КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Расчет параметров распределения
|
|
|
|
| Х | Отклонение от среднего (Xi - Mx) | (Xi - Mx) 2 | (Xi - Mx) 3 | (Xi - Mx) 4 |
| -2 | -8 | |||
| -4 | -64 | |||
| -6 | -216 | |||
| -8 | -512 | |||
| SХ=400 Mx=40 | S(Xi - Mx) 2 = =244 | S(Xi - Mx) 3=84 | S(Xi - Mx)4= =12244 |
Модальное значение - 41, поскольку оно встречается дважды. Медиана - 40.5 (пять чисел меньше этой величины, пять больше). Среднее арифметическое равно 400/10=40.
Дисперсия s2 =244/9=27.11
Стандартное отклонение s =5.207.
Коэффициент асимметрии As = 0.011
Коэффициент эксцесса Ex = -1.334
При работе на компьютере параметры распределения можно рассчитать, используя встроенные функции Microsoft Excel. Для этого надо войти в раздел «Анализ данных» из меню «Сервис», где выбрать подраздел «Описательная статистика». На экране при этом высвечивается меню «Описательная статистика», в котором задаются входной интервал переменной и выходной интервал для вывода результатов расчета. Входной интервал переменной задается через двоеточие, например интервал «a1:a24» включает в себя 24 значения переменной в столбце A с 1 по 24 ячейку. Можно рассчитывать параметры распределения сразу нескольких переменных, если они представляют собой единый массив данных. Так, входной интервал a1:c25 включает в себя три переменных по 25 значений в каждой: a1:a25, b1:b25 и c1:c25. Если в первой строке интервала находится заголовок столбца (строки), то это следует указать в специальном окошке меню. В окне «Выходной интервал» следует указать номер левой верхней ячейки выходного интервала. Выходные данные включают среднее арифметическое значение, стандартную ошибку среднего, медиану, моду, стандартное отклонение, дисперсию выборки, коэффициенты эксцесса и асимметрии, размах выборки (обозначен как «Интервал»), минимальное и максимальное значения («Минимум» и «Максимум»), сумму всех значений и количество значений переменных («Счет»). Следует учесть, что в Microsoft Excel коэффициенты асимметрии и эксцесса рассчитываются по формулам, несколько отличающимся от приведенных выше.
3.3 Нормальное распределение
Нормальным называется распределение, относительные частоты f0 которого выражаются формулой:
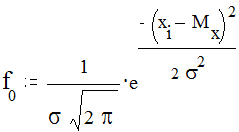
По этой формуле при различных значениях среднего арифметического и стандартного отклонения получается семейство нормальных кривых. Нормальное распределение характеризуется тем, что крайние значения признака встречаются относительно редко, а близкие к среднему арифметическому - относительно часто. Кривая нормального распределения имеет колоколообразную форму - это одномодальное распределение, значения медианы, моды и среднего арифметического которого совпадают между собой, коэффициенты асимметрии и эксцесса равны нулю.
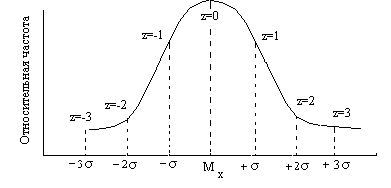
Рис. 4. Кривая нормального распределения.
Кривая ассимптоматически приближается к оси Х, то есть может принимать сколь угодно малые значения по ординате при стремлении Х к плюс или минус бесконечности. В зависимости от величины стандартного отклонения кривая может растягиваться или сжиматься по оси Х, а в зависимости от значения среднего арифметического она будет перемещаться влево или вправо.
Назвали распределение нормальным потому, что оно очень часто встречалось при естественнонаучных исследованиях, и его считали нормой всякого массового случайного проявления признаков. Считается, что нормальное распределение характеризует такие случайные величины, на которое воздействует большое количество факторов, причем сила воздействия одного отдельно взятого фактора значительно меньше суммы воздействия остальных факторов. По нормальному закону распределены многие биологические параметры - например, вес, рост человека. По нормальному закону распределяется и ряд психологических свойств, качеств человека - показатели интеллекта, агрессивности, тревожности и другие. Из этой предпосылки исходят при разработке и стандартизации тестовых методик.
