КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Идеология организации без упорядоченного выполнения 2 страница
|
|
|
|
-Операционные устройства в процессоре представлены набором независимых функциональных устройств, выполняющих определенный для них перечень операций. Эти устройства на входах имеют буферные памяти для приема команд из потока декодированных инструкций в соответствии с кодами операций для выполнения которых они предназначены, образуя таким образом входные очереди для выполнения.
В качестве примеров рассмотрим архитектуры процессоров линейки Pentium фирмы INTEL, процессоров Power, процессоров Z990,Z10 Zархитектуры фирмы IBM. Выбор обусловлен тем, что в них прослеживаются все этапы исторического развития архитектуры процессоров.
Появлению линейки процессоров предшествовала линейка процессоров х86,которая объединила процессоры первых четырех поколений и начала старт с процессора 8086, задавшего основу направлений архитектур последующих процессоров, архитектура которого используется в простейших микроконтроллеров в настоящее время. Линейка процессоров х86 разрабатывалась с учетом использования их в системах с шинной организацией, и первый процессор 8086 был 16- разрядный и имел 20ти-разрядную адресную шину. Выбор шинной организации связи процессора с другими компонентами системы был обусловлен назначением процессора в микро эвм и персональных компьютерах. Внедрение технологии сегментной адресации при обращении к оперативной памяти стало основой в дальнейшем для внедрения режима виртуальной памяти и механизма защиты, необходимого для поддержки многопрограммного режима в последующих модификациях не только этой линейки, но и линейки Pentium. Последней модификацией линейки х86,стал процессор 486,который по своим функциональным возможностям сопоставим с майнфреймами средней производительности. По своей архитектуре этот процессор был близок к модифицируемой гарвардской архитектуре, имел встроенную кэш память команд и данных, конвейер для обработки команд и отдельно встроенное устройство для обработки команд арифметических операций с плавающей точкой. Был разработан с учетом использования в многопроцессорных системах. Для реализации конвейерной обработки пришлось внедрить сложную систему декодирования инструкций, так как система команд, используемая в линейке процессоров, имела CISC архитектуру, которая и потребовала введение дополнительных аппаратных средств для ее обработки.
Эстафету линейки процессоров х86 приняла линейка Pentium. Первым процессором в этой линейке стал процессор Pentium,который был первым суперскалярным процессором, в составе было два конвейера, один из которых был универсальным, выполняющим любую инструкцию из системы команд,а другой с ограниченными возможностями. Процессор имел блок предсказания переходов и операционный блок для выполнения инструкций класса SIMD. Процессоры Pentium2,3 были спроектированы на базовой архитектуре процессора Pentium Pro, в котором была реализована технология безупорядочного выполнения команд. Наличие операционных устройств с конвейерной организацией и буферных памятей для приема команд на исполнение, аппаратная реализация системы распределения команд в функциональные устройства в соответствии с кодами операций, наличие буферной памяти для хранения команд, ожидающих выполнения и диспетчеризации, а также буферной памяти для хранения команд выполненных,но не имеющих признак завершения- все эти аппаратные средства обеспечивали технологию безупоряочного выполнения команд в процессоре. В этих процессорах была внедрена технология предсказания переходов и выполнение по- предложению,то есть выполнение инструкций по направлению, выбранным блоком предсказания переходов не дожидаясь результата, полученного по окончанию выполнения команды перехода.
Особое внимание заслуживает архитектура Pentium4, в котором для выполнения команд используется кэш трасс, формируемая предварительно после загрузки инструкций в кэш L2 и с окончательной коррекцией во время выполнения в процессоре. Большинство процессоров этой линейки поддерживают мультипроцессорный режим работы.
