КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Непрерывные случайные величины
|
|
|
|
(НСВ)
Непрерывной называют случайную величину, возможные значения которой непрерывно занимают некоторый интервал.
Если дискретная величина может быть задана перечнем всех её возможных значений и их вероятностей, то непрерывную случайную величину, возможные значения которой сплошь занимают некоторый интервал (а, b) задать перечнем всех возможных значений невозможно.
Пусть х – действительное число. Вероятность события, состоящего в том, что случайная величина Х примет значение, меньшее х, т.е. вероятность события Х < х, обозначим через F (x). Если х изменяется, то, конечно, изменяется и F (x), т.е. F (x) – функция от х.
Функцией распределения называют функцию F (x), определяющую вероятность того, что случайная величина Х в результате испытания примет значение, меньшее х, т.е.
F (x) = Р (Х < х).
Геометрически это равенство можно истолковать так: F (x) есть вероятность того, что случайная величина примет значение, которое изображается на числовой оси точкой, лежащей левее точки х.
Свойства функции распределения.
10. Значения функции распределения принадлежат отрезку [0; 1]:
0 ≤ F (x) ≤ 1.
20. F (x) – неубывающая функция, т.е.
F (x 2) ≥ F (x 1), если x 2 > x 1.
Следствие 1. Вероятность того, что случайная величина примет значение, заключённое в интервале (а, b), равна приращению функции распределения на этом интервале:
Р (а < X < b) = F (b) − F (a).
Пример. Случайная величина Х задана функцией распределения
F (x) = 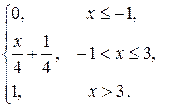
Найти вероятность того, что в результате испытания случайна величина Х примет значение, принадлежащее интервалу (0, 2).
□
Согласно следствию 1, имеем:
Р (0 < X <2) = F (2) − F (0).
Так как на интервале (0, 2), по условию, F (x) = 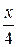 +
+ 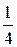 , то
, то
F (2) − F (0) = (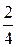 + ) − (
+ ) − (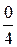 + ) =
+ ) = 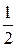 .
.
Таким образом,
Р (0 < X <2) = .
■
Следствие 2. Вероятность того, что непрерывная случайная величина Х примет одно определённое значение, равна нулю.
30. Если возможные значения случайной величины принадлежат интервалу (а, b), то
1). F (x) = 0 при х ≤ а;
2). F (x) = 1 при х ≥ b.
Следствие. Если возможные значения НСВ расположены на всей числовой оси ОХ (−∞, +∞), то справедливы предельные соотношения:
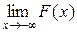 = 0,
= 0, 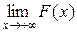 = 1.
= 1.
Рассмотренные свойства позволяют представить общий вид графика функции распределения непрерывной случайной величины:
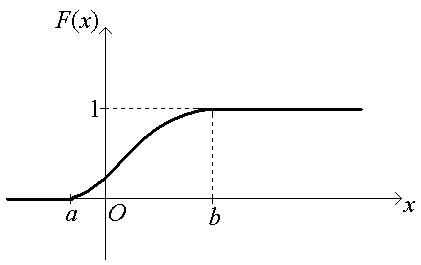
Функцию распределения НСВ Х часто называют интегральной функцией.
Дискретная случайная величина тоже имеет функцию распределения:
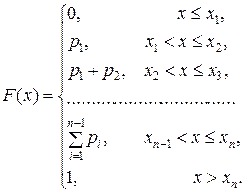
График функции распределения дискретной случайной величины имеет ступенчатый вид.
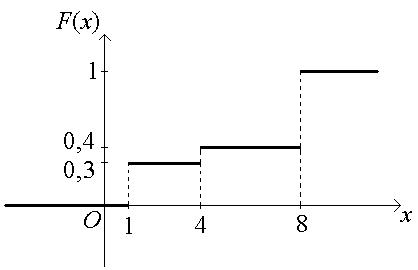
Пример. ДСВ Х задана законом распределения
Х 1 4 8
Р 0,3 0,1 0,6.
Найти её функцию распределения и построить график.
□
Если х ≤ 1, то F (x) = 0.
Если 1 < x ≤ 4, то F (x) = р 1 =0,3.
Если 4 < x ≤ 8, то F (x) = р 1 + р 2 = 0,3 + 0,1 = 0,4.
Если х > 8, то F (x) = 1 (или F (x) = 0,3 + 0,1 + 0,6 = 1).
Итак, функция распределения заданной ДСВ Х:
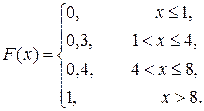
График искомой функции распределения:
■
НСВ можно задать плотностью распределения вероятностей.
Плотностью распределения вероятностей НСВ Х называют функцию f (x) – первую производную от функции распределения F (x):
f (x) = 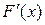 .
