КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Методи навчання нейронних мереж
|
|
|
|
4.1. Навчання нейронних мереж і еталонні дані
Для того, щоб ШНМ могла успішно представляти дані або функ-
ціональну залежність, її потрібно спершу навчити.
Навчання – це процес адаптації мережі до пред’явлених еталон-
них зразків модифікацією (відповідно до того чи іншого алгоритму)
вагових коефіцієнтів зв’язків між нейронами.
Зауважимо, що цей процесс – результат алгоритму функціонування
мережі, а не попередньо закладених у неї знань людини, як це часто бу-
ває в системах штучного інтелекту. Процес навчання повторюється іте-
ративно доти, доки мережа не набуде потрібних властивостей.
Якщо навчання ШНМ відбувається із використанням еталонних
даних, то такий підхід називають «навчанням з учителем» (supervised
training). Еталонні дані складаються з шаблонів. Кожен шаблон, в
свою чергу, складається із вектора відомих входів мережі
і вектора відповідних їм бажаних виходів 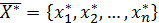
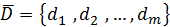 . Коли на вхід ненавченої мережі подається еталон-
. Коли на вхід ненавченої мережі подається еталон-
ний вектор X, вихідний вектор Y = y 1, y 2,…, ym буде відрізнятися 

від вектора бажаних вихідних значень D. У цьому разі функцію по-
хибки роботи ШНМ можна задати у вигляді, що відповідає методу
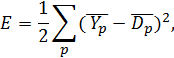 найменших квадратів:
найменших квадратів:
(4.1)
де індекс p означає номер шаблона із еталонних даних. Таким чином похиб-
ка обчислюється як сума похибок за всіма шаблонами еталонних даних.
Слід зазначити, що розроблення адекватних еталонних даних для
навчання – завдання трудомістке і не завжди здійсненне.
4.2. Метод випадкового пошуку (random search)
Під час навчання ШНМ методом випадкового пошуку відбува-
ється динамічне підстроювання вагових коефіцієнтів синапсів, під час
якого вибираються здебільшого найслабкіші зв’язки і змінюються на
малу величину в той чи інший бік. Після цього обчислюють функцію
похибки (4.1) і зберігають тільки ті зміни, які зумовили зменшення
похибки на виході мережі порівняно з попереднім станом.
Очевидно, що цей підхід, попри свою уявну простоту, потребує
значної кількості ітерацій доки буде досягнуто прийнятних похибок
на виході мережі.
|
|
|
|
|
Дата добавления: 2014-11-16; Просмотров: 730; Нарушение авторских прав?; Мы поможем в написании вашей работы!