КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Идеология организации без упорядоченного выполнения 1 страница
|
|
|
|
В свое время узел формирования адреса был вынесен из операционного блока, с той целью, чтобы освободить основной сумматор от вычисления адресов операнда и перенести в блок выборки команд, в котором в совокупности с КЭШ памятью команд организован законченный цикл подготовки операндов к выполнению операций над ними в операционном блоке. Таким образом сформировать 2х ступенчатый конвейер в процессоре.
Идеология без упорядоченного выполнения основана на предварительном анализе команд по возникновению конфликтов при их выполнении, задержки их выпуска по конвейер и пропуска внеочередных команд, которые могут быть беспрепятственно выполнены. Конфликты эти относятся в первую очередь к группе конфликтов по данным. Конфликты эти классифицируются по типу RAW и WAR, WAW.
Первоначально анализ возможного возникновения этих конфликтов проводился на стадии декодирования и вычисления операндов, в дальнейшем для реализации без упорядоченного выполнения формирование адресов операндов выделили в отдельную стадию конвейера с той целью, чтобы дать возможность пропускать на конвейер внеочередные команды, не вызывающие конфликты WAW и RAW, и не блокировать конвейер на первой стадии. Таким образом, стадия декодирования была разбита на два такта:
1. Такт выдачи
2. Такт чтения операндов
Такт выдачи стал контролировать ситуацию использования регистра результата в команде, предыдущими командами в качестве регистра результата (WAW – запись после записи) с целью избежать искажения при предыдущих команд. Если такая ситуация могла иметь место, то команда не выпускала на конвейер.
На этапе чтения операндов анализировать стали возможность возникновения RAW при выпуске команды на конвейер, т.е. операнды источники проходят проверку не являются ли они регистрами результата предыдущих команд, находящихся в стадии выполнения или в данный момент не происходит ли запись из функционального устройства по адресу источника в команде.
В связи с без упорядоченным выполнением, завершающую стадию конвейера, связанную с записью результата в регистровый файл, пришлось разделить на 2 части.
Это первая предварительная - стадия завершение.
Вторая – запись результата.
На этапе запись результата блок управления конвейером отслеживает возможность возникновения конфликтов типа WAR для того, чтобы исключить искажение значений в регистрах, используемых в качестве источников предыдущими командами, находящимися на стадии выполнения.
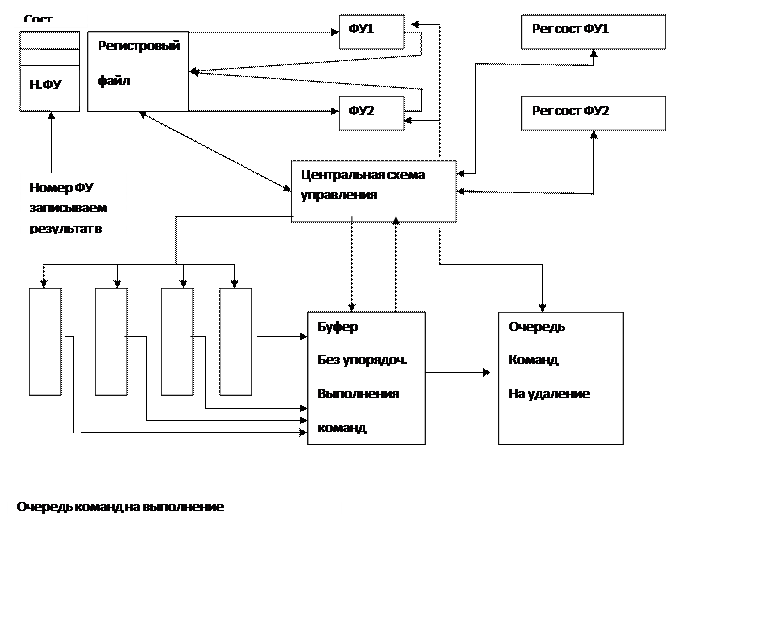
Как следует из представленной блок–схемы, централизованная схема управления осуществляет контроль за приемом команд во входную очередь, загружая их в буфер без упорядоченного выполнения. При готовности операндов и наличии свободных функциональных устройств централизованная схема управления передает команды им на выполнение и по завершении передает их в очередь команд на удаление,соблюдая последовательность программного кода.
Алгоритм Томасуло