Особое место среди нормальных распределений занимает так называемое стандартное или единичное нормальное распределение. Такое распределение получается при условии, что среднее арифметическое равно нулю, а стандартное отклонение - единице: Мх = 0, s = 1. Стандартное распределение удобно тем, что к нему может быть сведено любое другое нормальное распределение путем операции стандартизации. Операция стандартизации заключается в следующем: из каждого индивидуального значения параметра вычитается среднее арифметическое значение (это называется центрированием), а полученная разность делится на значение стандартного отклонения (нормирование). Стандартизированное значение принято обозначать символом z:
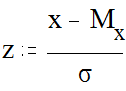
Стандартизация позволяет анализировать любые нормальные распределения на основе знания характеристик единичного нормального распределения, которые приведены в таблице (Таблица1 Приложения). В этой таблице указана кумулятивная (накопленная) вероятность - то есть доля площади под кривой слева от заданной точки от общей площади (общая площадь под кривой принята равной 1.000). Зная параметры распределения величины Мх и s, мы можем оценить вероятность появления наблюдений с тем или иным значением.
Например, количество прочитанных первоклассниками печатных знаков в единицу времени после обучения их по новой методике составляет: среднее значение Мх=142 знака в минуту при стандартном отклонении s =47. Какова вероятность того, что при случайном выборе ученика для контроля нам попадется ученик, читающий 30 знаков или менее?
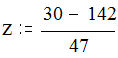
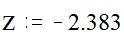
По таблице значений кумулятивной функции распределения стандартного отклонения находим, что кумулятивная вероятность выбора такого ученика равна 0.0082 (то есть 0,8%).
Какова же вероятность выбора ученика, читающего менее 200 знаков?
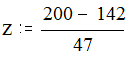
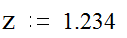
По таблицам находим, что кумулятивная вероятность такого выбора составляет 0.8849, то есть вероятность получения данной величины равна 0.8849 (примерно 88.5%). Соответственно, вероятность выбора ученика, читающего более 200 знаков, будет 1- 0.8849 = 0.1151, то есть чуть более 10%.
Чтобы подсчитать вероятность выбора ученика, читающего от 150 до 200 знаков, надо рассчитать кумулятивную вероятность для 200 (она равна 0.8849) и для 150 (0.5793) и взять разность между этими значениями. Мы получаем величину 0.3056, то есть примерно 30%.
Зная характеристики нормального распределения, установлено, что примерно 2/3 наблюдений, а именно 68.3%, сгруппированы в интервале среднее арифметическое плюс-минус стандартное отклонение Мх ± s; в интервале Мх ± 2s находятся 95.4% наблюдений; а в интервале Мх ± 3s 99.7% всех наблюдений.
Поскольку операция стандартизации нормального распределения сводит любое нормальное распределение к стандартному нормальному, не имеющему размерности, то тем самым появляется возможность сравнивать между собой нормальные распределения величин, измеренных в разных единицах (метры с килограммами, баллы с градусами и так далее).
4. ГЕНЕРАЛЬНАЯ СОВОКУПНОСТЬ И ВЫБОРКА
Любая психодиагностическая методика предназначена для обследования некоторой большой категории индивидуумов. Например, методика исследования интеллекта Векслера подразумевает возможность исследования взрослого населения всей страны. Есть тесты, предназначенные для определения уровня развития школьников, и они предусматривают возможность обследования всех школьников определенного года обучения. Именно это множество потенциально возможных объектов исследования называется генеральной совокупностью. Чтобы определить степень выраженности того или иного свойства у определенного человека, надо знать, как распределено это качество во всей генеральной совокупности. Обследовать всю генеральную совокупность с помощью какой-либо методики практически невозможно, поскольку число испытуемых будет определяться сотнями тысяч и миллионами. Для того чтобы составить представление о распределении значений какого-либо показателя, прибегают к извлечению из генеральной совокупности выборки - некоторой представительной части генеральной совокупности. Именно представительность, ее называют еще репрезентативностью, и является основным требованием к выборке. В выборке, как в капле воды, должны отражаться все свойства генеральной совокупности. Обеспечить абсолютно точное соблюдение данного требования невозможно, можно лишь приблизиться к идеалу с помощью некоторых способов.
