КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Пример 8.2
|
|
|
|
Обратимся к Примеру 6.4. Предположим, что каждая из выборок  и
и 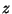 взята из нормального распределения с неизвестными параметрами --
взята из нормального распределения с неизвестными параметрами -- 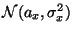 и
и 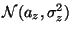 соответственно. (О том, на основании чего можно сделать такое допущение, мы поговорим позже в
соответственно. (О том, на основании чего можно сделать такое допущение, мы поговорим позже в  9.5.)
9.5.)
Наша цель -- найти доверительные интервалы для 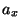 и
и 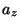 , теоретических значений содержания углерода и прочности на разрыв стали GS50. Напомним, что объем каждой из выборок
, теоретических значений содержания углерода и прочности на разрыв стали GS50. Напомним, что объем каждой из выборок 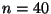 . Зафиксируем доверительную вероятность, близкую к единице, скажем
. Зафиксируем доверительную вероятность, близкую к единице, скажем 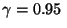 . По таблице распределения Стьюдента на стр.
. По таблице распределения Стьюдента на стр.  определим приближенно, что
определим приближенно, что 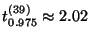 . Вспоминая значения
. Вспоминая значения 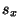 и
и  , найденные в Примере 6.5 на стр. , вычисляем
, найденные в Примере 6.5 на стр. , вычисляем

| 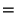
| 
| |
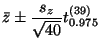
|
| 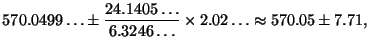
|
и, пользуясь формулой (49), получаем 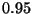 -доверительный интервал для процентного содержания углерода
-доверительный интервал для процентного содержания углерода
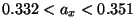
и -доверительный интервал для значения прочности на разрыв
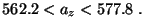
Лабораторная работа №12.
Основы теории оценивания
Статистик имеет дело с данными, подверженными случайной изменчивости. Их поведение характеризуется некоторым законом распределения вероятностей. Такой закон, как правило, содержит неизвестные величины, которые принято считать параметрами закона. В силу случайной изменчивости наблюдаемых данных, нельзя, основываясь на них, указать совершенно точное значение параметров. Приходится довольствоваться лишь приближенными значениями. Итак, математический статистик работает с такими величинами:
- случайной величиной, которую он никогда не наблюдает, но которую считает "душой" изучаемых им данных, причиной, их породившей. Эта величина определяется некоторыми параметрами; - изучаемыми данными, которые получены, как реализация случайной величины.
Например, случайной величиной является точное время. Её реализациями - показания часов, доступных для статистика. Задача статистика - по показаниям n часов t1,...,tn максимально точно установить время. Кроме того он обязан охарактеризовать точность установленного значения. Он выполняет оценивание искомой величины в виде t = t0 + ξ(a,σ), где t0 - истинное время в момент исследования, ξ(a,σ) - случайная величина, характеризующая отклонение от истинного значения, t0, a, σ - параметры, величина ξ характеризуется законом распределения, вероятностями того, что она принимает различные значения.
Оцениванием в статистике называют правило вычисления приближенного значения параметра на основе наблюдаемых данных.
Оценка - это приближенное значение параметра, найденное по наблюдаемым данным. При построении оценок для практического применения, к оценкам предъявляются три основных требования:
· точность, то есть близость к истинному значению параметра, в примере ξ(a,σ) должно быть мало;
· несмещенность, то есть требование, чтобы математическое ожидание оценки было равно истинному значению параметра, в примере ξ(a,σ) должно быть в среднем равно нулю;
· состоятельность, то есть требование, чтобы при увеличении числа наблюдений оценка сходилась по вероятности к истинному значению параметра. В примере при большом числе часов n значение ξ(a,σ) должно стремиться к нулю с вероятностью, стремящейся к единице.
Наилучших во всех отношениях оценок не бывает. Например, среднее арифметическое, широко распространенная оценка среднего значения случайной величины, обладает свойством оптимальности для нормально распределенных данных. Однако оно приводит к ошибкам, если среди данных есть выбросы, то есть резко выделяющиеся значения. Такие выбросы в экономике порождены грубыми ошибками в измерениях или опечатками, при которых может исчезнуть точка между рублями и копейками и зарплата возрастёт в сотню раз.