С одной стороны выделение чтения операндов в отдельную стадию конвейера наводит на мысль о возможности размещения узла формирования адресов операндов в глубину конвейера с целью его параллельной работы с другими функциональными блоками операционного устройства. В этом случае отпадает необходимость в начале конвейера держать буфер для команд,ожидающих выполнения только при одном условии, если будут отсутствовать в системе конфликты RAW, которые контролирует эта стадия.
Одним из способов устранения конфликтов типа RAW-это наличие обходных цепей, когда результат сумматора передается на один из его входов в случае использования его в качестве источника в следующей команде. В этом случае в регистровом файле просто будут отсутствовать источники, которые могут быть прочитаны раньше чем попадет в них конечный результат, потому что все результаты,которые будут использованы в следующей команде в качестве источника просто не будут записываться в регистровый файл. Следовательно, при использовании технологии без упорядоченного выполнения можно воспользоваться методом обходных цепей.
И так целесообразность перемещения узла чтения операндов в глубь конвейера будет только в том случае, если операционное устройство, имея блочную структуру, будет иметь для каждого функционального узла буфер команд, ожидающих выполнения; уже с готовыми операндами,, а блок чтения операндов имея свой буфер с адресами для операндов будет поставщиком операндов в эти функционального устройства.
Это во-первых, а во-вторых и основное промежуточные результат вычислений не будет передаваться в регистровый файл, а будет перемещаться из одного функционального устройства в другое или же в свое во входную очередь подобно архитектуре обходных цепей в сумматоре, а запись результата выполнения операции будет производиться только при завершении всех предыдущих команд при отсутствии конфликтов WAR, подобно как это делается при централизованном управлении при заключительной стадии конвейера «Запись результата».
Конфликты WAW, отслеживаемые при централизованном управлении просто будут отсутствовать, так как будет исключена ситуация циклов ранней преждевременной записи в регистровый файл в силу логики работы распределенных схем контроля за конфликтами.
Конфликты RAW при распределенной схеме управления конвейером не будут возникать же из-за того, что все циклы чтения промежуточных результатов из регистрового файла просто отсутствует, так как эти результаты будут подаваться непосредственно на исполнительное устройство из других функциональных блоков..
Без обходных цепей в сумматоре … … С обходными цепями в сумматоре
ADD R1R2R3 ID EX WB ID EX
 SUB R4R1R3 ID EX WB ID EX WB
SUB R4R1R3 ID EX WB ID EX WB
Невозможна одновременная запись и чтение в R1
конфликт просто не возникает т.к. результат ADD поступает на вход сумматоре для вычитания.
… ….
Вышеописанная технология реализует алгоритм Томасуло, основные принципы которого мы и отметим.
Но прежде чем сформулировать эти принципы рассмотрим еще способ устранения конфликтов типа WAR на конвейере. Таким является способ переименования регистров.