Основными способами являются следующие:
· случайная выборка
· моделирование выборки по свойствам генеральной совокупности.
Случайная выборка предполагает, что испытуемые попадут в нее случайным образом, и предпринимаются меры, чтобы исключить появление каких-либо закономерностей при отборе. Для этого используются способы жеребьевки, отбор по таблицам случайных чисел, устанавливается правило отбора - каждый третий из списка, или каждый десятый или другие методы.
При моделировании выборки сначала выбираются те свойства, которые могут повлиять на результаты тестирования (обычно это демографические показатели пола, возраста, и т.д.), внутри которых выделяются градации (интервалы возрастов, уровень образования и т.д.). По этим данным строится матричная модель генеральной совокупности, в каждой из которых записывают количество людей, обладающих этим свойством. Это можно сделать по данным переписи населения, по другим статистическим данным. Выборка извлекается пропорционально по отношению к каждой клетке матрицы. Например, если по данным переписи населения относительный процент мужчин в возрасте от 18 до 30 лет со средним образованием составляет 20%, то и в выборке их должно быть 20%. Более простым случаем является так называемая стратифицированная выборка, когда для модели берется только одно свойство с соответствующими градациями. Например, если соотношение мужчин и женщин в городе составляет 47% и 53%, то и в выборке соблюдается это отношение.
При организации выборки важным является вопрос о достаточном количестве испытуемых. При техническом контроле качества продукции и в ряде других исследований, связанных с порчей или уничтожением исследуемых образцов, используются специальные методики расчета минимально допустимого объема выборки, который позволит получить ответ на поставленный вопрос с заданной степенью точности. При психологических исследованиях вопрос об объеме выборки, может, и не является столь острым, но остается весьма существенным. Малое количество испытуемых не обеспечит точности результата. Большое количество увеличит время и стоимость исследования. Поэтому при подготовке выборки, как правило, руководствуются эмпирическими соображениями. Отечественные исследователи стандартизируют методики на выборках от 200 до 800 человек.
5. СТАНДАРТИЗАЦИЯ ПСИХОДИАГНОСТИЧЕСКИХ МЕТОДОВ
При разработке любой психодиагностической методики подразумевается, что она будет использоваться не разово, а многократно. Чтобы методика, результаты которой выражаются в том или ином числовом виде, могла быть применена впоследствии широким кругом специалистов-психологов, она должна быть стандартизирована. Стандартизацией психодиагностических методов называется процедура получения шкалы, позволяющей сравнивать индивидуальный результат по тесту с результатами большой группы испытуемых. Итогом такой работы являются так называемые тестовые нормы или таблицы пересчета первичных («сырых») данных в стандартные. В качестве точки отсчета, по отношению к которой можно оценивать степень выраженности того или иного психологического свойства, берется средний результат по большой группе испытуемых.
Обычная последовательность стандартизации психодиагностической методики состоит в следующем:
· Определяется генеральная совокупность, для которой предназначена методика, и из нее извлекается выборка.
· По результатам исследования выборки строится эмпирическое распределение, которое проверяется на соответствие его нормальному виду с помощью статистических критериев (например, критерия c2 Пирсона или l Колмогорова-Смирнова, о которых речь пойдет ниже).