Начало разработки линейки процессоров Power фирмы IBM было положено в 1990 году. Процессоры этой серии относятся к классу RISC процессоров, предназначенных для конвейерной обработки команд. В предлагаемых к рассмотрению архитектурах процессоров Power4,5,6 реализованы все технологии конвейерной обработки команд, а в процессорах Power5 и 6 имеется аппаратная поддержка многопоточного режима и организации логических партиций на уровне операционной системы. Мы уже отмечали,что во всех суперскалярных процессорах проводится на этапе декодирования инструкций формирование групп команд с целью контроля за выполнением команд на конвейере. Так вот архитектура Power6 интересна тем, что эта процедура вынесена за пределы конвейера и выполняется после загрузки команд в кэш L2 подобно тому, как в Pentium4 формируется предварительно кэш трасс. Линейка процессоров Power(Power 4,5,6) поддерживает организацию мультипроцессорного режима, используя для этого непосредственные связи между процессорами, технологию характерную для процессоров фирмы IBM, при организации узлов SMP, а для объединения узлов в большие многопроцессорные системы используются как магистрали, так и технология непосредственных связей. ПроцессораZ990 и Z10 являются представителями Zархитектуры, которая стала дальнейшим развитием архитектуры майнфреймов IBM360 И 370. Процессора этого класса относятся к CISC процессорам, получившим в наследство систему команд от майнфреймов IBM360 и 370. Так процессораZ990 и Z10 по этой причине, чтобы не усложнять структуру конвейера не используют безупорядочное выполнение команд. В процессоре Z10 используется конвейер с большим количеством ступеней, что дало возможность повысить частоту работы процессора до 4,4 ггц по сравнению с частотой процессора Z9,имеющего рабочую частоту 1,9ггц. Еще одной особенностью этой линейки процессоров является наличие совершенной системы контроля,восстановления и диагностики на микроархитектурном уровне. Процессора Zархитектуры используют технологию непосредственных связей с другими объектами системы, а для контроля за состоянием системы и сбора информации о состоянии процессора и выполнения процедур диагностики разработана система управления, реализуемая в сервисном процессоре, который имеет доступ ко всем основным узлам не только в процессоре,но и ко всем другим объектам в компьютере, используя для этого внутреннюю сеть.
Архитектура процессора Pentium Pro
(Pentium Pro) ставший в свое время базовой для процессоров Pentium 2 и 3. Микроархитектура этого процессора содержит аппаратные средства, обеспечивающие конвейерную обработку команд и всех ситуаций, возникающих при этом, ранее нами рассмотренных аппаратными средствами.
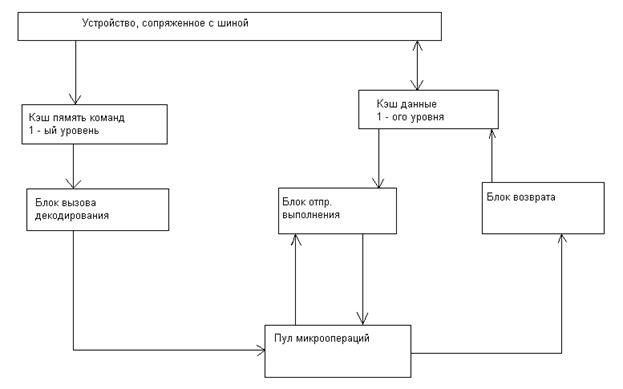
Как видно из блок схемы процессор содержит 3 отдельных независимых функциональных блока, обеспечивающих 3х фазную обработку команд.
А) выборка
Б) выполнение
В) завершение
Эта классическая структура применялась и ранее в предыдущих поколениях различных микроархитектур, с той лишь разницей, что для CISC моделей эти функциональные блоки были связаны воедино во время выполнения отдельной команды. Наличие кэш команд и данных 1 ого уровня является признаком модифицированной Гарвардской архитектуры, обеспечивающей совмещение выполнения выборки очередной команды c выполнением предыдущей. Эта технология была использована и ранее, к примеру, в наших отечественных моделях (ЕС 1045 и др.).
Микроархитектура блока декодирования имеет классические элементы, присущие любой системе, будь то жесткая логика или микропрограммное управление и предназначены для дешифрации команд и задания алгоритма обработки команд в процессоре. Но с другой стороны каждый блок имеет свои особенности, связанные со структурой и форматами команд, поступающих на обработку. Так в рассматриваемой архитектуре. команды имеют сложную структуру, которые разрабатывались без учета конвейерной обработки еще в предыдущих моделях (CISC).
Поэтому для сохранения преемственности программного обеспечения пришлось разрабатывать сложные декодеры, преобразующие СISC команды в набор микроопераций, представляющих по сути RISC команды. Для решения этой задачи пришлось разрабатывать достаточно сложные декодеры и организовывать многостадийный конвейер в рамках блока. Как мы уже говорили ранее, что формат команд, используемых в микропроцессорах класса х86 и в последующих разработках на базовой модели P6,
кроме поля кода операции имеет поле байта-модификатора в которых содержится вся информация о структуре команды, ее длине и способах адресации операндов, которая и служит исходной информацией для разработки аппаратных средств декодеров..