 1.R5=R1+R2 ID EX W структурный конфликт: регистр. файл занят;
1.R5=R1+R2 ID EX W структурный конфликт: регистр. файл занят;


 2.R6=R0*R5 ID EX W запись 2-ой команды
2.R6=R0*R5 ID EX W запись 2-ой команды




 3.R5=R3+R4
3.R5=R3+R4
регистр R5 ЗАНЯТ 2ой командой запись не возможна

 4.R7=R0*R5
4.R7=R0*R5
 |



 ID EX EX W RAW конфликт поR5 между 1и 2 командами
ID EX EX W RAW конфликт поR5 между 1и 2 командами







 ID EX EX W RAW R5 занят 3ей командой
ID EX EX W RAW R5 занят 3ей командой


 5.R5=R1+R2
5.R5=R1+R2


 6.R6=R0*R5 IDEX W как видно из примера переименование регистров
6.R6=R0*R5 IDEX W как видно из примера переименование регистров
 7.S1=R3+R4 ID EX W увеличивает производительность работы конвейера
7.S1=R3+R4 ID EX W увеличивает производительность работы конвейера

 8.R7=R0*S1
8.R7=R0*S1

 ID EX EX W
ID EX EX W

 ID EX EX W
ID EX EX W
Метод переименования регистров (пример)
Предположим, что необходимо вычисление (¬x + ¬y)c
¬x = ix1 + jy2; ¬x + ¬y=i(x1+x2) + j(y1+y2)
¬y=ix2 + jy2; c(¬x + ¬y)=ic(x1+x2) + c(y1+y2)j
Т.е. значение координаты нового вектора: c(x1+x2), c(y1+y2) которые будут помещены в регистровый файл.
Данные вычисления будут производиться на суперскалярном процессоре имеющего 2 конвейера: конвейер с фиксированной точкой (операции сложения) и конвейер умножения (множительное устройство)
Программа для выполнения:
ADD R5=R1+R2
MUL R6=R0*R5
ADD R5=R3+R4
MUL R7=R0*R5
Общая схема:
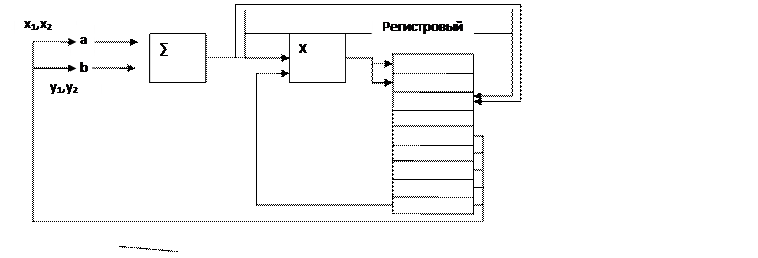
Анализ работы суперскалярного процессора с использованием переименования регистров показывает, что возможно окончание выполнения команд не в том порядке, как они расположены в программном коде т.е. на лицо внеочередное выполнение команд.
Для организации выдачи результатов в порядке определяющем программным кодом необходимо сохранять содержимое временных регистров до того времени, когда вся предыдущая команда закончит выполнение и будут удалены из конвейера. В течении времени пока временный регистр содержит данные он используется последующими командами как источник. Т.е. отсюда вывод: при суперскалярной архитектуре использование временных регистров необходим блок выходной очереди команд, который будет контролировать окончание выполнения команд в двух фазах:
1. Завершение
2. Запись результата
Удаляя с конвейера те команды, которые будут иметь статус второй фазы.
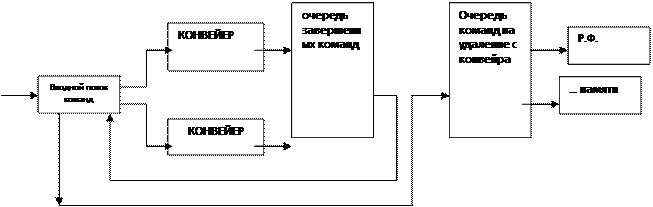
Одной из проблем без упорядоченного выполнения является ситуация возникающая при обработке прерываний, когда необходимо восстановить состояние процессора до начала выполнения команды, вызвавшей прерывание.
При последовательном выполнении команды этой ситуации не возникает, а так при без упорядоченном выполнении возможно окончание последующих, ранее предыдущих, а при выполнении предыдущих могут возникнуть прерывания, а исходные данные последующих может быть уже нельзя восстановить, вот тогда и возникает ситуация выход из которой можно найти
А) сохранение исходных данных команд, находящихся в буферах исполнительных устройств и всех команд в буфере очередности, контролирующего последовательность выполнения программного кода, имеющих статус “‘ завершение”.
Если возникнет прерывание, то состояние машины можно будет восстановить до точки предшествующей всем командам выполненным вне очереди
Б) сохранение всех результатов в буфере, который хранит новые значения всех команд, находящихся в состоянии “завершение”
В) выдавать команды на этап запись результата”,если известно что все предыдущие команды выполнены без прерываний или, что ни одна из предыдущих команд не будет завершена пока не будет обработано прерывание.
Г) Хранить все адреса команд и сами команды, находящиеся на не выполнении в конвейере.
Предпосылки для внедрения технологии предсказания переходов