Рассмотрим случайный процесс, связанный с историей нанесения на карту Великой Британии уточнённых границ её владений, разбросанных по всем частям света. Известно, что любая точка на Земле характеризуется двумя координатами - широтой и долготой. Сегодня любой школьник слышал о спутниковых приборах, задающих любую точку на Земле с точностью до метра. Однако в те времена даже подобный прибор не помог бы морякам, так как он не обнаружил бы на небе ни одного "опорного" спутника. Широта определялась непосредственно по высоте светил над горизонтом с помощью прибора "секстан", аналогичного современному теодолиту (подзорная труба плюс измеритель угла). Долгота представляет собой угол поворота земного шара, при котором совмещаются местный меридиан и выбранный за условный нуль гринвичский. Земля делает оборот в 360° почти за сутки, то есть за час она поворачивается на 15°, за 4 минуты - на 1°. Для определения долготы надо точно знать местное и гринвичское время. Если штурман говорит капитану: "Местный полдень, Сэр", а капитан знает время в этот момент в Гринвиче, то разность времени, делённая на 4 минуты, и определяет долготу местности в градусах. Сегодня всё было бы просто - позвонить в Гринвич и узнать их время. Но тогда радио ещё не было придумано. Если бы на корабле были кварцевые часы, которые уходят на долю минуты за год, проблемы тоже бы не было, но существовавшие тогда лучшие хронометры не обеспечивали необходимой для измерения долготы точности. Они за несколько месяцев плавания уходили от точного времени на десятки минут. И когда в 1831 году в кругосветное плавание для составления карт отправлялся корабль "Бигль", капитан корабля Фиц Рой, человек просвещенный и ученый, взял с собой 24(!) морских хронометра. Каждый хронометр показывал своё "гринвичское время". В данном исследовании случайная величина - момент, когда штурман определял точное местное время по какому-нибудь небесному светилу. "Душа" измеряемой случайной величины - истинное время в Гринвиче в этот момент. Такую величину обозначим ξ. Значение этой величины никогда не известно. Наблюдаемые значения случайной величины, это показания (разные) хронометров. Каждый из них несколько ошибался, но в целом они следовали за общей "душой", накладывая на неё свою случайную погрешность. Оценка случайной величины - это то гринвичское время, которое предполагал по наблюдаемым данным капитан.
Пусть случайные величины xi, i = 1,...,n, являются реализациями одной случайной величины ξ, то есть имеют одинаковое распределение (одну "душу"), причём для любого i среднее значение показаний равно одному и тому же числу: Е(xi) = Е(ξ). Смысл этого утверждения таков: все часы не могут дружно отставать или спешить из-за конструктивных неполадок. В среднем, равновероятно, что они спешат или отстают. Кроме того, пусть они независимы. Другими словами, у них нет чего-то общего в группах. Так, матрос, записывающий показания часов, мог их регистрировать в одной последовательности. Тогда последние показания регистрировались бы на минуту позже первых. Или несколько часов могли висеть в тёплом месте и от нагрева дружно спешить. Предположение, что такого явления нет, соответствует условию независимости показаний в разных испытаниях.
Самая простая задача оценивания - это определение вероятности некоторого события, например, того, что реальная (не обязательно правильная) монета выпадет гербом вверх. Определить вероятность события почти никогда нельзя непосредственно. Универсального метода, который позволял бы для произвольного события указать его вероятность, не существует. Можно оценить вероятность события А, если допустимо проводить независимые повторные испытания в ходе которых это событие наступает с постоянной вероятностью. Пусть в каждом из п испытаний вероятность р = Р(А) события А остается неизменной и результат каждого испытания независим от остальных. Обозначим через m случайное число тех испытаний из общего числа n, в которых произошло событие А. Говорят, что m - число "успехов" в n испытаниях Бернулли. Согласно статистическому определению вероятности, при большом n относительная частота m/n события А приближенно равна вероятности события наступления события А, то есть m/n ~ р, где р = Р(А). Докажем, что это следует из аксиоматики Колмогорова.
В математическом анализе используется строгое понятие предела последовательности: при достаточно большом номере члена последовательности, его значение может быть сделано сколь угодно близким к предельному значению. Такое определение не соответствует реальной жизни, где крайне редко происходят совершенно невероятные события. Например, из первичного хаотического бульона возникает бактерия, способная воспроизводить себя. Или рыба создаёт нечто, которое сначала миллионы лет ей не надо (но развивается), а затем становится крылом. Или затапливается целый город (или страна). В теории вероятностей понятие предела толкуется в смысле, отличном от того, который вкладывается в него в математическом анализе. Определение теории вероятностей ближе к жизни. Оно не запрещает того, что в какой-то момент в последовательности будет число, резко отличающееся от других.
