КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Экспоненциальное сглаживание
|
|
|
|
Адаптивные модели базируются на двух схемах: скользящего среднего (MA -модели) и авторегрессии (АR -модели).
Согласно схеме скользящего среднего, оценкой текущего уровня является взвешенное среднее всех предшествующих уровней, причем веса при наблюдениях убывают по мере удаления от последнего уровня, т. е. информационная ценность наблюдений признается тем большей, чем ближе они к концу интервала наблюдений. Такие модели хорошо отражают изменения, происходящие в тенденции, но в чистом виде не позволяют отражать колебания.
Модель простой экспоненциальной средней описывается выражением:
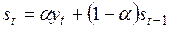 , (5.1)
, (5.1)
и используется, как отмечалось ранее, для сглаживания временных рядов. Для оценки ее текущего значения к величине экспоненциальной средней в момент времени (t-1), взятой с весом (1-α), необходимо добавить величину текущего фактического уровня ряда 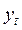 , умноженного на коэффициент α.
, умноженного на коэффициент α.
Рассмотрим процедуры прогнозирования, выполняемые с использованием моделей экспоненциальных средних. Экспоненциальное сглаживание, как указывалось в параграфе 2.3осуществляется по формуле:
 ,
,
здесь β=1-α, или
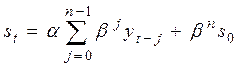 ,
,
где n – количество членов исходного ряда;
s0 - величина, характеризующая начальные условия.
При n→∞ и β<1 коэффициент βn→0, а сумма коэффициентов уровней ряда 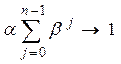 , следовательно, в этом случае экспоненциальная средняя не зависит от начальных условий и полностью определяется суммой произведений уровней ряда на соответствующие им коэффициенты:
, следовательно, в этом случае экспоненциальная средняя не зависит от начальных условий и полностью определяется суммой произведений уровней ряда на соответствующие им коэффициенты:
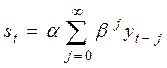 .
.
Таким образом, величина st оказывается взвешенной суммой всех членов ряда, причем веса падают экспоненциально в зависимости от дальности периода наблюдений. Например, если α=0,3, тогда вес текущего наблюдения равен 0,3; вес предыдущего наблюдения yt-1 равен α ּ β=0,3 ּ 0,7=0,21; для наблюдения yt-2 равен α ּ β2=0,3 ּ 0,72=0,147 и т.д.
Пусть модель временного ряда имеет вид:
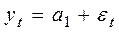 ,
,
где а1=const;
εt – случайные неавтокоррелированные отклонения нулевым математическим ожиданием и дисперсией σ 2.
В работах Р.Брауна показано, что экспоненциальная средняя st имеет то же математическое ожидание, что и ряд yt, но меньшую дисперсию:
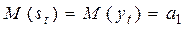 ;
;
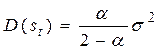 . (5.2)
. (5.2)
Так как 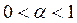 , то дисперсия экспоненциальной средней
, то дисперсия экспоненциальной средней 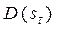 меньше дисперсии временного ряда, равной
меньше дисперсии временного ряда, равной 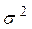 . Из формулы (5.2) видно, что при высоком значении α дисперсия экспоненциальной средней незначительно отличается от дисперсии ряда yt. Чем меньше α, тем в большей степени уменьшается дисперсия экспоненциальной средней, таким образом, экспоненциальная средняя играет роль фильтра, поглощающего колебания исходного временного ряда.
. Из формулы (5.2) видно, что при высоком значении α дисперсия экспоненциальной средней незначительно отличается от дисперсии ряда yt. Чем меньше α, тем в большей степени уменьшается дисперсия экспоненциальной средней, таким образом, экспоненциальная средняя играет роль фильтра, поглощающего колебания исходного временного ряда.
Предположим, что модель временного ряда имеет вид:
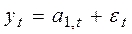 ,
,
где а1,t - изменяющийся во времени средний уровень ряда;
εt – случайные неавтокоррелированные отклонения нулевым математическим ожиданием и дисперсией σ 2.
Прогнозная модель в этом случае имеет вид:
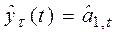 ,
,
где 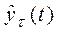 - прогноз, сделанный в момент t на τ шагов вперед;
- прогноз, сделанный в момент t на τ шагов вперед;
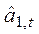 - оценка а1,t.
- оценка а1,t.
Экспоненциальная средняя служит средством оценки единственного параметра модели:
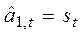 ,
,
т.е. все свойства экспоненциальной средней распространяются на прогнозную модель. В выражении (5.3)
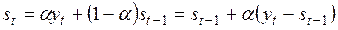 , (5.3)
, (5.3)
полученному из (5.1), величина 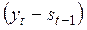 есть погрешность прогноза, а новый прогноз st получается в результате корректировки предыдущего прогноза с учетом его ошибки. В этом и проявляется сущность адаптации этой модели.
есть погрешность прогноза, а новый прогноз st получается в результате корректировки предыдущего прогноза с учетом его ошибки. В этом и проявляется сущность адаптации этой модели.
|
|
|
|
|
Дата добавления: 2014-10-22; Просмотров: 757; Нарушение авторских прав?; Мы поможем в написании вашей работы!