КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Анализ парной корреляционной зависимости. Построение и анализ корреляционных таблиц
|
|
|
|
Построение и анализ корреляционных таблиц
Решение задач парной зависимости.
Анализа с помощью ППП STATISTICA
Решение задач корреляционно-регрессионного
Построение корреляционных таблиц, как отмечалось выше, один из методов выявления наличия корреляционной зависимости. Поскольку выполнение лабораторной работы предусматривает ее построение, рассмотрим пример построения корреляционной таблицы с использованием некоторых вспомогательных модулей ППП STATISTICA.
Корреляционная таблица – это результат группировки единиц изучаемой совокупности по двум признакам: в подлежащем таблицы выделяются группы по факторному признаку х, в сказуемом – по результативному у или наоборот. В клетках таблицы на пересечении x и у подсчитывается число случаев совпадения каждого значения х с соответствующим значением у (частоты). Общий вид такой таблицы показан на условном распределении 40 единиц (Таблица 7.1). Здесь в качестве х может рассматриваться, например, стаж работы (число лет), а в качестве у – производительность труда, n = 40 – число рабочих.
Таблица 7.1
Пример корреляционной таблицы
| Значение признака xj | Значение признака yi | Итого (число единиц) fx = fj | Среднее
значение по группам 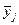
| |||
| - | - | 8,75 | ||||
| - | 12,08 | |||||
| - | 15,31 | |||||
| - | - | 16,87 | ||||
| Итого (число единиц) fy = fi | ∑f = 40 | 14,0 |
В первой строке значению факторного признака х =1 один раз соответствует значение у = 5 и три раза у = 10. Аналогично во второй строке, где х = 3, два раза этому значению соответствует у = 5, три раза у = 10 и семь раз у =15 и т.д.
В итоговой строке имеем распределение всех 40 единиц совокупности по результативному признаку у (частоты обозначены fy). В итоговом столбце - распределение тех же 40 единиц, но по признаку фактору х (обозначение частот fx). В последней графе рассчитывается среднее значение признака-результата, то есть :
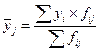 . (7.1)
. (7.1)
Например, для первой строки:
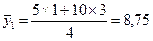 .
.
Эти значения могут быть использованы для построения эмпирической линий регрессии для и 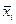 .
.
Как видно их таблицы, по мере увеличения значений х групповые средние значений тоже увеличиваются от группы к группе, что позволяет сделать вывод о том, что между признаками существует прямая корреляционная зависимость.
О наличии и направлении связи можно судить и по «внешнему виду» таблицы, т.е. по расположению в ней частот.
Так, если частоты разбросаны в клетках таблицы беспорядочно, то это чаще всего свидетельствует либо об отсутствии связи между группировочными признаками, либо об их незначительной зависимости.
Если же частоты сконцентрированы ближе к одной из диагоналей таблицы, образуя своего рода эллипс, то это почти всегда свидетельствует о наличие зависимости, близкой к линейной. Расположение по диагонали из верхнего левого угла в нижний правый свидетельствует о прямой линейной зависимости между показателями, наоборот – об обратной.
Рассмотрим конкретный пример. Менеджер по маркетингу в компании, владеющей сетью супермаркетов, желает оценить влияет ли расстояние между полками на объем продаж корма для домашних животных. Для анализа сформирована случайная выборка из 12 магазинов.
Таблица 7.2
Соотношение расстояний между полками в сети супермаркетов и
еженедельным объемом продаж
| Магазин | Расстояние между полками, Х (метры) | Еженедельный объем продаж, Y (тыс.долл.) |
| 1,52 | 0,16 | |
| 1,52 | 0,22 | |
| 1,52 | 0,14 | |
| 3,05 | 0,19 | |
| 3,05 | 0,24 | |
| 3,05 | 0,26 | |
| 4,57 | 0,23 | |
| 4,57 | 0,27 | |
| 4,57 | 0,28 | |
| 6,10 | 0,26 | |
| 6,10 | 0,29 | |
| 6,10 | 0,31 |
Для определения числа интервалов и величины интервала для построения корреляционной таблицы можно воспользоваться меню Statistics/Basic Statistics/Tables (рис. 7.1.)
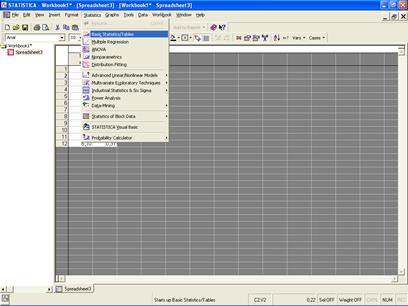
Рис. 7.1. Выбор меню Basic Statistics/Tables в ППП STATISTICA.
В появившемся окне выбираем пункт Frequency tables.
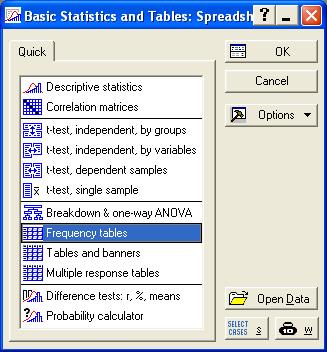
Рис. 7.2. Выбор меню Frequency tables.
С помощью кнопки Variables выбираем переменную, соответствующую зависимой (результативной) переменной, то есть у; переходим на закладку Advanced, на которой задаем необходимые опции построения таблицы частот. Напомним, что необходимо воспользоваться закладкой Options и убрать метку с поля Count and report missing data (MD), чтобы исключить подсчет незаполненных ячеек (рис. 7.3., 7.4.).
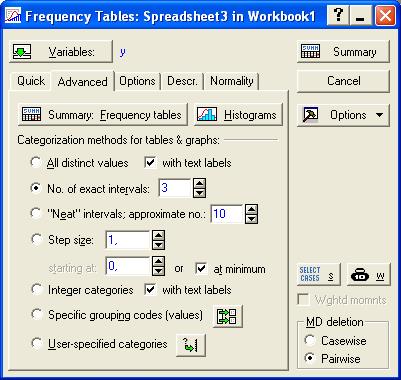
Рис. 7.3. Вид закладки Advanced функции Frequency tables.
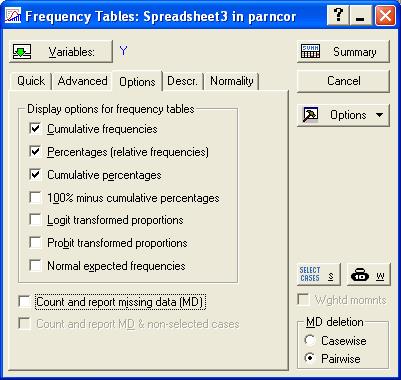
Рис. 7.4. Вид закладки Options функции Frequency tables.
Требования, предъявляемые к построению таблиц частот, а также подробное описание данного меню и описание содержания таблицы можно найти в первой части учебного пособия по статистике, посвященной анализу распределений.