Последовательность случайных величин un сходится по вероятности к р, если для любого числа ε > 0 вероятность того, что модуль разности |un - р| при n → ∞ меньше, чем ε, стремится к единице:

В теории вероятностей никакое событие не является достоверным, но событие: |un - р| ≤ ε практически достоверно при достаточно больших n.
Докажем неравенство Чебышева. Пусть ξ - случайная величина, имеющая математическое ожидание Е(ξ) = а и дисперсию D(ξ) = σ², ε - положительное число. Тогда вероятность события, состоящего в том, что центрированная (Е(ξ) - а) и нормированная случайная величина превышает ε менее, чем ε-2:
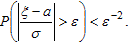
Действительно, σ² = Е(ξ - а)². При вычислении среднего в правой части, выделим две области значений ξ. Для тех ξ, у которых |ξ - а| < εσ, сумма (или интеграл) соответствующих произведений неотрицателен.
Для тех ξ, у которых |ξ - а| > εσ, сумма (или интеграл):
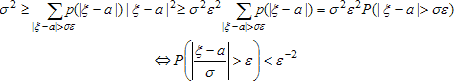
Любопытный частный случай: σ = 0. При этом ясно, что |ξ - а| = 0, то есть ξ = а. Докажем теорему Чебышева. Пусть х1,...,хn - независимые одинаково распределенные случайные величины, имеющие математическое ожидание и дисперсию. То есть каждый xi суть реализация случайной величины ξ, причём Е(ξ) = Е(xi) = а, D(ξ) = D(xi) = σ². Тогда для любого ε > 0:
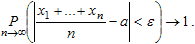
Доказательство. Дисперсия среднего арифметического:

Рассмотрим случайную величину ηn, представляющую собой среднее арифметическое n наблюдений. Её среднее и дисперсия 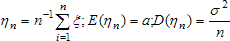 . Наблюдаемыми реализациями ηn являются
. Наблюдаемыми реализациями ηn являются 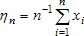 . В соответствии с неравенством Чебышева для случайной величины ηn, вероятность её отклонения от среднего значения на величину, большую чем стремится к нулю:
. В соответствии с неравенством Чебышева для случайной величины ηn, вероятность её отклонения от среднего значения на величину, большую чем стремится к нулю:
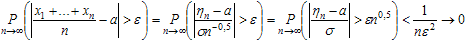
Вероятность противоположного события стремится при больших n к 1: P(|ηn - a|) → 1. Значит, последовательность случайных величин n сходится по вероятности к a.
Вернемся к измерению времени на "Бигле". Показание каждого хронометра xi, i = 1,...,n - это измерение, независимое от других приборов. Подразумевается, что конструкция хронометра такова, что его работе отсутствует систематическая ошибка. Это значит, что одни экземпляры хронометров могут "уходить вперёд", другие "отставать", но эти ошибки случайные, связанные с изготовлением данного образца. Математически это означает, что среднее время - истинное. Качество конструкции и технологии изготовления хронометров характеризуется тем, насколько однородна по точности хода вся продукция в целом. Математически это выражается разбросом показаний отдельных приборов, т.е. дисперсией случайных величин xi. Дисперсия среднего в n = 24 раз меньше, чем дисперсия отдельного хронометра. Поэтому "среднее время", определённое по 24 хронометрам в среднем ближе к истинному времени почти в 5 раз, чем время любого отдельного хронометра.
Лабораторная работа №13.
Изучение методов оценки параметров распределений
В математической статистике различают две разновидности методов. Первую составляют методы оценивания параметров по конечной группе с фиксированным числом наблюдений, вторую - по неограниченно растущей группе, когда исследователь имеет возможность увеличивать число наблюдений. С теоретической точки зрения второй подход проще, так как при больших n исчезают многие проблемы, относящиеся к конечным группам. Основой для выводов в этом случае служит закон больших чисел - при больших n значения характеристик распределения группы приближаются к неизвестным теоретическим значениям этих характеристик. Теорема Чебышева дает способ оценки по группе данных теоретического значения математического ожидания: этой оценкой является среднее арифметическое значение наблюдений.