.
Функция распределения является первообразной для плотности распределения. Плотность распределения ещё называют: плотность вероятности, дифференциальной функцией.
График плотности распределения называют кривой распределения.
Теорема 1. Вероятность того, что НСВ Х примет значение, принадлежащее интервалу (а, b), равна определённому интегралу от плотности распределения, взятому в пределах от а до b:
Р (а < X < b) = 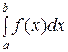 .
.
○ Р (а < X < b) = F (b) − F (a) =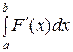 = . ●
= . ●
Геометрический смысл: вероятность того, что НСВ примет значение, принадлежащее интервалу (а, b), равна площади криволинейной трапеции, ограниченной осью ОХ, кривой распределения f (x) и прямыми х = а и х = b.
Пример. Задана плотность вероятности НСВ Х
f (x) = 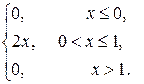
Найти вероятность того, что в результате испытания Х примет значение, принадлежащее интервалу (0,5;1).
□
Имеем
Р (0,5 < X < 1) = 2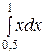 =
= 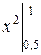 = 1 – 0,25 = 0,75.
= 1 – 0,25 = 0,75.
■
Свойства плотности распределения:
10. Плотность распределения - неотрицательная функция:
f (x) ≥ 0.
20. Несобственный интеграл от плотности распределения в пределах от −∞ до +∞ равен единице:
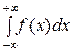 = 1.
= 1.
В частности, если все возможные значения случайной величины принадлежат интервалу (а, b), то
= 1.
Пусть f (x) – плотность распределения, F (х) – функция распределения, тогда
F (х) = 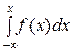 .
.
○ F (x) = Р (Х < х) = Р (−∞ < X < х) =  = , т.е.
= , т.е.
F (х) = . ●
Пример (*). Найти функцию распределения по данной плотности распределения:
f (x) = 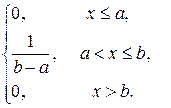
Построить график найденной функции.
□
Известно, что F (х) = .
Если, х ≤ а, то F (х) = = = = 0;
= 0;
Если а < x ≤ b, то F (х) = = +
+ 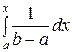 =
= 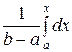 =
= 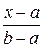 .
.
Если х > b, то F (х) = =+ 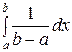 +
+ 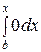 =
= 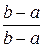 = 1.
= 1.
Итак, функция распределения имеет вид:
F (x) = 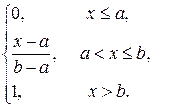
График искомой функции:
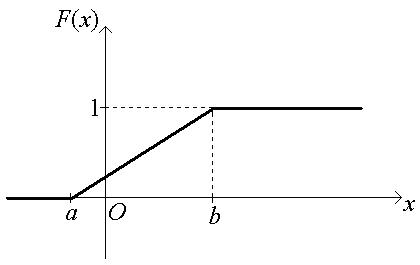
■
Числовые характеристики НСВ
Математическим ожиданием НСВ Х, возможные значения которой принадлежат отрезку [ a, b ], называют определённый интеграл
М (Х) = 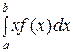 .
.
Если все возможные значения принадлежат всей оси ОХ, то
М (Х) = 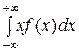 .
.
Предполагается, что несобственный интеграл сходится абсолютно.
Дисперсией НСВ Х называют математическое ожидание квадрата её отклонения.
Если возможные значения Х принадлежат отрезку [ a, b ], то
D (X) = 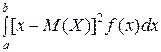 ;
;
Если возможные значения Х принадлежат всей числовой оси (−∞; +∞), то
D (X) = 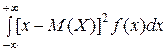 .
.
Легко получить для вычисления дисперсии более удобные формулы:
D (X) = 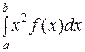 − [ M (X)]2,
− [ M (X)]2,
D (X) = 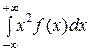 − [ M (X)]2.
− [ M (X)]2.
Среднее квадратическое отклонение НСВ Х определяется равенством
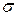 (Х) =
(Х) = 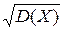 .
.
Замечание. Свойства математического ожидания и дисперсии ДСВ сохраняются и для НСВ Х.
Пример. Найти М (Х) и D (X) случайной величины Х, заданной функцией распределения
F (x) = 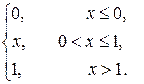
□
Найдём плотность распределения
f (x) = = 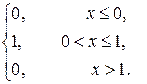
Найдём М (Х):
М (Х) = = 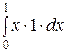 =
= 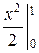 = .
= .
Найдём D (X):
D (X) = − [ M (X)]2 = 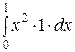 −
− 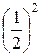 =
= 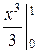 − =
− = 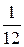 .