По сути, о чем мы сейчас говорили это классическая функция блока декодирования по преобразованию команды в набор микроопераций. Тогда же в чем же особенность?
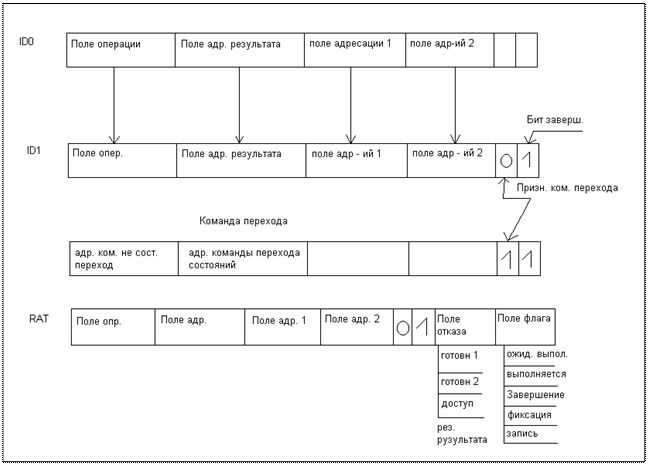
А особенность заключается в том, что в CISC архитектурах микрооперации, выполняющиеся последовательно одна за другой функционально связаны, как и команды в программном коде, адрес текущей определяет адрес последующей. В данном же решении микрооперации выходящие из декодера сохраняются в промежуточном буфере, становясь доступными группе исполняющих устройств, для которых они предназначены независимо от принадлежности команд в программном коде.
Возникает вопрос? А как же строгая последовательность программного кода. А для этого декодер на этапе декодирования связывает в цепочку микрооперации, принадлежащие одной команде, для того чтобы в процессе выполнение команды считать выполненной, когда все микрооперации в цепочке устанавливают флаг статуса «выполненных». А так как в случае беспорядочного выполнения возможно и внеочередное выполнение команды, команда удаляется из процессора только в том случае, если предыдущие команды выполнены.
Именно чтобы обеспечить эту функцию аппаратными средствами используется буфер микроопераций, в котором микрооперации записываются и удаляются в строгой последовательности согласно программному коду.
Как видно из блок схемы буфер микроопераций (пул микроопераций) является связывающим звеном между тремя основными блоками в процессоре. Он представляет адресуемую память, состоящую из 40 регистров. Он содержит микрооперации ожидающие выполнения, а также те, Которые уже выполнены, но не получили статус удаления из буфера «фиксация». Устройство диспетчера может выбирать для выполнения, как уже упомянуто выше, любую микрооперацию при готовности операндов и наличии свободного функционального устройства для их обработки Максимально 2 физических регистра со статусом завершения (удаления) могут быть прочитаны в каждом цикле. А теперь кратко о стадиях конвейера блока выборки декодирования. Наличие 3х стадий IF0, IF1, IF2 на этапе выборки объясняется следующими причинами.
выборка из кэш (32 байта кода программ.)
определение начала команд, их длина в области 32 байта (дешифрация кода команды и байта модификатора)
этап выравнивания. Т.к. декодеры работают с жестко распределенными полями в формате команды.
Команда, поступающая из декодирования должна быть выровнена на начало границы ввиду того, что в границах 32х байта считанных их кэш может начинаться не обязательно с 0 – ого байта.
Этап декодирования включает 2 стадии: ID0, ID1.
Первая собственно предназначена для формирования форматов микроопераций.
Вторая для выстраивания очереди микроопераций.
Блок формирования очереди работает следующим образом:
Получив микрооперацию от декодера, он контролирует прием бита «завершения» из декодера в каждой следующей микрооперации и при получении его устанавливать признак конца цепочки, таким образом, связывая все микрооперации относящиеся к одной команде.
На этой же стадии конвейера получая от декодера признак команды, в случае обнаружения команды перехода формируется адрес следующей команды
с учетом, что переход назад более вероятен, чем вперед, на случай если блок предсказания не имеет другой информации о направлении перехода.