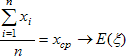
Ищем несмещённую оценку по группе данных для дисперсии распределения случайной величины. Пусть х1,...,хn - совокупность независимых реализаций случайной величины ξ, среднее значение которой равно а. Согласно закону больших чисел, для получения приближенного значения дисперсии Dξ = Е(ξ - Е(ξ))² надо в определении дисперсии заменить теоретическую функцию распределения F на ее аналог Fn. Иначе говоря, требуется заменить операцию нахождения математического ожидания Е усреднением по группе. Сначала сделаем это по отношению к Е, стоящему внутри скобок. Вместо (ξ - Е(ξ))² получим совокупность (х1 - хcp)², (х2 - хcp)²,..., (хn - хcp)². Ищем приближенное выражение для дисперсии:
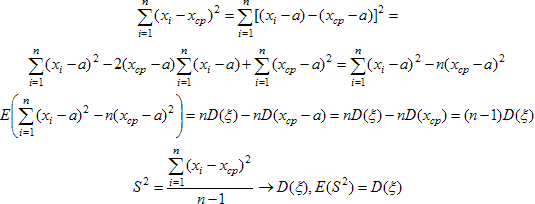
Поскольку среднее значение статистики S² равно дисперсии случайной величины, породившей группу наблюдений, то наблюдаемая величина S² является несмещенной оценкой для истинной дисперсии D(ξ).
Пусть есть группа наблюдений случайной величины ξ с распределением, принадлежащим некоторому параметрическому семейству F(а). Необходимо по этим наблюдениям оценить неизвестный параметр а этого распределения. Для этого выберем какую-либо характеристику Т распределения случайной величины ξ, то есть среднее, медиану, квантиль, …, выражаемую через функцию распределения. Функция распределения F зависит от а. Значение характеристики Т также суть функция от неизвестного значения а. Наблюдаемый по группе аналог этой характеристики Тn на основании закона больших чисел будет близок к ее теоретическому значению, если объем наблюдений достаточно велик. Поэтому решение уравнения:
Т(а) = Тn
позволяет найти оценку одномерного параметра. Если параметров несколько, то выбираем несколько характеристик распределения и составляем систему из соответствующего количества уравнений. В качестве характеристик распределения обычно используют моменты или квантили. Соответственно, способы поиска оценок характеристик случайной величины называются "метод моментов" и "метод квантилей".
Применим метод моментов для поиска параметров нормального закона. Пусть х1,...,хn - совокупность независимых реализаций случайной величины ξ, распределенной по нормальному закону N(a, σ²). Его плотность распределения  . В качестве характеристик распределения будем использовать первый и второй моменты. Теоретические значения этих характеристик равны:
. В качестве характеристик распределения будем использовать первый и второй моменты. Теоретические значения этих характеристик равны:
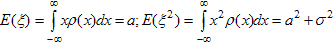
Приравнивая выборочные моменты к их теоретическим аналогам, получим: а = хср; 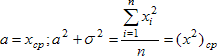 . Получена оценка методом моментов, причём оценка среднего вновь среднее арифметическое, а оценка дисперсии отлична от найденной ранее несмещённой оценки.
. Получена оценка методом моментов, причём оценка среднего вновь среднее арифметическое, а оценка дисперсии отлична от найденной ранее несмещённой оценки.
Биномиальное распределение задаётся единственным параметром р. Первый момент np = Σхi = m, число успехов, оценка для р: р = m/n.
Распределение Пуассона задаётся единственным параметром λ. Первый момент nλ = Σхi, оценка для λ: λ = хср.
Применим метод квантилей для поиска параметров нормального закона. Для нормального распределения и вообще для любого распределения, в котором параметрами служат сдвиг и масштаб, обычно используют медиану и квартили - верхнюю и нижнюю. Случайную величину ξ, распределенную по закону N(а0, σ²), можно представить в виде ξ = а0 + ησ, где η подчиняется распределению N(0,1) с плотностью  . Для N(0,1) медиана равна 0, а нижняя и верхняя квартили равны ±Ф-1(0,75) = ± 0,674. Здесь и далее под числом z = Ф-1(b) подразумевается решение уравнения b = Ф(z), то есть:
. Для N(0,1) медиана равна 0, а нижняя и верхняя квартили равны ±Ф-1(0,75) = ± 0,674. Здесь и далее под числом z = Ф-1(b) подразумевается решение уравнения b = Ф(z), то есть:
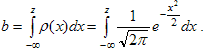
Поэтому в общем случае для нормального закона N(а0, σ²) медиана равна а0, квартили равны: а0 ± Ф-1(0,75).