· Если распределение нормальное, то строится стандартизированная шкала. Если же у нас распределение отличается от нормального контрастно, то следует либо изменить формулировки вопросов теста, либо более строго определить границы генеральной совокупности и выборки, либо принять другие меры, чтобы приблизить распределение полученных результатов к нормальному.
· Согласно полученной стандартизированной шкале выборка разбивается на группы, про которые известно, какой процент выборки они включают. Впоследствии каждый новый индивидуальный результат можно быстро отнести в одну из групп и точно определять, степень выраженности психологического свойства у испытуемого.
Наиболее распространенной является шкала Z-оценки (или Z-показателя, о котором уже было сказано выше).
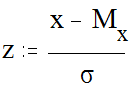
В z-шкале центральным является среднее значение, а от него вправо и влево откладываются значения через интервалы, пропорциональные величине стандартного отклонения (обычно интервалы равны 1s). Количество групп может быть 5 или 7. При 5 группах «средними» считаются результаты Z от -1 до 1 (группа 3, куда попадает 68.26% испытуемых) (Таблица), результаты Z от 1 до 2 называются «выше среднего» (группа 4 - 13.59% испытуемых), при Z выше 2 - «высокими» (группа 5 - 2.28% испытуемых), при Z от -1 до -2 - «ниже среднего» (группа 2 - 13.59% испытуемых), Z ниже -2 - «низкими» (группа 1 - 2.28% испытуемых).
Таблица 3.
| Номер группы | |||||
| Границы группы | от -¥ до Мх-2s | от Мх-2s до Мх-s | от Мх-s до Мх+s | от Мх-s до Мх-2s | от Мх+2s до +¥ |
| Z-показатель | -¥ ¸-2 | -2 ¸ -1 | -1 ¸ +1 | +1 ¸ +2 | +2 ¸ ¥ |
| Процент испытуемых в группе | 2.28 | 13.59 | 68.26 | 13.59 | 2.28 |
| Правая граница в процентилях | 2.28 | 15.87 | 84.13 | 97.72 | 100.00 |
Результатом стандартизации являются таблицы пересчета «сырых» оценок в стандартные, где указываются границы групп в тех единицах, в которых непосредственно проводились тестовые измерения. Например, по некоторой методике оценивается скорость реакции водителя, результат представляется в баллах. В исследованной выборке Мх составляет 80, а стандартное отклонение равно 12. Границы выделенных групп получаются равными 56, 68, 92, 104.
Таблица 4.
| Номер группы | |||||
| Интерпретация результата | Низкий | Ниже среднего | Средний | Выше среднего | Высокий |
| Принцип отнесения в группу (если испытуемый набирает... баллов) | <56 | 56-67 | 68-92 | 93-104 | >104 |
В дальнейшем, при использовании методики, испытуемый набирает, к примеру, 95 баллов, глядя на таблицу, мы сразу же определяем, что это результат группы выше среднего. При необходимости мы можем рассчитать Z-оценку испытуемого Z=(95-80)/10=1.5 и по таблице нормального распределения хуже него группы выполняют тест примерно 93.3% испытуемых, а лучше - лишь 6.7%.
Один из недостатков Z-шкалы - наличие отрицательных и дробных Z-показателей, что неудобно в работе. Для удобства Z-шкалу преобразуют по формуле y = az+b, где у- оценки новой шкалы, а и b - назначаемые новые стандартное отклонение и среднее. Наиболее популярна Т-шкала Мак-Колла, где а = 10, b = 50. Для перехода к Т-шкале надо рассчитать Z-оценки и перевести их в Т-шкалу по формуле T=10z+50. По этой шкале среднее арифметическое равно 50, границы групп 30, 40, 60, 70.
Используется также шкала Векслера, коэффициенты a и b в которой равны соответственно 15 и 100: IQ = 15z + 100. Кроме того, известна шкала Амтхауэра A=10z+100.
Другой недостаток шкалы Z-оценок и производных от нее шкал - то, что получается очень большое количество средних значений, а в крайние группы попадают совсем немногие испытуемые. Чтобы избежать этого недостатка, увеличивают число групп (шкалы стенов, станайнов, квантильные шкалы).