Блок декодирования имеет в своем составе 3 декодера, 2 предназначены для декодирования «простых» команд и один «сложный», декодирующий как простые, так и сложные команды. При работе декодеров имеется своя специфика. Если «сложный» декодер захватывает сложную команду, за которой следует «простые» две команды, то работают все декодера. Если же идет простых 3 команды, то 3 декодера работают одновременно и выдают в одном такте 3 микрооперации.
4 – 1 – 1 (6 микроопераций)
1 – 4 – 1 (2 микрооперации)
1 – 1 – 1 (3 микрооперации)
Этап RAT.
На этой стадии конвейера поддерживается переименование регистров (логических) программных в физические для исключения конфликтов WAR и WAW. Реальные программные регистры могут быть заменены в микрооперации любым из 40 внутренних, находящиеся в буфере.
Кроме того, на этой стадии к коду микрооперации добавляется поле статуса и поле «флагов», после чего микрооперации поступают в пул микрооперации, поле микрооперации дополняется разрядами для хранения значений самих операндов.
|
Устройство выборки (декодирования)

Пул инструкций.
Пул инструкций принимает поток микроопераций, определяемый программным кодом. Он представляет адресуемую память, состоящую из 40 регистров. Он содержит микрооперацию ожидающую выполнения, а также те, которые уже выполнены, но не получили статус «фиксации». Устройство диспетчеризации может выбирать для выполнения любую микрооперацию при готовности операндов. Максимально 2 физических регистра со статусом завершения могут быть прочитаны в каждом цикле.
Устройство диспетчеризации / выполнения.
Устройство диспетчеризации / выполнения является устройством безпорядоченного выполнения, которое диспетчеризирует и выполняет согласно зависимости данных и доступности ресурсов. Выбор и диспетчеризация микроопераций из пула инструкций управляется станцией резервирования. Она постоянно сканирует пул инструкций с целью поиска микроопераций готовых для выполнения. Т.е. все источники – операнды доступны и диспетчеризация их к доступным устройствам.
Результат выполнения микрооперации возвращается в пул и хранится совместно и микрооперациями до тех пор, пока не обработаются устройством восстановления.
Процесс выполнения и диспетчеризации является классическим процессом безупорядоченного выполнения, где микрооперации обрабатываются в соответствии с готовностью данных и наличия ресурсов без учета порядка следования в программе.
Когда 2 или более микрооперации одного типа претендуют в одно и тоже время на один ресурс, они выполняются в порядке FIFO поступления в пул.
Исполнение микрооперации осуществляется двумя целочисленными устройствами, двумя устройствами с плавающей точкой и одним устройством обращения к памяти, позволяя диспетчеризовать до 5 микроопераций за такт. Устройство формирования адресов для команд перехода промахи перехода и сигнализирует BTB произвести перезагрузку конвейера. Устройство связи с памятью управляет микрооперациями «Загрузка» и «Запись». Для чтения из памяти достаточно одного адреса, поэтому эта операция декодирует в одну микроперацию. Запись декодируется в 2 микрооперации (адрес/данные).
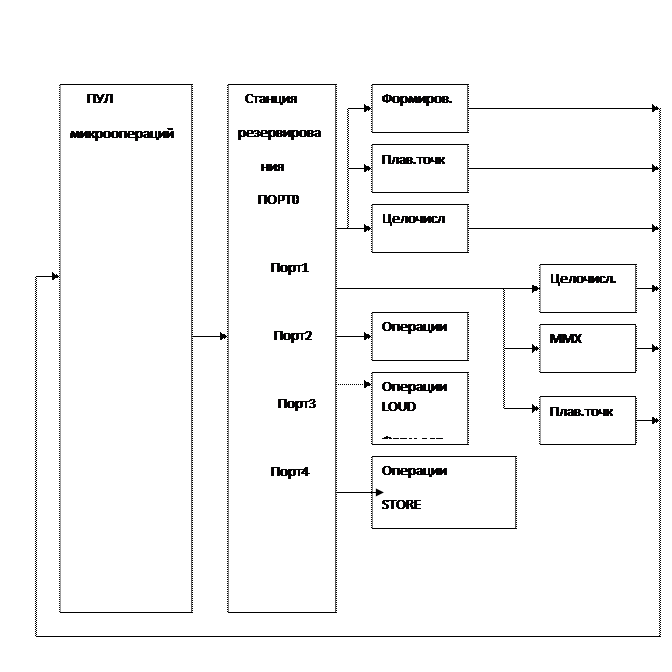
Блок обработки с изменением последовательности.