В качестве оценки параметра распределения а можно использовать как медиану, так и половину суммы верхней и нижней квартилей распределения. Обозначим через med(хi) медиану имеющейся совокупности данных, через Q(0,25) и Q(0,75) ее нижнюю и верхнюю квартили. Приравняв к теоретическим характеристикам их выборочные аналоги, получим следующие оценки:
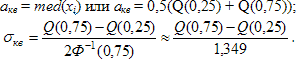
Поскольку для одних и тех же параметров распределения возможны и употребительны разные оценки, целесообразно выбирать из них те, которые лучше или которые обладают желательными свойствами. Состоятельность - практически обязательное свойство всех используемых на практике оценок, несмещенность лишь желательное. Многие часто применяемые оценки свойством несмещенности не обладают. Единого способа сравнения оценок не существует, приходится использовать различные подходы. Чаще всего в качестве критерия качества оценки a0 параметра a выбирают малость величины среднего квадрата отклонения оценки от действительного значения Е(a0 - а)², а наилучшей оценкой считают такую оценку, для которой эта величина минимальна. Более общий подход состоит в том, что выбирают неотрицательную функцию "штрафа" за отклонение a0 от а (иногда говорят, функцию потерь), и наилучшей оценкой считают такую, для которой математическое ожидание величины штрафа минимально. Оценки, для которых минимальна некоторая функция потерь, часто называют оптимальными или эффективными. Но такие оценки не лучше других, так как оптимальные свойства оценок получены при определенных предположениях, которые на практике могут и не выполняться или выполняться лишь приближенно. При этом свойства подобных оценок могут оказаться не столь хорошими. Например, среднее арифметическое элементов выборки является "эффективной" оценкой математического ожидания. Для выборки из нормального распределения эта оценка несмещенная и обладает минимальной дисперсией. Но при отклонении распределения от нормального (например, при наличии "выбросов"), свойства этой оценки становятся неудовлетворительными.
Во многих случаях представляет интерес не получение точечной оценки a0 неизвестного параметра a, то есть одного числа, а указание области, интервала на числовой прямой, в которой этот параметр находится с вероятностью, не меньшей заданной (типично от 95% до 99%). Построить такую область можно следующим образом. Выберем число, близкое к единице: 0 < α < 1 - близкая к единице вероятность, с которой параметр a должен попасть в построенную область.
Можно выбрать число ε, близкое к нулю 0 < ε < 1, как вероятность того, что параметр не попал в эту область. Ясно, что α + ε = 1.
Пусть имеем точечную оценку a0 неизвестного параметра a и можем указать область А(a,), в которую оценка a0 попадает с вероятностью не меньше α: P{a0  А(a, α)} ≥ α для любого a. Тогда доверительной областью (в одномерном случае - доверительным интервалом) с уровнем доверия α для неизвестного нам истинного значения a, построенной по наблюденному в опыте значению оценки a0, является множество {a|a0 А(a, α)}. Процесс доверительного оценивания является как бы обращением процесса проверки статистических гипотез: там по известному значению параметра a строили множество А(a), в которое с заданной вероятностью попадает некоторая статистика a0, а здесь по таким множествам строим область, которая накрывает с заданной вероятностью само значение a.
А(a, α)} ≥ α для любого a. Тогда доверительной областью (в одномерном случае - доверительным интервалом) с уровнем доверия α для неизвестного нам истинного значения a, построенной по наблюденному в опыте значению оценки a0, является множество {a|a0 А(a, α)}. Процесс доверительного оценивания является как бы обращением процесса проверки статистических гипотез: там по известному значению параметра a строили множество А(a), в которое с заданной вероятностью попадает некоторая статистика a0, а здесь по таким множествам строим область, которая накрывает с заданной вероятностью само значение a.
Считается, что метод наибольшего правдоподобия позволяет оптимально использовать имеющейся в данных информацию о параметрах распределения случайной величины, породившей данные. Пусть х1,...,хn - данные, которые считаем реализациями случайной величины с распределением, плотность которого в точке х зависит от неизвестного параметра a. Обозначим плотность отдельного наблюдения хi (i = 1,...,n) через р(x, a). Поскольку случайные величины хi независимы, плотность вероятностей вектора (х1,...,хn) равна произведению плотностей с неизвестным истинным значением параметра. Подставим вместо переменных элементы наблюдений, то есть реализации случайных величин х1,...,хn, а параметр а будем рассматривать как переменную величину, изменяющуюся в заданной области значений. В таком случае найденная плотность превращается в величину, которую называют правдоподобием (likelihood):
р(х1, a) · р(х2, a) ·... · р(хn, a).