Безупорядоченное выполнение и механизм обработки прерываний в процессоре в этом случае, который восстанавливает состояние процессора после не одной, а возможно нескольких выполненных команд, наводит на мысль об использовании технологии предсказания переходов. Направлять поток выполненных команд на основе предсказаний, а в случае ошибки восстанавливать состояние процессора и начинать выполнение программы по адресу, сохраненному в процессоре, в случае ложного предсказания. Точно также как это осуществлялось при обработке прерывания, только вместо адреса перехода по прерыванию, используется адрес, по которому должно переходить выполнение программы в случае ложного предсказания. Но реализация идеи выполнения команд по предположению, так же как и без упорядоченное выполнение, требует внедрения дополнительных аппаратных средств в архитектуру, процессора и это в первую очередь будет буфер переупорядочивания,, который представляет дополнительные виртуальные ресурсы как и станция резервирования в алгоритме Томасуло. Буфер хранит промежуточные результаты от момента завершения операции до ее стадии “запись результата”.
Буфер является источником операндов для команд, точно так же как станция резервирования, обеспечивающая промежуточное хранение и передачу операндов в алгоритме Томасуло. После того как команда в алгоритме Томасуло записала результат в регистровый файл, он становится доступным для других команд. В случае выполнения команд с использованием механизма предсказания адреса перехода, запись в регистровый файл, производится только после получения результата условия, по которому должен быть произведен переход в программе. Только после этого все команды, следующие за командой перехода получают статус”запись результата”. Вот поэтому каждая команда имеет позицию в буфере переупорядочивания до тех пор пока она не получит статус “запись результата”., Результат помечается номером строки в буфере, а не номером станции резервирования. Вот почему станции резервирования,получая данные из буфера, обязаны отслеживать номер строки, чтобы отправить результат операции в строку буфера из которого были получены исходные данные.
Заключение:
Блок операций в ЭВМ первых поколений, представляющий собой многофункциональное устройство все виды арифметических операций выполнял, используя операцию сложения и сдвиговые операции. С внедрением интегральных микросхем в элементную базу стали применять табличные методы, используя для этого специальные микросхемы ППЗУ, что значительно позволило сократить время выполнения операций умножения и деления в операционном блоке. С внедрением конвейерной обработки команд операционный блок стал представлять собой набор функциональных блоков, каждый из которых выполнял только ограниченный набор арифметических операций. Такая архитектура давала возможность в процессоре выполнение нескольких операций одновременно. Конвейерная обработка команд позволила значительно повысить производительность системы, но при этом перед разработчиками ЭВМ возникли новые проблемы, связанные с появлением конфликтов при обработке команд, которые стали причиной задержек в работе конвейера. Для того чтобы их устранить или уменьшить их влияние на функционирование конвейера, пришлось вводить дополнительные аппаратные средства в архитектуру процессора.
Один вид конфликтов (WAR) когда адрес регистра результата в команде используется как адрес источника в предыдущей был разрешен с помощью метода переименования регистров, суть которого заключалась в том, что при обнаружении вышеупомянутой ситуации запись результата в команде стали производить в альтернативный регистр, выполняющего функцию клона программного регистра, указанного в команде, чтобы не дожидаться выполнения предыдущей команды и не исказить ее результат. При удалении команды с конвейера данные из регистра-клона записывались в программный регистр, указанный в команде. Эта технология дала возможность увеличить производительность работы конвейера реализующего безупорядочное выполнение команд в процессоре. Без этого метода на конвейер выпускались вне очереди только те команды, которые не конфликтовали с предыдущими ни по адресам как источников в них так и по адресам записи результатов.
Другой тип конфликта(RAW) на конвейере стал возникать, когда очередная команда, поступающая на конвейер, должна дожидаться результата в предыдущей, потому что один из ее адресов источников имел то же значение что адрес регистра результата в предыдущей команде. Конфликт этот устранить нельзя, но время потерь сократить можно, подавая значение результата в операционное устройство, не записывая предварительно его в регистр результата.