.
■
Пример (**). Найти М (Х), D (X) и (X) случайной величины Х, если
f (x) =
□
Найдём М (Х):
М (Х) = = 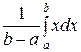 =
=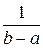 ∙
∙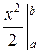 =
= 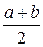 .
.
Найдём D (X):
D (X) =− [ M (X)]2 =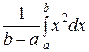 −
− 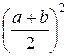 = ∙
= ∙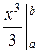 −=
−=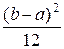 .
.
Найдем (Х):
(Х) = = 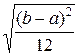 =
= 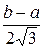 .
.
■
Теоретические моменты НСВ.
Начальный теоретический момент порядка k НСВ Х определяется равенством
νk = 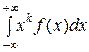 .
.
Центральный теоретический момент порядка k НСВ Х определяется равенством
μk = 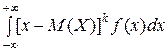 .
.
В частности, если все возможные значения Х принадлежат интервалу (a, b), то
νk = 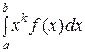 ,
,
μk = 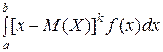 .
.
Очевидно:
при
k = 1: ν 1 = M (X), μ 1 = 0;
k = 2: μ 2 = D (X).
Связь между νk и μk как и у ДСВ:
μ 2 = ν 2 − ν 12;
μ 3 = ν 3 − 3 ν 2 ν 1 + 2 ν 13;
μ 4 = ν 4 − 4 ν 3 ν 1 + 6 ν 2 ν 12 − 3 ν 14.
Законы распределения НСВ
Плотности распределения НСВ называют также законами распределения.
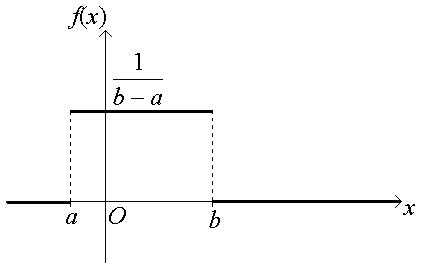
Закон равномерного распределения.
Распределение вероятностей называют равномерным, если на интервале, которому принадлежат все возможные значения случайной величины, плотность распределения сохраняет постоянное значение.
Плотность вероятности равномерного распределения:
f (x) =
Её график:
Из примера (*) следует, что функция распределения равномерного распределения имеет вид:
F (x) =
Её график:
Из примера (**) следуют числовые характеристики равномерного распределения:
М (Х) = , D (X) = , (Х) = .
Пример. Автобусы некоторого маршрута идут строго по расписанию. Интервал движения 5 минут. Найти вероятность того, что пассажир, подошедший к остановке, будет ожидать очередной автобус менее 3-х минут.
□
Случайная величина Х – время ожидания автобуса подошедшим пассажиром. Её возможные значения принадлежат интервалу (0; 5).
Так как Х – равномерно распределённая величина, то плотность вероятности:
f (x) = = 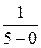 =
= 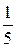 на интервале (0; 5).
на интервале (0; 5).
Чтобы пассажир ожидал очередной автобус менее 3-х минут, он должен подойти к остановке в промежуток времени от 2 до 5 минут до прихода следующего автобуса:
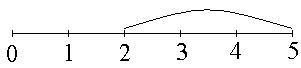
Следовательно,
Р (2 < X < 5) =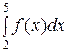 =
= 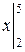 =
= 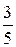 = 0,6.
= 0,6.
■
Закон нормального распределения.
Нормальным называют распределение вероятностей НСВ Х, которое описывается плотностью
f (x) = 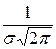
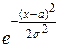 .
.
Нормальное распределение определяется двумя параметрами: а и σ.
Числовые характеристики:
М (Х) == 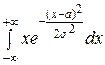 =
= 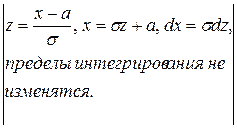 =
=
= 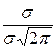
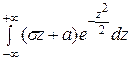 =
= 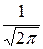
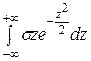 +
+ 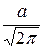
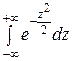 = а,
= а,
т.к. первый интеграл равен нулю (подынтегральная функция нечётная, второй интеграл – это интеграл Пуассона, который равен 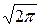 .
.
Таким образом, М (Х) = а, т.е. математическое ожидание нормального распределения равно параметру а.
Учитывая, что М (Х) = а, получим
D (X) = 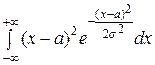 =
= 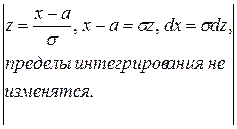 =
=
= 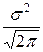
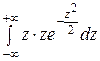 =
= 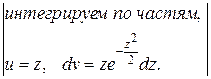 =
= 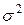 .
.