Метод наибольшего правдоподобия рекомендует выбирать в качестве оценки al неизвестного истинного значения параметра а такое значение, при котором правдоподобие достигает максимума. Такой выбор происходит в зависимости от значений х1,...,хn, поэтому al является случайной величиной.
Суть метода легче понять, анализируя следующую задачу. Требуется оценить число N рыб в пруду. Для этого из пруда выловили (случайным образом извлекли) M рыб, помечены и отпущены обратно в пруд. Через некоторое время, извлекли вторую группу n рыб и установили, что в этой группе m отмеченных. Считая, что пойманные в первый раз рыбы ко второму разу равномерно перемешались с непойманными, найти оценку максимального правдоподобия числа рыб в пруду, то есть наиболее вероятное при наблюдённых данных количество рыб в этом пруду.
Решение: Количество способов извлечь случайным образом группу n рыб из N рыб, обитающих в пруду равно СNn. Количество способов извлечь ровно m рыб из М отмеченных равно СMm. Количество способов извлечь ровно n - m рыб из N - M неотмеченных равно СN-Мn-m. Два последних события независимы, поэтому число способов извлечь случайным образом именно ту группу, которая была извлечена, равно произведению найденных количеств, а вероятность извлечь её равна: 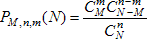 . Для поиска максимума этой величины, найдём отношение
. Для поиска максимума этой величины, найдём отношение 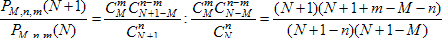 .
.
Это выражение равно единице при N = Mn/m - 1. При меньших N оно больше единицы, то есть вероятность растёт по мере роста N. При больших N оно меньше единицы, то есть убывает с ростом N. Значит, при целом искомая вероятность максимальная. Это и есть оценка методом правдоподобия для искомой величины N.
Выполним оценку методом правдоподобия параметров нормальной модели N(a,b). Для неё функция правдоподобия равна:
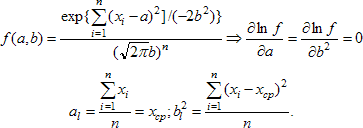
Оценки, полученные методом наибольшего правдоподобия и методом моментов, для нормального распределения совпали, но оценка дисперсии вновь отлична от найденной ранее несмещённой оценки дисперсии.
Во многих случаях представляет интерес не получение точечной оценки a0 неизвестного параметра a, одного числа, а указание интервала на числовой прямой, в которой этот параметр находится с вероятностью, не меньшей заданной (типично от 95% до 99%). Построить его можно следую-щим образом. Выберем вероятность α, близкую к единице, с которой параметр a должен попасть в построенную область (или ε, близкое к нулю 0 < ε < 1, как вероятность того, что параметр не попал в эту область, α + ε = 1). Пусть имеем точечную оценку a0 параметра a и можем указать область А(a, α), в которую оценка a0 попадает с вероятностью не меньше α: P{a0 А(a, α)} ≥ α для любого a. Тогда доверительным интервалом с уровнем доверия α для неизвестного нам истинного значения a, построенной по наблюденному в опыте значению оценки a0, является множество {a|a0 А(a, α)}. Процесс доверительного оценивания является обращением процесса проверки статистических гипотез: там по известному значению параметра a строили множество А(a), в которое с заданной вероятностью попадает некоторая статистика a0, а здесь по таким множествам строим область, которая накрывает с заданной вероятностью само значение a.
В лабораторной работе решаются две не связанных между собой задачи:
· найти распределение реальных данных (страховых выплат некоторой фирмы)
· найти распределение модельной группы данных - смеси двух нормальных распределений.