Основная задача этого блока осуществлять контроль за состоянием микрооперацией находящейся в пуле инструкций и по мере их готовности к выполнению в других устройствах помещать их для выполнения. Попав в пул, микрооперация становится доступной
Для выполнения в функциональных устройствах, о чем свидетельствует бит «готовности» в поле типов микрооперации. Длина очереди 20 элементов.
Диспетчер распределяет микрооперации по портам, которые связаны с функциональным устройством. При этом каждый порт имеет свои собственные очереди, в виде FIFO.
Некоторые функциональные устройства разделяют один порт, который является мультиплексным. Может случиться так, что в такте будет несколько микроопераций, претендующих на обработку. В этом случае вступает механизм приоритета, учитывающий «важность микрооперации» и ее момент поступления в ROB (пул инструкций). Так, например микрооперация перехода считается важнее, нежели микрооперация обработки целых чисел.
Микрооперация, попав в порт после обработки в функциональном блоке «возвращается» в пул инструкций, получая статус «выполнена». Функциональный блок должен «знать» адрес регистра в ПУЛе, значение которого должно сопровождаться инструкцией.
Т.е. являться тегом ее в процессе всей обработки. Исходя из стадий конвейера, который реализует работу блока, а их 3. Можно предположить, что:
1) ROB является полностью ассоциативной памятью.
2) для выдачи микроопераций в станцию резервирования в ROB участвуют только регистры с меткой «очередь» (стадия резервации).
3) Поиск осуществляется по коду операции или нескольких их возможных значений.
4) Каждый порт для организации связи с ячейкой ROB имеет магистраль, на которую выходит регистры ROBа. Только в этом случае поиск может быть осуществлен за один такт и эти же регистры могут выдать информацию в порт в следующем такте. Для возвращения результата в ROB функциональные блоки ы также должны иметь собственные магистрали для записи результатов в ROB.
Основное назначение блока восстановления.
Основное назначение блока восстановления - отправлять результаты спекулятивного выполненных микроопераций в машинные регистры, адресуемые в программном коде или в ячейки оперативной памяти. Т.е. следить за выполнением микрооперации в пулt инструкций и записывать результаты их выполнения строго согласно программному коду.
Для этого подобно станции резервирования блок восстановления постоянно контролирует состояние микрооперации в пуле инструкций, просматривая, чтобы они были выполнены и не имели бы зависимости от других микроопераций в пуле, прежде чем фиксировать их окончательные результаты в процессоре, учитывая при этом наличие прерывания исключений и условие перехода.
Устройство восстановления способно восстанавливать до 3х микроопераций в такт, после того, как результаты микрооперации зафиксировали в машинных регистрах, они удаляются из пула. Подобно блоку отправки / выполнения конвейер блока восстановления имеет 3 стадии.
Анализ выполнения операции
Запись результатов в машинные регистры
Удаление выполненных микроопераций.
Устройство сопряжения с шиной предназначено для связи процессора с кэш памятью 1 ого и 2 ого уровня и системной памятью. Связь с кэш 1-ого уровня осуществляется для кэш данных и кэш команд, осуществляя реализацию модифицированной гарвардской архитектуры. Связь с памятью 2 ого уровня осуществляется по отдельной шине 64 бит. Системная шина представляет собой группы сигналов независимых. функционально друг от друга, тем самым, обеспечивая конвейерную организацию. Для обеспечения конвейерной организации устройство шинного интерфейса содержит буфер запросов к памяти, состоящей из очередей по записи и чтению. Данный буфер обеспечивает, например выполнение запросов чтения, давая возможность «обгонять» операциям чтения, операции записи, тем самым осуществлять спекулятивное чтение данных, то есть доставляя их заранее в процессор.Следует отметить запись осуществляются только строго в программной последовательности.
С учетом безупорядоченного выполнения и чтения как следствие данного режима устройство сопряжения с шиной или «записи/чтения» должно обеспечивать следующие условия:
1) Запись никогда не выполняется спекулятивно
2) Запись выполняется только в программном порядке
3) Операции записи диспетчеризуются только когда адрес и данные доступны и нет более старшей записи, ожидающей диспетчеризации
4) Запись может быть блокирована, чтобы дать возможность ее обходить операциям чтения.