Таким образом, D (X) = .
Следовательно,
(Х) = = 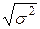 = ,
= ,
т.е. среднее квадратическое отклонение нормального распределения равно параметру .
Общими называют нормальное распределение с произвольными параметрами а и (> 0).
Нормированным называют нормальное распределение с параметрами а = 0 и = 1. Например, если Х – нормальная величина с параметрами а и , то U = 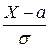 − нормированная нормальная величина, причём М (U) = 0, (U) = 1.
− нормированная нормальная величина, причём М (U) = 0, (U) = 1.
Плотность нормированного распределения:
φ (x) = 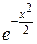 .
.
Функция F (x) общего нормального распределения:
F (x) = 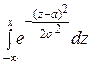 ,
,
а функция нормированного распределения:
F 0(x) = 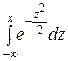 .
.
График плотности нормального распределения называют нормальной кривой (кривой Гаусса):
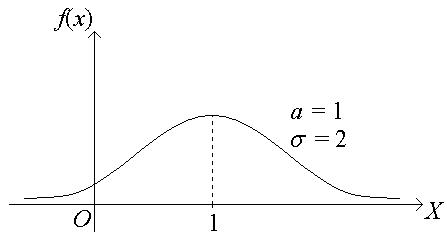
Изменение параметра а ведет к сдвигу кривой вдоль оси ОХ: вправо, если а возрастает, и влево, если а убывает.
Изменение параметра ведет: с возрастанием максимальная ордината нормальной кривой убывает, а сама кривая становится пологой; при убывании нормальная кривая становится более “островершинной” и растягивается в положительном направлении оси OY:
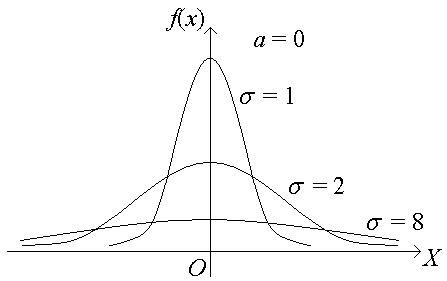
Если а = 0, а = 1, то нормальную кривую
φ (x) =
называют нормированной.
Вероятность попадания в заданный интервал нормальной случайной величины.
Пусть случайная величина Х распределена по нормальному закону. Тогда вероятность того, что Х примет значение из интервала  ), равна
), равна
Р (α < X < β) = 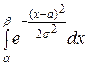 =
= 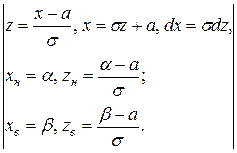 =
=
= 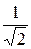
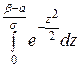 −
− 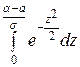 .
.
Используя функцию Лапласа
Φ (х) = 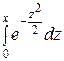 ,
,
Окончательно получим
Р (α < X < β) = Φ (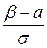 ) − Φ (
) − Φ (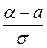 ).
).
Пример. Случайная величина Х распределена по нормальному закону. Математическое ожидание и среднее квадратическое отклонение этой величины соответственно равны 30 и 10. Найти вероятность того, что Х примет значение из интервала 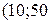 ).
).
□
По условию, α =10, β =50, а =30, =1.
Тогда
Р (10< X < 50) = Φ (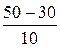 ) − Φ (
) − Φ (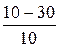 ) = 2 Φ (2).
) = 2 Φ (2).
По таблице: Φ (2) = 0,4772. Отсюда
Р (10< X < 50) = 2∙0,4772 = 0,9544.
■
Часто требуется вычислить вероятность того, что отклонение нормально распределённой случайной величины Х по абсолютной величине меньше заданного δ > 0, т.е. требуется найти вероятность осуществления неравенства | X − a | < δ:
Р (| X − a | < δ) = Р (a − δ < X < a + δ) = Φ (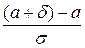 ) − Φ (
) − Φ (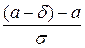 ) =
) =
= Φ (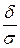 ) − Φ (
) − Φ (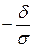 ) = 2 Φ ().
) = 2 Φ ().
В частности, при а = 0:
Р (| X | < δ) = 2 Φ ().
Пример. Случайная величина Х распределена нормально. Математическое ожидание и среднее квадратическое отклонение соответственно равны 20 и 10. Найти вероятность того, что отклонение по абсолютной величине будет меньше 3.
□
По условию, δ = 3, а = 20, =10. Тогда
Р (| X − 20| < 3) = 2 Φ (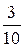 ) = 2 Φ (0,3).
) = 2 Φ (0,3).
По таблице: Φ (0,3) = 0,1179.
Следовательно,
Р (| X − 20| < 3) = 0,2358.