Название шкалы стенов происходит от английского словосочетания «standard ten» - стандартная десятка. По данной шкале выборка делится на 10 групп испытуемых, которым присваиваются баллы от 1 до 10. Среднее арифметическое принимается равным 5.5, стандартное отклонение примерно равно 2. Формула перехода к шкале стенов St=5.5+2z. Ось Х делится на интервалы, равные 0.5s. С учетом приведенных среднего арифметического и s можно рассчитать процент испытуемых, попадающий в каждую группу:
Таблица 5.
| Стен | ||||||||||
| Процент испытуемых в группе | 2.28 | 4.40 | 9.19 | 14.98 | 19.15 | 19.15 | 14.98 | 9.19 | 4.40 | 2.28 |
| Правая граница группы в процентилях | 2.28 | 6.68 | 15.87 | 30.85 | 50.0 | 69.15 | 84.13 | 93.32 | 97.72 |
Шкала станайнов («стандартной девятки) по своей идее близка к шкале стенов. В целом, она строится аналогично шкале стенов, но взято число групп 9, чтобы избежать появления двузначных цифр (это удобно при машинной обработке данных).
Наряду со шкалой z-оценок и производных от нее шкал используются квантильные шкалы. Квантильная шкала получается путем разбиения выборки на равные по количеству испытуемых части. Чаще используется деление на 5 или 10 частей, то есть в выборке определяются квинтили или децили. В этом случае границы групп в долях сигмы можно подобрать по таблицам нормального распределения (Таблица 1 Приложения). При использовании квантильных шкал ось Х делится на части, равные по количеству испытуемых, но непропорциональные величине стандартного отклонения.
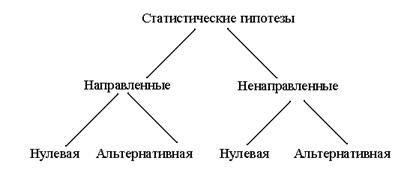
6. СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ
Гипотезой называется предположение, имеющее вероятностный характер, обладающее неопределенностью в отношении своей истинности. Гипотезы формулируются для того, чтобы представить в четком, лаконичном виде представления автора о том или ином факте, о его причинах.
В статистике гипотезы формулируются по поводу характеристик распределений, частот событий, положения событий относительно друг друга в ранжированном порядке и так далее. Подход к гипотезе в статистике четкий и в значительной мере формальный. Принято выделять статистические гипотезы двух основных видов - нулевую и альтернативную. Нулевая гипотеза, обозначаемая Н0, формулируется как гипотеза об отсутствии отличий: о сходстве двух распределений, о равенстве средних арифметических двух выборок и т.п. Нулевой она называется потому, что содержит 0: Х1-Х2=0, где Х1 и Х2 - значения признаков. Нулевая гипотеза утверждает, к примеру, что результаты выполнения задания экспериментальной группой и контрольной не различаются. Альтернативная гипотеза Н1 противоположна по смыслу нулевой, она утверждает наличие отличий в выборках, в параметрах их распределений и так далее (результаты экспериментальной группы значимо отличаются от результатов контрольной группы).
Две гипотезы - нулевая и альтернативная - образуют группу несовместных событий, то есть, если принимается одна из них, то другая отклоняется: принимая гипотезу об отсутствии различий Н0, мы отклоняем альтернативную гипотезу Н1, утверждающую, что различия есть, и, соответственно, наоборот.
Кроме этого, статистическая гипотеза может быть направленной или ненаправленной. Ненаправленная гипотеза фиксирует только наличие или отсутствие различий:
Н1 - ненаправленная альтернативная гипотеза: результаты экспериментальной группы значимо отличаются от контрольной,
Н0 - ненаправленная нулевая гипотеза: результаты экспериментальной группы значимо не отличаются от контрольной.