5) Возможность «спекулятивного» выполнения чтения когда более младшая операция чтения обгоняет старшиеперации чтения.
Для реализации чтения необходимо:

Для записи

В связи с этим каждому входу очереди запросов на запись соответствует
Очередь SRQ – содержит адрес записи
Очередь SDQ – содержит данные записи
Для очереди на чтение соответствующей очереди LRQ
Вход SDQ содержит результат, который должен быть записан после того, как все предыдущие микрооперации в пуле будут в фазе завершения, как только будет разрешение их удаления данные должны быть записаны в память.
Архитектура процессора Pentium4
Если кратко характеризовать архитектуру Pentium 4 можно отметить следующее.
Процессор Pentium 4 также как и Р6 состоит из 3х основных функциональных блоков:
устройство предварительной обработки инструкций в порядке их следования в программном коде. Результатом работы этого блока является последовательность микроопераций, поставляемые в исполнительном блоке.
блок выполнения микроопераций реализующий алгоритм безупорядоченного выполнения.
блок завершения.
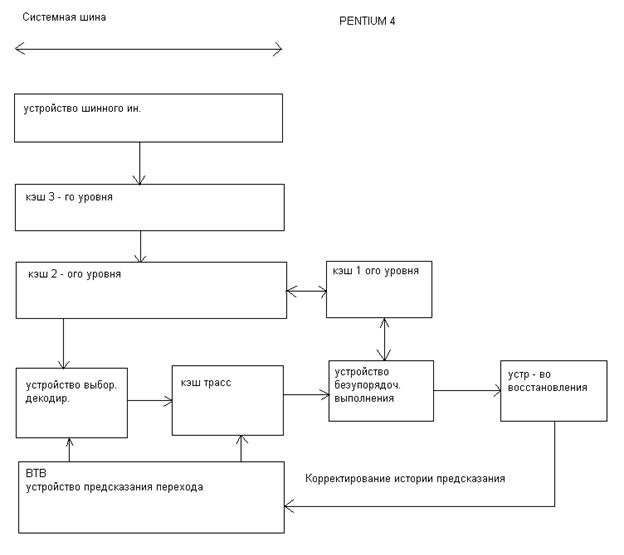
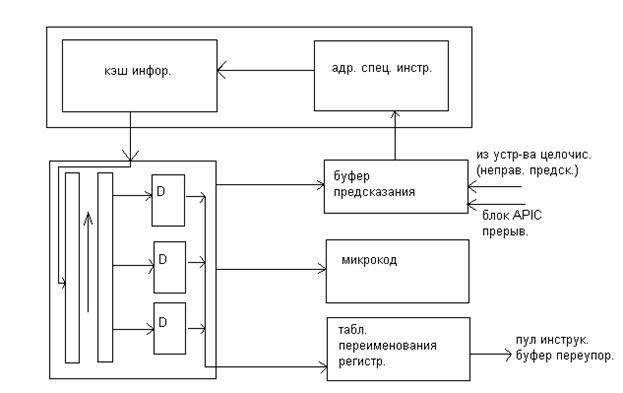
Основное отличие от Р6, это наличие кэш трасс, представляющие память декодированных инструкций т.е. микрооперации, которые читаются из кэш трасс в буферах исполнительного устройства.
Как и в Р6 микрооперации формируются по коду выполнения программы, с той или иной лишь разницей, что эту работу блок предварительной выборки производит заранее и накапливает их в памяти. При этом работает блок предсказания перехода, который выбирает направление выполнения программы и как бы «сшивая» единую последовательность микроопераций, устраивая не только безусловные переходы, но и условные на основании данных в блоке предсказания.
Если при декодировании встречается «сложная» инструкция то как и в Р6 используется постоянная память ROM, в которой уже находиться последовательность микроопераций данной инструкции. При этом эти микрооперации не вставляются в кэш трасс и ставятся на место инструкции «заплатка» - указатель /адрес на место нахождения последовательности микроопераций в ROM.