■
Правило трёх сигм.
Известно, что
Р (| X − a | < δ) = 2 Φ ().
Пусть δ = t, тогда
Р (| X − a | < t) = 2 Φ (t).
Если t = 3 и, следовательно, t = 3, то
Р (| X − a | < 3) = 2 Φ (3) = 2∙ 0,49865 = 0,9973,
т.е. получили практически достоверное событие.
Суть правила трёх сигм: если случайная величина распределена нормально, то абсолютная величина её отклонения от математического ожидания не превосходит утроенного среднего квадратического отклонения.
На практике правило трёх сигм применяют так: если распределение изучаемой случайной величины неизвестен, но условие, указанное в приведённом правиле, выполняется, то есть основание предполагать, что изучаемая величина распределена нормально; в противном случае она не распределена нормально.
Центральная предельная теорема Ляпунова.
Если случайная величина Х представляет собой сумму очень большого числа взаимно независимых случайных величин, влияние каждой из которых на всю сумму ничтожно мало, то Х имеет распределение, близкое к нормальному.
Пример. □ Пусть производится измерение некоторой физической величины. Любое измерение дает лишь приближённое значение измеряемой величины, так как на результат измерения влияют очень многие независимые случайные факторы (температура, колебания прибора, влажность и др.). Каждый из этих факторов порождает ничтожную “частную ошибку”. Однако, поскольку число этих факторов очень велико, то их совокупное действие порождает уже заметную “суммарную ошибку”.
Рассматривая суммарную ошибку как сумму очень большого числа взаимно независимых частных ошибок, мы вправе заключить, что суммарная ошибка имеет распределение, близкое к нормальному. Опыт подтверждает справедливость такого заключения. ■
Запишем условия, при которых сумма большого числа независимых слагаемых имеет распределение, близкое к нормальному.
Пусть Х 1, Х 2, …, Хп − последовательность независимых случайных величин, каждая из которых имеет конечные математическое ожидание и дисперсию:
М (Хk) = ak, D (Хk) = 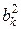 .
.
Введём обозначения:
Sn = 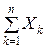 , An =
, An = 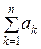 , Bn =
, Bn = 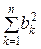 .
.
Обозначим функцию распределения нормированной суммы через
Fп (x) = P (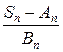 < x).
< x).
Говорят, что к последовательности Х 1, Х 2, …, Хп применима центральная предельная теорема, если при любых х функция распределения нормированной суммы при п → ∞ стремится к нормальной функции распределения:
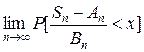 = .
= .
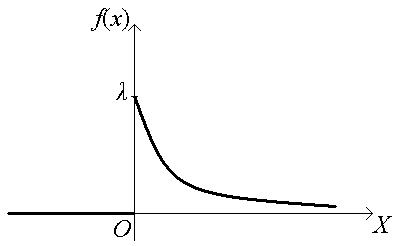
Закон показательного распределения.
Показательным (экспоненциальным) называют распределение вероятностей НСВ Х, которое описывается плотностью
f (x) = 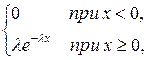
где λ – постоянная положительная величина.
Показательное распределение определяется одним параметром λ.
График функции f (x):
Найдём функцию распределения:
если, х ≤ 0, то F (х) = = == 0;
если х ≥ 0, то F (х) == 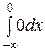 +
+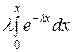 = λ∙
= λ∙ 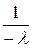
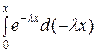 = 1 − е−λх.
= 1 − е−λх.
Итак, функция распределения имеет вид:
F (x) = 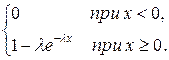
График искомой функции:
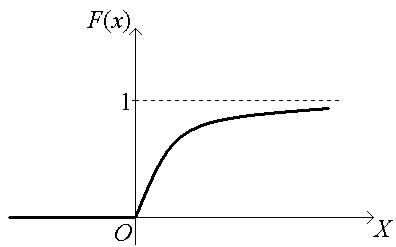
Числовые характеристики:
М (Х) =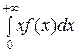 = λ
= λ 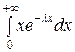 =
=  =
= 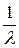 .
.
Итак, М (Х) = .
D (X) =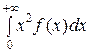 − [ M (X)]2 = λ −
− [ M (X)]2 = λ − 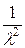 = = .
= = .
Итак, D (X) = .
(Х) = = , т.е. (Х) = .
Получили, что М (Х) = (Х) = .
Пример. НСВ Х распределена по показательному закону
f (x) = 5 е −5 х при х ≥ 0; f (x) = 0 при х < 0.
Найти М (Х), D (X), (Х).
□
По условию, λ = 5. Следовательно,
М (Х) = (Х) = = = 0,2;
D (X) = = 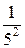 = 0,04.
