аргументы x1, x2, …, xk, отбирают наиболее информативные аргументы, вычисляют оценки неизвестных значений параметров уравнения связи и анализируют точность полученного уравнения.
Т.о. регрессионная модель – это функция, описывающая зависимость между количественными характеристиками социально-экономических систем. Они строятся в тех случаях, когда известно, что зависимость между факторами существует и требуется получить ее математическое описание.
Однофакторная (парная) регрессия представляет собой регрессию между двумя переменными – у и х, т.е. модель вида
y =  (x), (1)
(x), (1)
где у – зависимая переменная (результативный признак);
х – независимая, или объясняющая, переменная (признак-фактор).
Различают линейные и нелинейные регрессии.
Линейная регрессия: y = a+bx+e. (2)
Нелинейные регрессии делятся на два класса: регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам:
- полиномы разных степеней y = a+b1·x+b2·x2+b3·x3+ e (3)
- равносторонняя гипербола y = a+b/x+ e (4)
и регрессии, нелинейные по оцениваемым параметрам:
- степенная y = a×xb · e (5)
- показательная y = a·bx · e (6)
- экспоненциальная y = e a+b·x · e (7)
Спецификация модели – формулировки вида модели, исходя из соответствующей теории связи между переменными. В парной регрессии выбор вида математической функции y = 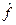 (x) может быть осуществлен тремя методами: графический, аналитический, экспериментальный.
(x) может быть осуществлен тремя методами: графический, аналитический, экспериментальный.
Простейшей системой связи является линейная связь между двумя признаками – парная линейная регрессия. Уравнение парной линейной корреляционной связи называется уравнением парной регрессии и имеет вид:
Ŷ = a+bx, (8)
где ŷ – среднее значение результативного признака у при определенном значении факторного признака х;
а – свободный член уравнения;
b – коэффициент регрессии, измеряющий среднее отношение отклонения результативного признака от его средней величины к отклонению факторного признака от его средней величины на одну единицу его измерения – вариация у, приходящаяся на единицу вариации х.
Построение уравнения регрессии сводится к оценке ее параметров. Для оценки параметров регрессий, линейных по параметрам, используют Метод наименьших квадратов (МНК) МНК позволяет получить такие оценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака у от теоретических ŷ минимальна, т.е.
 å(y – ŷ)2 min
å(y – ŷ)2 min
Система нормальных уравнений:
 na + bå x = å y
na + bå x = å y
aå x + bå x2 = å xy (9)
Можно решить эту систему уравнений по исходным данным или использовать формулы, вытекающие из этой системы:
a =  (10)
(10)
b=  , (10а)
, (10а)
Тесноту связи изучаемых явлений оценивает линейный коэффициент парной корреляции  rxy для линейной регрессии
rxy для линейной регрессии
(-1 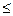 rxy 1);
rxy 1);
rxy=  , (11).
, (11).
Знак коэффициента корреляции показывает направление связи: «+» – связь прямая, «–» – связь обратная. Абсолютная величина характеризует степень тесноты связи. В соответствии со шкалой Чеддока:
Значения 
| 0,1-0,3 | 0,3-0,5 | 0,5-0,7 | 0,7-0,9 | св. 0,9 |
| Сила связи | слабая | умеренная | заметная | высокая | очень высокая |
Если r= 0, то связь между факторами х и у отсутствует.
– связь функциональная.
Индекс корреляции ρ xy характеризует силу связи в нелинейной регрессии. (0 ρ xy 1):
ρxy=  =
=  . (12)
. (12)
Оценку качества построенной модели даст коэффициент (индекс) детерминации, а также средняя ошибка аппроксимации.
Средняя ошибка аппроксимации – среднее отклонение расчетных значений результативного признака от фактических:
 (13)
(13)
Допустимый предел значений  – не более 8 – 10%.
– не более 8 – 10%.