Конфликт(WAW), появился в следствии безупорядочного выполнения команд на конвейере, когда результат последующей команды формируется раньше предыдущей. При использовании метода переименования регистров значение в регистре-клоне используется в промежуточных вычислениях, пока команда не удалена с конвейера. Команда может быть удалена с конвейера только в том случае, если все предыдущие выполнены и удалены с конвейера при этом предварительно производиться запись из регистра-клона в в программный регистр. Аппаратные издержки от этого конфликта заключаются в том,что приходиться иметь буфер для команд, ожидающих выполнения всех предыдущих и дополнительные схемы контроля за состоянием фаз выполняемых на конвейере команд.
Для устранения конфликтов по управлению используются аппаратные средства блока предсказания переходов. Если при последовательном выполнении команд адрес очередного блока команд, загружаемого из памяти кэш команд или из памяти высшего уровня формируется с опережением то есть увеличением значения текущего адреса команды на величину длины блока команд, уже находящихся в буферных регистрах блока выборки команд, то при конвейерной обработке, чтобы сократить время простоя конвейера из-за конфликтов по управлению, связанных с выполнением команд переходов, адрес очередного блока команд, загружаемого из вышестоящего уровня памяти целесообразней формировать по значению адреса, указанного в команде перехода или следующего за ней на основании информации, собранной о переходах в предыдущих выполненных уже командах управления.
,
Алгоритм Томасуло
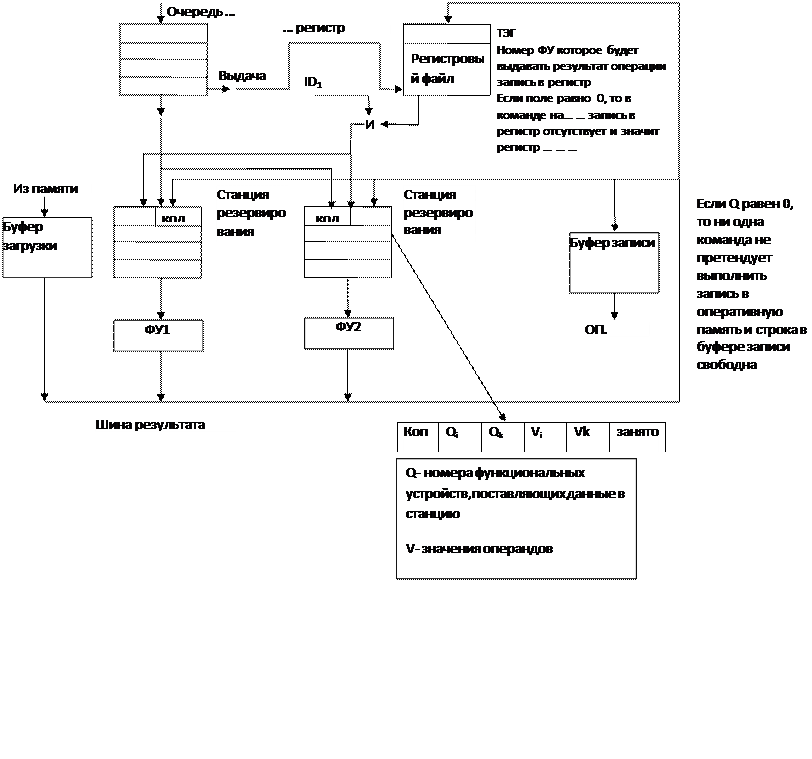
Основной идеей алгоритма Томасуло являлся отказ от централизованного управления функциональными устройствами с точки зрения связи с регистровым файлом на промежуточном этапе выполнения. Отказ от записи промежуточных результатов в регистровый файл т.е. тех, которые будут использованы в следующих командах, следовательно исключить конфликты типа RAW, и WAR, используя для этого во-первых, переименование регистров, во-вторых, станции резервирования.
Станции резервирования представляют ячейки буферной памяти типа FIFO. Для каждого функционального устройства структура каждой станции состоит из информационной части и теговой.
Информационная часть содержит операнды, поступающие на обработку из:
А) регистрового файла
Б)из функционального устройства как и промежуточный результат
В) Из оперативной памяти
Теговая часть каждой строки в буфере памяти содержит 6 полей:
1.) Поле операции
2.) Поля, указывающие станции резервирования, которые будут вырабатывать соответствующие операнды источники, нулевые значения этих полей указывают, что операнды уже находятся в полях значения операндов.
| Поле операнда | Номер станции резервирования | Номер станции резервирования | Значение 1го операнда | Значение второго операнда | Занято |
| Откуда должны подавать первый операнд | Откуда должен поступать второй операнд | ||||
3.) 2 поля операндов источника
4.) Поле занято, указывает, что данная станция резервирования и соответствующее ей устройство заняты.
Регистровый файл и буфер записи имеют поле в котором указано функциональное устройство, которое будет вырабатывать значения для записи в регистр или память. Буфер записи имеют поле для записи значения операнда в память.
Аппаратура, реализующая алгоритм Томасуло, может быть расширена для обеспечения поддержки выполнения по предположению. С этой целью необходимо, как было отмечено выше, ввести фазу фиксации результата и фазу записи результата. Добавление к последовательности выполнения команды фазы фиксации требует сохранение всех команд закончивших выполнение и их результатов до момента пока не сформируется признак, по которому должен быть произведен переход. Вот почему без упорядоченное выполнение команд и механизм предсказания требуют одних и тех же аппаратных средств- дополнительного набора аппаратных буферов, которые хранят результаты команд, закончивших выполнение но еще не записавших результат в память или в регистровый файл.
Каждая теговая строка в буфере содержит 4 поля
1. Поле типа команды
2. Поле места назначения, по которому будет отправлен результат выполнения команды
3. Поле значения
4. Поле состояния команды(микрооперации)
Поле типа команды определяет является ли команда перехода, командой записи в память, или регистровый файл.