Направленная гипотеза говорит о наличии или отсутствии различий в определенном направлении:
Н1 - направленная альтернативная гипотеза: результаты экспериментальной группы выше (или, наоборот, ниже) результатов контрольной группы,
Н0 - направленная нулевая гипотеза: результаты экспериментальной группы не превышают результаты контрольной.
Общая схема классификации гипотез представляется в следующем виде:
Проверка гипотез производится с помощью статистических критериев. Статистический критерий - это правило, которое позволяет принимать истинную и отклонять ложную гипотезу с высокой степенью вероятности. Математически критерий представляет собой формулу, по которой мы рассчитываем некоторое число. Есть много разных видов статистических критериев, каждый из них разработан для решения определенного круга задач: так, по одному из них можно доказывать значимость различий средних арифметических значений двух выборок, по другому - согласованность изменения параметров двух распределений и так далее. Как правило, по формуле рассчитывается числовое значение критерия для имеющейся в нашем распоряжении выборки данных (полученное число называется эмпирическим значением критерия), и эмпирическое значение сравнивается с критическими значениями критерия, приведенными в таблицах. Различие между эмпирическим и критическим значениями критерия позволяет нам принять одну из статистических гипотез (нулевую или альтернативную) и отклонить другую.
Все статистические критерии делятся на параметрические и непараметрические. Параметрическими называются критерии, в формулу расчета которых входят параметры распределения (чаще всего это среднее арифметическое и стандартное отклонение). Непараметрические критерии, соответственно, параметры распределение в формулу расчета не включают, они оперируют только частотами или рангами. Каждая группа критериев имеет свои возможности, свои преимущества и недостатки, свои ограничения в использовании, которые будут рассмотрены при описании каждого из критериев. Параметрические методы следует применять при достаточно больших выборках (на практике обычно это означает больше 15 - 20 испытуемых), когда исследуемое распределение относится к нормальному типу. При небольшом количестве испытуемых, а также, если исследуемое распределение значимо отличается от нормального, следует воспользоваться непараметрическими методами. Непараметрические методы в психологии используются весьма широко, поскольку набрать достаточное количество испытуемых представляется возможным далеко не всегда.
В статистике за основной вариант принимается вариант рассмотрения истинности нулевой и ложности альтернативной гипотезы в генеральной совокупности. Применяя определенный критерий для принятия той или иной гипотезы по результатам обследования выборки, исследователь оказывается в следующей ситуации:
Таблица 6.
| Действия исследователя | Состояние нулевой гипотезы | |
| Истинное | Ложное | |
| Принимается Н0 | Принято правильное решение (р=1-a) | Совершена ошибка 2-го рода (р= b) |
| Отклоняется Н0 | Совершена ошибка 1-го рода (р=a) | Принято правильное решение (р= 1-b) |
Такая ситуация складывается, потому что исследование проводится на выборке, а вывод делается об истинности гипотезы в генеральной совокупности. Понятно, что пока не изучена вся генеральная совокупность, дать окончательный ответ нельзя, а до того можно говорить лишь о большей вероятности одной гипотезы и меньшей другой и при этом указывать вероятность ошибки сделанного вывода.
Например, все признаки свидетельствуют о том, что должен пойти дождь. Нулевая гипотеза говорит нам об отсутствии различий между характеристикой сегодняшней погоды и характеристикой дождливого дня (низкое давление, низкая плотная облачность, высокая влажность). Альтернативная гипотеза утверждает, что различия есть, следовательно, дождя не будет.