= 0,04.
■
Вероятность попадания в заданный интервал показательно распределённой случайной величины.
Пусть случайная величина Х распределена по показательному закону. Тогда вероятность того, что Х примет значение из интервала 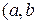 ), равна
), равна
Р (а < X < b) = F (b) − F (a) = (1 − е−λb) − (1 − е−λa) = е−λa − е−λb.
Пример. НСВ Х распределена по показательному закону
f (x) = 2 е −2 х при х ≥ 0; f (x) = 0 при х < 0.
Найти вероятность того, что в результате испытания Х примет значение из интервала 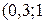 ).
).
□
По условию, λ = 2. Тогда
Р (0,3 < X < 1) = е− 2∙0,3 − е− 2∙1 = 0,54881− 0,13534 ≈ 0,41.
■
Показательное распределение широко применяется в приложениях, в частности в теории надёжности.
Будем называть элементом некоторое устройство независимо от того, “простое” оно или “сложное”.
Пусть элемент начинает работать в момент времени t 0 = 0, а по истечении времени t происходит отказ. Обозначим через Т непрерывную случайную величину – длительность времени безотказной работы элемента. Если элемент проработал безотказно (до наступления отказа) время, меньшее t, то, следовательно, за время длительностью t наступит отказ.
Таким образом, функция распределения F (t) = Р (T < t) определяет вероятность отказа за время длительностью t. Следовательно, вероятность безотказной работы за это же время длительностью t, т.е. вероятность противоположного события T > t, равна
R (t) = Р (T > t) = 1− F (t).
Функцией надёжности R (t) называют функцию, определяющую вероятность безотказной работы элемента за время длительностью t:
R (t) = Р (T > t).
Часто длительность времени безотказной работы элемента имеет показательное распределение, функция распределения которого
F (t) = 1 − е−λt.
Следовательно, функция надёжности в случае показательного распределения времени безотказной работы элемента имеет вид:
R (t) = 1− F (t) = 1− (1 − е−λt) = е−λt.
Показательным законом надёжности называют функцию надёжности, определяемую равенством
R (t) = е−λt,
где λ – интенсивность отказов.
Пример. Время безотказной работы элемента распределено по показательному закону
f (t) = 0,02 е −0,02 t при t ≥0 (t – время).
Найти вероятность того, что элемент проработает безотказно 100 часов.
□
По условию, постоянная интенсивность отказов λ = 0,02. Тогда
R (100) = е− 0,02∙100 = е− 2 = 0,13534.
■
Показательный закон надёжности обладает важным свойством: вероятность безотказной работы элемента на интервале времени длительностью t не зависит от времени предшествующей работы до начала рассматриваемого интервала, а зависит только от длительности времени t (при заданной интенсивности отказов λ).
Другими словами, в случае показательного закона надёжности безотказная работа элемента “в прошлом” не сказывается на величине вероятности его безотказной работы “в ближайшем будущем”.
Указанным свойством обладает только показательное распределение. Поэтому, если на практике изучаемая случайная величина этим свойством обладает, то она распределена по показательному закону.
Закон больших чисел
Неравенство Чебышева.
Вероятность того, что отклонение случайной величины Х от её математического ожидания по абсолютной величине меньше положительного числа ε, не меньше, чем 1 – 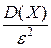 :
:
Р (| X – M (X)| < ε) ≥ 1 – .
Неравенство Чебышева имеет для практики ограниченное значение, поскольку часто дает грубую, а иногда и тривиальную (не представляющую интереса) оценку.
Теоретическое значение неравенства Чебышева весьма велико.
Неравенство Чебышева справедливо для ДСВ и НСВ.
Пример. Устройство состоит из 10 независимо работающих элементов. Вероятность отказа каждого элемента за время Т равна 0,05. С помощью неравенства Чебышева оценить вероятность того, что абсолютная величина разности между числом отказавших элементов и средним числом отказов за время Т окажется меньше двух.
□
Пусть Х – число отказавших элементов за время Т.
Среднее число отказов – это математическое ожидание, т.е. М (Х).
Тогда
М (Х) = пр = 10∙0,05 = 0,5;
D (X) = npq =10∙0,05∙0,95 = 0,475.
Воспользуемся неравенством Чебышева:
Р (| X – M (X)| < ε) ≥ 1 – .
По условию, ε = 2. Тогда
Р (| X – 0,5| < 2) ≥ 1 – 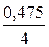 = 0,88,
= 0,88,
т.е.
Р (| X – 0,5| < 2) ≥ 0,88.
■
Теорема Чебышева.