В случае «промаха» в кэш трасс инструкции выбираются из более высокого уровня памяти. Декодируются таким образом поколения кэш трасс. Такая операция формирования сегмента кэш трасс занимает от 10,15 ти тактов до 30 ти т.е., «скрытый участок» конвейера достаточно сложная операция т.к. она проводится заранее и имеет большую «емкость» кэш трасс. Эти издержки вполне допустимы.
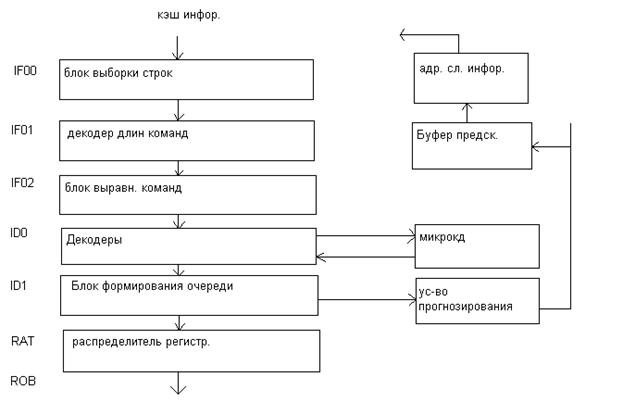
Сравним количество стадий конвейера устройства выборки/декодирования (без учета формирования очередной линейки кэш трасс) 8 по отношению к 7 стадиям в Р6. Кэш трасс представляет как бы память микропрограмм, формируемая динамически в процессе работы в процессоре и дает возможность многократно выполнять не только повторяющие инструкции но и целый сегмент программного кода.
Так на что же расходуются эти 8 стадий?
Первые 4 такта – извлечение последовательности из кэш трасс и предсказание перехода. Первый раз уже блок формирования адреса перехода выполняет свою функцию при формировании трассы но т.к. от этого момента до выполнения в процессоре проходит достаточно времени и блок предсказания переходов может иметь обновленные данные о ходе выполнения программы, то для «корреляции» в текущем моменте блок активизируется вторично. 1 такт уходит на буферизацию микроинструкции после чтения из кэш трасс и еще 1 такт чтобы выбрать «тройку» микроинструкций из очереди подготовить для нее ресурсы процессора. 2 такта уходит на замену логических регистров в микроинструкциях временными физическими из таблицы замены регистров.
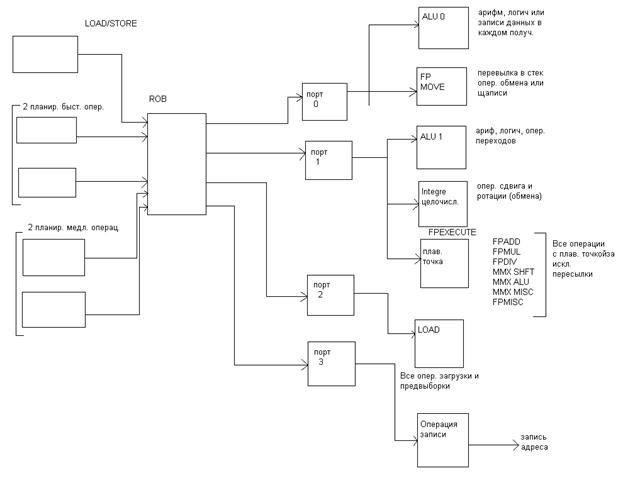
Функциональные исполнительные устройства в Pentium 4
После того как инструкция поступила в пул инструкций, процессор начинает распределять их по соответствующим исполнительным устройствам.
Принцип такой же как и в Р6, но имеет свои особенности.
Во первых, если в Р6 выполнение всех микроинструкций на стадии резервирования управляется одним планировщиком, то в Pent 4 таких планировщиков 5, которые «разбирают» микроинструкцию в пуле. Все микрооперации обращения к памяти формируются в отдельную очередь, которую контролирует отдельный планировщик (16 микроопераций).
Все другие формируются в другую очередь, которая управляется 2 мя «быстрыми» и 2 мя «медленными» планировщиками. Всеми простыми арифметически-логическими операциями управляют быстрые планировщики, которые распределяют по 2 микроинструкци за такт.
