КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Парный регрессионный анализ
|
|
|
|
· Чтобы вызвать регрессионный анализ в SPSS, выберите в меню Analyze... (Анализ) Regression... (Регрессия)
Откроется соответствующее подменю.
Разделы этой главы соответствуют опциям вспомогательного меню. Причём при изучении линейного регрессионного анализа снова будут проведено различие между простым анализом (одна независимая переменная) и множественным анализом (несколько независимых переменных). Собственно говоря, никаких принципиальных отличий между этими видами регрессии нет, однако простая линейная регрессия является простейшей и применяется чаще всех остальных видов.
 Для проведения линейного регрессионного анализа зависимая переменная должна иметь интервальную (или порядковую) шкалу. В то же время, бинарная логистическая регрессия выявляет зависимость дихотомической переменной от некой другой переменной, относящейся к любой шкале.
Для проведения линейного регрессионного анализа зависимая переменная должна иметь интервальную (или порядковую) шкалу. В то же время, бинарная логистическая регрессия выявляет зависимость дихотомической переменной от некой другой переменной, относящейся к любой шкале.
Те же условия применения справедливы и для пробит-анализа. Если зависимая переменная является категориальной, но имеет более двух категорий, то здесь подходящим методом будет мультиномиальная логистическая регрессия. Новшеством уже в 10 версии SPSS является порядковая регрессия, которую можно использовать, когда зависимые переменные относятся к порядковой шкале. И, наконец, можно анализировать и нелинейные связи между переменными, которые относятся к интервальной шкале. Для этого предназначен метод нелинейной регрессии.
Принципиальная идея регрессионного анализа состоит в том, что, имея общую тенденцию для переменных – в виде линии регрессии – можно предсказать значение зависимой переменной, имея значения независимой.
Этот вид регрессии лучше всего подходит для того, чтобы продемонстрировать основополагающие принципы регрессионного анализа. Рассмотрим для этого диаграмму рассеяния, которая иллюстрирует зависимость показателя удовлетворенности жильем от общей площади жилья. Можно легко заметить очевидную связь: обе переменные развиваются в одном направлении и множество точек, соответствующих наблюдаемым значениям показателей, явно концентрируется (за некоторыми исключениями) вблизи прямой (прямой регрессии). В таком случае говорят о линейной связи.
у=b*х + а
где b — регрессионные коэффициенты, a — константа, задающая смещение по оси ординат.
Смещение по оси ординат соответствует точке на оси у (вертикальной оси), где прямая регрессии пересекает эту ось. Коэффициент регрессии b через соотношение
b = tg(a) указывает на угол наклона прямой.
При проведении простой линейной регрессии основной задачей является определение параметров b и а. Оптимальным решением этой задачи является такая прямая, для которой сумма квадратов вертикальных расстояний до отдельных точек данных является минимальной.
Если мы рассмотрим показатель «удовлетворенность жильем» (var1) как зависимую переменную (у), а исходную величину «общая площадь жилья» var2 как независимую переменную (х), то тогда для проведения регрессионного анализа нужно будет определить параметры соотношения
var1 = b*var2 + a
После определения этих параметров, зная исходный показатель общей площади жилья, можно спрогнозировать показатели удовлетворенности жильем.
В нашем примере, простой регрессионный анализ позволяет получить следующие таблицы.

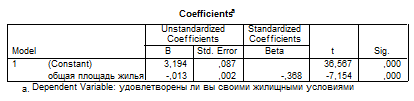
Уравнение регрессии будет выглядеть таким образом: Var1 = -0,013*var2 + 3,194
Можно вычислить какова будет удовлетворенность жилищными условиями, если общая площадь жилья составит 70 кв.м. -0,013*70+3,194 = 2,28, таким образом, удовлетворенность будет иметь значение 2 – «отчасти».
Одним из главных показателей регрессионного анализа является множественный коэффициент корреляции R – коэффициент корреляции между исходными и предсказанными значениями зависимой переменной. В парном регрессионном анализе он равен обычному коэффициенту корреляции Пирсона между зависимой и независимой переменной, в нашем случае – 0,368. Чтобы содержательно интерпретировать множественный R, его необходимо преобразовать в коэффициент детерминации. Это делается так же, как и в корреляционном анализе – возведением в квадрат. Коэффициент детерминации R-квадрат (R2) показывает долю вариации зависимой переменной, объяснимую независимой (независимыми) переменными.
В нашем случае, R2 = 0,136. Чем больше величина коэффициента детерминации, тем выше качество модели.
Другим показателем качества модели является стандартная ошибка оценки (Std.Error of Estimate). Это показатель того насколько точки «разбросаны» вокруг линии регрессии. Мерой разброса для интервальных переменных является стандартное отклонение. Чем выше его значение, тем сильнее разброс, тем хуже модель. В нашем случае, стандартная ошибка составляет 0,669. Именно на эту величину наша модель будет «ошибаться в среднем» при прогнозировании значения переменной «удовлетворенность жильем».
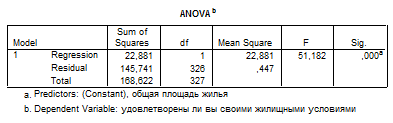
Регрессионная статистика включает в себя также дисперсионной анализ (ANOVA). С его помощью выясняем: 1) какая доля вариации (дисперсии) зависимой переменной объясняется независимой переменной; 2) какая доля дисперсии зависимой переменной приходится на остатки (необъясненная часть), 3) каково отношение этих двух величин (F-отношение). Дисперсионная статистика очень важна. Для выборочных исследований она показывает, насколько вероятно наличие связи между независимой и зависимой переменными в генеральной совокупности, для сплошных исследований - проверяют «не случайность» выявленной статистической закономерности.
В нашем случае F-отношение 51,182 значимо на уровне 0,000. Соответственно, мы можем с уверенностью отвергнуть нулевую гипотезу (что обнаруженная связь носит случайный характер).
|
|
|
|
|
Дата добавления: 2014-12-27; Просмотров: 565; Нарушение авторских прав?; Мы поможем в написании вашей работы!