Если Х 1, Х 2, …, Хп – попарно независимые случайные величины, причём дисперсии их равномерно ограничены (не превышают постоянного числа С), то, как бы мало ни было положительное число ε, вероятность неравенства
|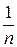
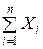 −
− 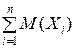 | < ε
| < ε
Будет как угодно близка к единице, если число случайных величин достаточно велико или, другими словами,
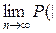 − | < ε) = 1.
− | < ε) = 1.
Таким образом, теорема Чебышева утверждает, что если рассматривается достаточно большое число независимых случайных величин, имеющих ограниченные дисперсии, то почти достоверным можно считать событие, состоящее в том, что отклонение среднего арифметического случайных величин от среднего арифметического их математических ожиданий будет по абсолютной величине сколь угодно малым.
Если М (Х 1) = М (Х 2) = …= М (Хп) = а, то, в условиях теоремы, будет иметь место равенство
− а | < ε) = 1.
Сущность теоремы Чебышева такова: хотя отдельные независимые случайные величины могут принимать значения далёкие от своих математических ожиданий, среднее арифметическое достаточно большого числа случайных величин с большой вероятностью принимает значения близкие к определенному постоянному числу (или к числу а в частном случае). Иными словами, отдельные случайные величины могут иметь значительны разброс, а их среднее арифметическое рассеянно мало.
Таким образом, нельзя уверенно предсказать, какое возможное значение примет каждая из случайных величин, но можно предвидеть, какое значение примет их среднее арифметическое.
Для практики теорема Чебышева имеет неоценимое значение: измерение некоторой физической величины, качества, например, зерна, хлопка и другой продукции и т.д.
Пример. Последовательность случайных величин Х 1, Х 2, …, Хп задана законом распределения
Хп − пα 0 пα
Р 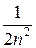 1 −
1 − 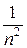
Применима ли к заданной последовательности теорема Чебышева?
□
Для того, чтобы к последовательности случайных величин была применима теорема Чебышева, достаточно, чтобы эти величины: 1. были попарно независимыми; 2). имели конечные математические ожидания; 3). имели равномерно ограниченные дисперсии.
1). Так как случайные величины независимы, то они подавно попарно независимы.
2). М (Хп) = − пα ∙+ 0∙(1 − ) + пα ∙= 0.
Таким образом, каждая случайная величина имеет конечное математическое ожидание.
3). D (Xп) = М (Хп 2) −[ М (Хп)]2. Тогда
Хп 2 п 2 α 2 0 п 2 α 2
Р 1 −
или
Хп 2 п 2 α 2 0
Р 1 −
Тогда
М (Хп 2) = п 2 α 2∙+ 0∙(1 − ) = α 2, D (Xп) = α 2 − 0 = α 2.
Таким образом, дисперсии заданных случайных величин равномерно ограничены числом α 2.
Вывод: теорема Чебышева применима к заданной последовательности случайных величин.
■
Теорема Бернулли.
Если в каждом из п независимых испытаний вероятность р появления события А постоянна, то как угодно близка к единице вероятность того, что отклонение относительной частоты от вероятности р по абсолютной величине будет сколь угодно малым, если число испытаний достаточно велико.
Другими словами, если ε – сколь угодно малое положительное число, то при соблюдении условий теоремы имеет место равенство
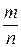 − р | < ε) = 1.
− р | < ε) = 1.
Теорема Бернулли утверждает, что при п → ∞ относительная частота стремится по вероятности к р. Коротко теорему Бернулли можно записать в виде:
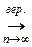 р.
р.
Замечание. Последовательность случайных величин Х 1, Х 2, … сходится по вероятности к случайной величине Х, если для любого сколь угодно малого положительного числа ε вероятность неравенства | Хn – Х | < ε при п → ∞ стремится к единице.
Теорема Бернулли объясняет, почему относительная частота при достаточно большом числе испытаний обладает свойством устойчивости и оправдывает статистическое определение вероятности.
Цепи Маркова
Цепью Маркова называют последовательность испытаний, в каждом из которых появляется только одно из k несовместных событий А 1, А 2,…, Аk полной группы, причём условная вероятность рij (S) того, что в S -м испытании наступит событие Аj (j = 1, 2,…, k), при условии, что в (S – 1)-м испытании наступило событий Аi (i = 1, 2,…, k), не зависит от результатов предшествующих испытаний.
Пример. □ Если последовательность испытаний образует цепь Маркова и полная группа состоит из 4 несовместных событий А 1, А 2, А 3, А 4, причём известно, что в 6-м испытании появилось событие А 2, то условная вероятность того, что 7-м испытании наступит событие А 4, не зависит от того, какие события появились в 1-м, 2-м,…, 5-м испытаниях. ■
Ранее рассмотренные независимые испытания являются частным случаем цепи Маркова. Действительно, если испытания независимы, то появление некоторого определенного события в любом испытании не зависит от результатов ранее произведенных испытаний. Отсюда следует, что понятие цепи Маркова является обобщением понятия независимых испытаний.