Таблица 7.
| Действия | В действительности | |
| Н0: дождь будет | Н1: дождя не будет | |
| Брать зонт | Правильное решение (1-a) | Ошибка 2-го рода (b) |
| Не брать зонт | Ошибка 1-го рода (a) | Правильное решение (1-b) |
Как мы видно из таблицы, ошибка первого рода состоит в том, что мы отклонили нулевую гипотезу, которая на самом деле верна. Вероятность ошибки 1-го рода обозначается a, соответственно вероятность правильного решения будет 1-a. Вероятность 1-a называется доверительной вероятностью. В каждом исследовании указывают вероятность ошибки a ( либодоверительную вероятность 1-a) или в виде десятичной дроби (a =0.05), или в процентах (a =5%)
Ошибкой второго рода называется принятие по результатам выборочного исследования нулевой гипотезы, в то время как верна альтернативная. Обозначается вероятность ошибки второго рода b, соответственно, вероятность правильного решения в данном случае 1-b. Эта вероятность 1-b называется мощностью критерия. Мощность критерия характеризует его способность отклонять ложную гипотезу.
Уровень ошибки первого рода исследователь, как правило, задает самостоятельно, либо ее можно рассчитать. Вероятность ошибки второго рода b обычно остается неизвестной, только в некоторых случаях она может быть оценена примерно. Оба вида ошибок тесно связаны между собой: если отклоняется истинная нулевая гипотеза, то принимается ложная альтернативная, или, если принимается ложная нулевая гипотеза, то отклоняется истинная альтернативная. Задавая низкий уровень вероятности ошибки a, мы тем самым резко увеличиваем вероятность ошибки второго рода b, и наоборот, повышая вероятность ошибки a, мы уменьшаемвероятность ошибки b. В каждом конкретном случае следует проанализировать, какая из ошибок несет в себе меньшую опасность, и после этого задать тот или иной уровень доверительной вероятности. При использовании статистических методов в психологии обычно ориентируются на вероятность a = 0.05 (доверительная вероятность 95%, то есть ошибка вероятна лишь в одном случае из 20), считая его пограничным для принятия или отклонения альтернативной гипотезы. Если требуется принять альтернативную гипотезу с большей степенью надежности, то принимается a = 0.01 (доверительная вероятность 99%). А если мы хотим принять нулевую гипотезу с высокой степенью надежности, то нужно задать a = 0.10 или даже 0.20 (доверительная вероятность 90 или 80%), при этом вероятность ошибки второго рода b понизится; в этом случае следует задать низкий уровень доверительной вероятности. Например, для ситуации с зонтом, как правило, более безболезненно пройдет ошибка второго рода b - зонт возьмем, а дождя не случится.
7. МАТЕМАТИЧЕСКИЙ АППАРАТ ПРОВЕРКИ СТАТИСТИЧЕСКИХ ГИПОТЕЗ
Порядок математической обработки данных с использованием статистических критериев включает следующие стадии:
1. Подготовка данных и выбор критерия
На этой стадии требуется:
· Определить частоты встречаемости признаков, проверить выборку на наличие аномальныхили«выскакивающих» значений», свести результаты измерений в таблицы, рассчитать параметры распределения (среднее арифметическое Мх, дисперсия s2, стандартное отклонение s, медиану и межквартильное отклонение).
· проверить, соответствует ли исследуемое распределение нормальному.
· определить, являются ли выборки зависимыми или независимыми. Зависимыми являются выборки с одними и теми же испытуемыми, признаки которых измерены в различных условиях, например до тренинга и после него, в утреннее и вечернее время, или до начала опробования программы обучения, в середине и после. Независимыми будут выборки, в которых одни и те же признаки измерены в разных группах испытуемых, например, в экспериментальной группе и в контрольной.
· выбрать критерий для решения поставленной задачи.
2. Формулирование нулевой и альтернативной гипотез.
3. Расчет эмпирического значения критерия по соответствующим формулам.
4. Определение числа степеней свободы (при использовании параметрического критерия ). Число степеней свободы, обозначаемое греческой буквой «n», отражает число независимых источников информации. Оно равно числу классов вариационного ряда минус число условий, при которых этот ряд был сформирован. Другими словами это разность между числом наблюдений в выборке и числом параметров, которые следует оценить по выборочным данным. Как правило, формулы расчета статистических критериев сопровождаются правилом определения числа степеней свободы, например, «n=n-1» или «n=n-2».