Рис. 7.5. Распределение еженедельного объема продаж кормов для животных в супермаркетах с числом интервалов к = 3.
В данном примере подобрано число интервалов равное трем. При этом можно воспользоваться результатами, предложенными системой, как для определения числа интервалов, так и для определения величины интервала.
Возможен второй вариант – расчет величины интервала вручную:
 , (7.2)
, (7.2)
где R – размах вариации,
k – число интервалов.
В рамках данной работы строится корреляционная таблица с нанесенными на нее линиями регрессии х и у (рис. 7.6.). В первой строке представлены границы интервалов группировки результативного признака, в правом столбце – факторного. В левом столбце частоты факторного признака, в нижней строке - результативного. Во второй строке и в столбце, предшествующем правому приведены середины интервалов, используемые для расчета точек линии регрессии. В самой таблице звездочками отмечены координаты точек по двум показателям (попарно).
Далее рассчитываются средние значения признака-результата и признака-фактора в каждой группе. Они же являются точками линий регрессии. Точки эмпирической линии регрессии наносятся в масштабе квадратов таблицы, соответственно оси признака. Ниже приведены примеры расчета координат нескольких точек:
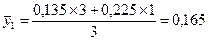 ,
,
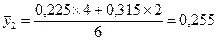
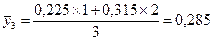
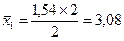
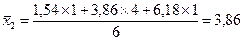
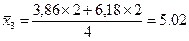 .
.
| fx | 0,09-0,17 | 0,17-0,26 | 0,26-0,35 | ∑f =12 | |
| 0,135 | 0,225 | 0,315 | |||
 ** **
| * | 1,54 | 0,38-2,7 | ||

| **** | ** | 3,86 | 2,7-5,02 | |
| * | ** | 6,18 | 5,02-7,34 | ||
| ∑f =12 | fy |
Рис. 7.6. Корреляционная таблица с наложенной линией регрессии.
Среднее значение признака-результата по всей совокупности:

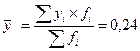 .
.
Для оценки тесноты связи между изучаемыми признаками (расчета эмпирического корреляционного отношения) необходимо определить значения дисперсий: общей и межгрупповой. Межгрупповая дисперсия равна:
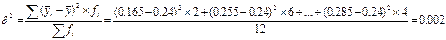
Общая дисперсия:

Эмпирическое корреляционное отношение:
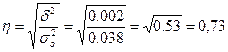 .
.
Коэффициент детерминации:
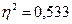
Полученное значение корреляционного отношения свидетельствует о наличии тесной корреляционной зависимости между изучаемыми характеристиками.
|
|
|
|
|
Дата добавления: 2015-07-02; Просмотров: 2790; Нарушение авторских прав?; Мы поможем в написании вашей работы!