Вторая особенность - микроинструкции отправляются выполняться на исполнительное устройство к тому моменту времени, когда должны поступить операнды из кэш. Если в Р6 схема обработки выглядит так:
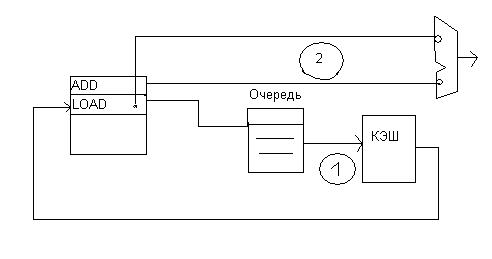
В Pentium 4 работают 2 независимых планировщика со своими микрооперациями, согласовывая (синхронизируя) между собой свои действия.
Например. планировщик распределяя микроинструкцию LOAD обращаясь за операндом в память, обязан сообщить всем остальным о постановке ее в очередь.. Планировщик, управляющий операцией сложения, в которой участвует этот операнд из памяти обязан поставить в очередь и отправить микрооперацию в исполнительное устройство с задержкой с таким расчетом, чтобы к появлению данных из кэш на шине микроинструкция была в исполнительном устройстве. Это теоретически. На самом деле чтобы избежать критической ситуации, когда данных не будет в кэш, конвейер исполнительного устройства имеет аппаратные средства повторить микроинструкцию, используя дублирующую копию микроинструкции, которая продвигалась параллельно по дублирующему псевдоконвейеру, не подвергаясь обработке в функциональном устройстве. Это делается‘ с той целью чтобы в случае промаха возвратить микроинструкцию на основной конвейер для повтора.
Архитектура кэш трасс
Кэш состоит из блоков размером в 6 "ячеек" для размещения микроинструкций. Обычно МОП занимает одну ячейку Т-кэша. Однако в случаях, когда МОП соответствует x86-инструкции, содержащей литеральную константу либо непосредственный адрес (смещение), и длина значимой части этой константы превышает 16 разрядов, требуется дополнительное место для размещения недостающей информации. В ряде случаев место может быть выделено в соседних ячейках при условии, что поле литеральной константы в этих ячейках не занято. При отсутствии такой возможности выделяется дополнительная ячейка. В этом случае обе ячейки, составляющие МОП, должны размещаться в одном блоке кэша. Кроме того, если x86-инструкция состоит из нескольких МОПов (до 4-х), то все эти МОПы должны также размещаться в одном блоке. Существуют и некоторые другие ограничения на размещение МОПов.
 Темп последовательного чтения из Т-кэша составляет 1 блок за 2 такта, или 3 МОПа за такт - что находится в соответствии с темпом декодирования и отставки микроинструкций, а также их обработки на некоторых промежуточных стадиях.
Темп последовательного чтения из Т-кэша составляет 1 блок за 2 такта, или 3 МОПа за такт - что находится в соответствии с темпом декодирования и отставки микроинструкций, а также их обработки на некоторых промежуточных стадиях.
Объём Т-кэша составляет 12K ячеек, или 2048 блоков, организованных в 256 наборов по 8 блоков. Для преобразования программного адреса первой x86-инструкции в каждой трассе (как правило, это инструкция, на которую производится переход) в положение первого блока трассы (заголовка трассы) в кэше используется комбинированный алгоритм, сочетающий прямую адресацию по нескольким разрядам программного адреса инструкции с ассоциативным поиском. Разряды этого адреса b10-3 указывают номер набора, а нахождение требуемого блока в наборе осуществляется сравнением остальных разрядов адреса (ключа) с соответствующими разрядами адреса (тэгами), хранящимися для каждого блока в наборе. Для ускорения поиска сначала происходит сравнение нескольких разрядов ключа с соответствующими разрядами тэга - мини-тэгом. Мини-тэг включает в себя 6 разрядов - b13-11 и b2-0. При нахождении блока с требуемым мини-тэгом происходит выборка инструкций с одновременной проверкой оставшейся части тэга.
На Рис. 4 приведён пример отображения последовательных блоков инструкций на наборы классического I-кэша, а на Рис. 5 показана организация хранения трасс в Т-кэше. Также показана структура программного адреса первой инструкции в трассе при доступе к первому блоку трассы в Т-кэше. Буквами S обозначены разряды номера набора, буквами M - разряды мини-тэга, и буквами T - разряды оставшейся части тэга.
|
|
|
|
|
Дата добавления: 2014-01-03; Просмотров: 391; Нарушение авторских прав?; Мы поможем в написании вашей работы!