5. Определение критического значения критерия по таблицам критических значений, сравнение с ним эмпирического значения и принятие нулевой или альтернативной гипотезы, либо решения о статистической значимости связи. Таблицы критических значений критериев составлены, как правило, для четырех уровней ошибки a 0.10, 0.05, 0.01 и 0.001, что соответствует доверительным вероятностям 0.90, 0.95, 0.99 и 0.999, либо для двух наиболее употребительных в практике a = 0.05, 0.01 (доверительная вероятность 0.95, 0.99). Кроме того, выбирая критическое значение из таблицы, следует различать, двусторонний и односторонний критерии. Если в ходе исследования проверяется направленная гипотеза, то есть отклонение от Но только в положительную или только в отрицательную сторону, то используется односторонний критерий. Если же проверяется ненаправленная гипотеза, то есть равно возможны отклонения как в ту, так и в другую стороны, значит, используется двусторонний критерий. По результатам сравнения эмпирического значения с критическим принимается либо нулевая, либо альтернативная гипотеза.
6. Формулирование вывода. Вывод должен сопровождатьсяуказанием на принятый уровень доверительной вероятности или ошибки первого рода.
7.1. Подготовка данных
7.1.1 Порядок выявления аномальных значений
Аномальные или «выскакивающие» значения - это единичные значения, сильно отличающиеся от основной массы. Выскакивающие значения могут появиться в случае ошибки при переписывании данных, при введении информации в компьютер, или, к примеру, если кто-то из испытуемых отнесся к исследованию психолога несерьезно и сообщил ложные данные, и еще во многих других случаях. «Выскакивающие» значения из дальнейших расчетов следует исключить.
Порядок проверки статистической гипотезы с помощью различных статистических критериев следующий:
1. Выборка упорядочивается в порядке возрастания вариант (то есть значений случайной величины).
2. Для проверки на аномальность (Ашмарин И.П. и др., 1971) наименьшего значения рассчитывается параметр
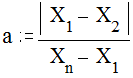
то есть частное от деления разности между наименьшей вариантой выборки и следующей за ней по величине |Х1- X2| на размах выборки (Xn-X1). Полученное эмпирическое значение сравнивается по абсолютной величине с критическим, приведенным в таблице 2 Приложения для требуемого уровня достоверности. Если эмпирическое значение превышает критическое, либо равно ему по абсолютной величине, то наименьшую варианту следует признать аномальной и из дальнейших расчетов ее надо исключить.
3. Аналогично следует проверить на аномальность и наибольшую варианту. В этом случае рассчитывается

то есть частное от деления разности между наибольшей вариантой и предшествующей ей по величине (Хn- Xn-1) на размах выборки (Xn-X1), и полученное эмпирическое значение сравнивается с критическим (табл.). Если эмпирическое значение превышает критическое либо равно ему по абсолютной величине, то наибольшую варианту следует из дальнейших расчетов исключить как аномальную.
Например, имеется выборка, включающая следующие результаты испытуемых (данные упорядочены, то есть выписаны в порядке увеличения значений):
14, 19, 21, 23, 24, 25, 26, 27, 29, 31, 34, 36, 39, 54.
Проверка на наличие выскакивающих значений:
| Минимальное значение: | а = | 14-19 | = | = | 0,125 | |
| 54-14 |
Критическое значение а для 14 испытуемых равно 0.350[1] (р=0.05). Эмпирическое значение а меньше критического, следовательно, значение 14 аномальным не является.
| Максимальное значение: | а = | 54-39 | = | = | 0,375 | |
| 54-14 |
Эмпирическое значение больше критического 0.350 (р=0.05), то есть значение 54 является аномальным и его следует из дальнейших расчетов исключить.
Все приведенные ниже в задачах данные проверены на наличие аномальных значений.
|
|
|
|
|
Дата добавления: 2014-12-27; Просмотров: 3873; Нарушение авторских прав?; Мы поможем в написании вашей работы!