Задача 1
Априорно известно, что обычно реальные выплаты страховой компании клиентам описываются такими распределениями, как Парето, Вейбулла или логнормальное. Предположим, что наблюдаемые страховые выплаты описываются распределением Парето:
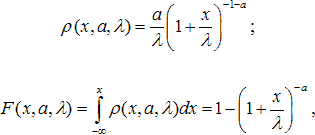
где все параметры и переменная положительны. Моменты этого распределения:
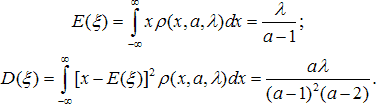
Первый момент определён при a > 1, второй - при a > 2. Несмещённые оценки среднего и дисперсии по наблюдаемым данным:
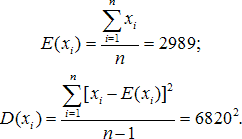
Формально приравнивая моменты, получаем систему двух уравнений метода моментов, имеющую единственное решение a = 2,475; λ = 4410. Полученное значение удовлетворяет требованию a > 2, однако оно может быть и формальным решением, не соответствующим сути явления, если истинное a < 2.
Строим функцию правдоподобия:
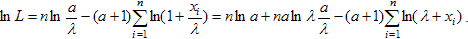
Находим частные производные по a и по λ. Приравнивая производные нулю, получаем:
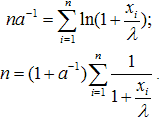
Система решалась с помощью Windows-приложения Maple - 9. Получены значения a = 1,909; λ = 2704. Видно, сколь значительно отличие результатов двух методов. Ясно и объяснение этого факта - найденное значение a меньше двух, то есть метод моментов является принципиально не применимым.
Для проверки по критерию согласия Колмогорова-Смирнова преобразуем ряд данных в вариационный ряд и вычисляем статистику
Dn = max|F(xi) - k/n| и |F(xi) - (k - 1)/n|.
При соответствующем параметре 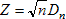 и при справедливости нулевой гипотезы вероятность, что параметр Z равен наблюдаемому значению или превышает его, равна:
и при справедливости нулевой гипотезы вероятность, что параметр Z равен наблюдаемому значению или превышает его, равна:
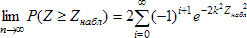
В случае, если a = 2,475 и λ = 4410 вероятность по Колмогорову 0,62, а для a = 1,909; λ = 2704 вероятность 0,92, то есть второе заметно вероятнее. График функции распределения экспериментальных данных и теоретического распределения Парето дан на рисунке 1. Видно хорошее сходство. Попытки улучшить сходство за счет подбора параметров при прямой проверке критерия Колмогорова-Смирнова не привела к успеху. В ходе этой попытки варьировались значения параметров распределения и вычислялось значение Z(a; λ). Установлено, что минимум этого выражения отличается от найденного значения не более, чем на 1%, то есть для использованных данных оценка прямой минимизацией функционала Z(a;) не значительно отлична от оценки наибольшего правдоподобия.
Имеются данные, про которые предполагается, что они принадлежат смеси двух нормальных распределений. Необходимо найти параметры этих распределений и соотношение между ними. Расщепление провести методом моментов. Случайная величина, представляющей собой смесь двух нормальных распределений, задается пятью параметрами:
· р - доля первого распределения, р + q = 1;
· а1, D1 - математическое ожидание и дисперсия первого распределения;
· а2, D2 - математическое ожидание и дисперсия первого распределения.
Выразим через эти пять параметров теоретические характеристики смешанного распределения:
Ех = pа1 + qа2
D = pD1 + q D2 + pq(a1 - а2)²;
M30 = 3pq(a1 - а2)(D2 - D1) - pq(p - q)(a1 - а2)³;
M40 = 3pD1² + 3qD2² + pq(a1 - а2)²[(1 - 3pq)(a1 - а2)² + 6pD2 + 6qD1];
Задача свелась к решению системы четырёх уравнений с пятью неизвестными. Для замыкания использовали теоретическое соотношение для верхней квартили. Последнее уравнение решалось графически.
В работе были генерированы две последовательности. Первая из 50 чисел с распределением N(3,1), вторая из 150 чисел с распределением N(6,1). При этом р = 0,25.
Расчёт велся пошагово и последнее значение найдено по графику зависимости значения верхней квартили от р. Найдено:
a2 - a1 = a21:= 3.100156536
d2:= 1.084833215
d1:= 0.8685383266
a1:= 2.850792779
a2:= 5.950949315
Полученные результаты близки к заложенным. Теоретическая функция распределения и эмпирическая функция реальных данных построены на графике. Они явно близки. Проверка по критерию Колмогорова (асимптотическое соотношение для статистики Dn) даёт формальную вероятность совпадения зависимостей 97%, то есть совпадение следует считать хорошим.
|
|
|
|
|
Дата добавления: 2014-12-23; Просмотров: 567; Нарушение авторских прав?; Мы поможем в написании вашей работы!