Поскольку каждая команда имеет позицию в буфере, до тех пор, пока она не будет зафиксирована и результат не будет отправлен в регистровый файл, результат выполнения команды хранится в строке с той же позицией. Все это время позиция строки, то есть ее адрес,будет являться ссылкой для всех команд, использующих ее результат в свих операциях.
При выполнении по предположению запись в регистровый файл не производится до тех пор пока команда не не получит статус “запись результата”
Большое преимущество схемы Томасуло заключается в распределении логики обнаружения конфликтов и устранение приостановок,связанных с конфликтами WAW и WAR. Это преимущество возникает из-за наличия станций резервирования, которые хранят промежуточные результаты вычислений и общей магистральной шины результата,которая дает возможность одновременной загрузки результата в несколько станций в случае необходимости, таким образом давая возможность поступления нескольких команд, ожидающих этот результат, на выполнение из входной очереди в функциональные устройства в одном такте конвейера при условии,что каждая станция резервирования имеет свою магистраль, связанную с входной очередью. Одновременное начало выполнения команд, ожидающих данные с магистрали результата, в функциональных устройствах возможно и при наличии одной магистрали загрузки команд из входной очереди,если эти команды уже находятся в станциях резервирования функциональных устройств.
Впервые данная схема была предложена Томасуло при проектировании устройства с плавающей точкой. В дальнейшем его идея бала использована во многих архитектурах процессоров и стала базовой при проектировании в них блоков операций. Достаточно для этого привести пример архитектуры процессоров линейки Pentium на основе базовой модели P6. Именно в этой модели были использованы функциональные устройства с использованием станций резервирования, технологии безупорядочного выполнения микроинструкций, переименования регистров и предсказания переходов.
ЛекцияN8
Архитектура современных процессоров.
Анализ архитектуры современных суперскалярных процессоров показывает, что независимо от их аппаратной реализации базируются на общих архитектурных решениях.
1.Современный суперскалярный процессор имеет модифицированную гарвардскую архитектуру с конвейерной организацией выполнения команд.
2. Для устранения конфликтов, возникающих при выполнении команд на конвейере, используются общепринятые меры по их устранению:
- для устранения конфликтов по управлению, связанными с выполнением команд условных переходов в архитектуру процессора введен блок предсказания переходов. Который совместно с другими источниками в процессоре, формирующими адреса инструкций для выборки из кэш инструкций участвует в формировании окончательного значения адреса на приоритетной основе запросов, поступающих в устройство формирования следующего адреса для выборки очередного блока инструкций из кэш от всех источников, формирующих адреса инструкций.
- для устранения конфликтов в процессоре с без упорядочным выполнением используется технология переименования регистров на время выполнения команд в процессоре. Каждому программному регистру, являющимся регистром для записи результата в команде, в регистровом файле назначается группа альтернативных регистров, невидимых системе, в которые записываются промежуточные результаты и эти регистры являются источниками данных для команд, следующими за командами,в которых была проведена операция переименования.
- все современные суперскалярные процессоры имеют распределенную схему управления, которая впервые была предложена и применена для выполнения операций с плавающей точкой в соответствии с алгоритмом Тумасулло. Данная архитектура дает возможность промежуточные результаты,mполученные в одном операционном блоке направлять в случае необходимости в другой операционный блок без записи в регистровый файл или хранить в промежуточном буфере не завершенных команд и производить их запись только при условии выполнения предыдущих команд. Для этого пришлось поток команд на конвейере разбивать на группы и каждую команду сопровождать тегом, указывающим на принадлежность к группе.
|
|
|
|
|
Дата добавления: 2014-01-03; Просмотров: 669; Нарушение авторских прав?; Мы поможем в написании вашей работы!