Средний коэффициент эластичности  показывает, на сколько процентов в среднем по совокупности изменится результат y от своей средней величины при изменении фактора x на 1% от своего среднего значения:
показывает, на сколько процентов в среднем по совокупности изменится результат y от своей средней величины при изменении фактора x на 1% от своего среднего значения:
 . (14)
. (14)
Для линейной регрессии
 (15)
(15)
Задача дисперсионного анализа состоит в анализе дисперсии зависимой переменной:
Правило сложения дисперсий:
å(yi -  )2 = å(ŷx - )2 + å(yi - ŷx)2 (16)
)2 = å(ŷx - )2 + å(yi - ŷx)2 (16)
где å(yi - )2 – общая сумма квадратов отклонений – общая дисперсия;
å(ŷx - )2 – сумма квадратов отклонений, обусловленная регрессией (это объясненная или факторная дисперсия)
å(yi - ŷx)2 – остаточная сумма квадратов отклонений.
Долю дисперсии, объясняемую регрессией, в общей дисперсии результативного признака y характеризует коэффициент (индекс) детерминации R2;
 . (17)
. (17)
F-тест – оценивание качества уравнения регрессии – состоит в проверке гипотезы Но о статистической незначимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического F факт и критического (табличного) F табл значений F-критерия Фишера.
Любая сумма квадратов отклонений связана с числом степеней свободы, которое зависит от числа единиц совокупности n и числом определяемых по ней констант (переменных при х)(m).
Dобщ= å(yi - )2 / (n-1)
Dфакт= å(ŷx - )2 / m (18)
Dост= å(yi - ŷx)2 /n-m-1
Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду. Сопоставляя факторную и остаточную дисперсии в расчете на одну степень свободы, получим величину F-критерия:
F = Dфакт/Dост = 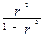 * (n-2) (19)
* (n-2) (19)
где F-критерий для проверки нулевой гипотезы Но: Dфакт = Dост.
Табличное значение F-критерия – это максимальная величина отношения дисперсий, которая может иметь место при случайном их расхождении для данного уровня вероятности (a) наличия нулевой гипотезы (уровень значимости a - вероятность отвергнуть правильную гипотезу при условии, что она верна). Вычисленное значение F-отношения признается достоверным (отличным от единицы), если оно больше табличного. В этом случае нулевая гипотеза об отсутствии связи признаков отклоняется и делается вывод о существенности этой связи: Fфакт > Fтабл – Но отклоняется.
Если эта величина окажется меньше табличного, то вероятность нулевой гипотезы выше заданного уровня (например, 0, 05) и она не может быть отклонена без серьезного риска сделать неправильный вывод о наличии связи. В этом случае уравнение регрессии считается статистически незначимым. Но не отклоняется.
Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитываются t-критерий Стьюдента и доверительные интервалы каждого из показателей, т.е. о незначимом их отличии от нуля. Оценка значимости коэффициентов регрессии и корреляции с помощью t-критерия Стьюдента проводится путем сопоставления их значений с величиной ошибки:
 ;
;  ;
;  (20)
(20)
Случайные ошибки параметров линейной регрессии и коэффициента корреляции определяются по формулам:
 (21)
(21)
где S2 ост – остаточная дисперсия на одну степень свободы.
 (22)
(22)
сравнивая фактическое и критическое (табличное) значения t-статистики принимаем или отвергаем гипотезу Но.
Если t табл < t факт , то Но отклоняется, т.е. a, b, r не случайно отличаются от нуля и сформировались под влиянием систематически действующего фактора x. Если t табл > t факт , то гипотеза Но не отклоняется и признается случайная природа формирования a, b, r.
Для расчета доверительного интервала определяем предельную ошибку ∆ для каждого показателя:
∆a = tтабл ma,
∆b = tтабл mb (23)
Доверительные интервалы рассчитываются следующим образом:
 =a ± Da
=a ± Da  =b ± Db; (24)
=b ± Db; (24)
Если в границы доверительного интервала попадает ноль, т.е. нижняя граница отрицательна, а верхняя положительна, то оцениваемый параметр принимается нулевым, так как он не может одновременно принимать и положительное, и отрицательное значение.
Прогнозное значение результативного признака yp определяется путем подстановки в уравнение регрессии соответствующего прогнозного значения xp. Вычисляется средняя стандартная ошибка прогноза
 =
=  , (25)
, (25)
где 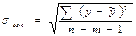 . (26)
. (26)
Далее строится доверительный интервал прогноза:
 ; (27)
; (27)
где  (28)
(28)
|
|
|
|
|
Дата добавления: 2017-02-01; Просмотров: 79; Нарушение авторских прав?; Мы поможем в написании вашей работы!