Запишем определение цепи Маркова для случайных величин.
Последовательность случайных величин Хt, t = 0, 1, 2, …, называется цепью Маркова с состояниями А = { 1, 2, …, N }, если
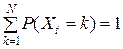 , t = 0, 1, 2, …,
, t = 0, 1, 2, …,
и при любых 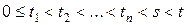 (п = 0, 1, 2, …), любых
(п = 0, 1, 2, …), любых 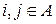 и любых подмножествах
и любых подмножествах 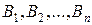 множества А выполняется равенство
множества А выполняется равенство
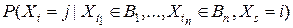 =
= 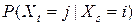 . (1)
. (1)
На практике значения случайных величин Хt интерпретируются как номера состояний изучаемой системы, которая в дискретные моменты времени t (t = 0, 1, 2, …) меняет свое состояние. Свойство (1) означает, что при фиксированном положении системы в данный момент времени s будущее поведение системы 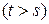 не зависит от поведения системы в прошлом
не зависит от поведения системы в прошлом 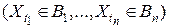 .
.
Свойство (1) называется свойством марковости.
Цепь Маркова Хt называется однородной, если при любых вероятности
= 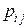 , t = 0, 1, 2, …, (2)
, t = 0, 1, 2, …, (2)
не зависят от t.
Матрицу 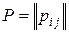 , элементами которой являются вероятности (2), называют матрицей вероятностей перехода, а вектор
, элементами которой являются вероятности (2), называют матрицей вероятностей перехода, а вектор
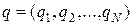 , (3)
, (3)
где 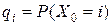 , i = 1, 2, …, N, − вектором начальных вероятностей. Очевидно, что числа и
, i = 1, 2, …, N, − вектором начальных вероятностей. Очевидно, что числа и 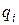 удовлетворяют условиям
удовлетворяют условиям
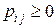 ,
, 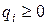 ,
, 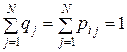 . (4)
. (4)
Матрица вероятностей перехода и вектор начальных вероятностей однозначно определяют совместные распределения величин 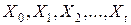 при любом t:
при любом t:
используя теорему умножения вероятностей, (2) и (3), получим
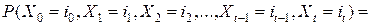
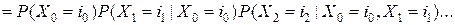
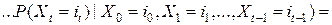
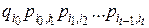 . (5)
. (5)
Для однородной цепи Маркова Хt при любом s выполняется равенство
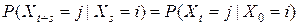 , . (6)
, . (6)
Так как вероятность (6) не зависит от s, то можно положить
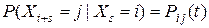 . (7)
. (7)
Функцию 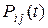 , , называют вероятностями перехода из состояния i в состояние j за время t.
, , называют вероятностями перехода из состояния i в состояние j за время t.
Состояние i цепи Маркова называется несущественным, если существует состояние j и число t 0 такие, что 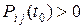 , и
, и 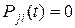 при любом t. В противном случае состояние называется существенным.
при любом t. В противном случае состояние называется существенным.
Кроме вероятностей “сплошных” цепочек исходов (5), часто приходится вычислять вероятности цепочек вида
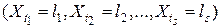 , (8)
, (8)
где моменты времени 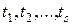 уже не обязательно являются соседними. Вероятность события (8) можно выразить через вероятности перехода . По формуле полной вероятности
уже не обязательно являются соседними. Вероятность события (8) можно выразить через вероятности перехода . По формуле полной вероятности
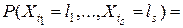
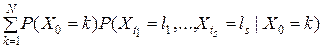 .
.
Преобразуя второй сомножитель под знаком суммы с помощью теоремы умножения вероятностей, (1), (6) и (7), получим
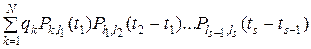 . (9)
. (9)
Для вычислений по формуле (9) нужно уметь находить .
Можно доказать, что при любых s и t справедливо равенство
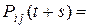
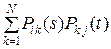 ,
,  . (10)
. (10)
Перейдем к матричной записи. Пусть матрица 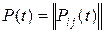 . В матричной записи (10) имеет вид
. В матричной записи (10) имеет вид
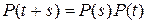 . (11)
. (11)
Так как 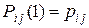 , то
, то 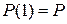 , где P − матрица вероятностей перехода. Из (11) следует
, где P − матрица вероятностей перехода. Из (11) следует
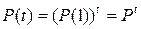 . (12)
. (12)
Результаты, полученные в теории матриц, позволяют по формуле (12) вычислить и исследовать их поведение при 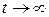 .
.
Если вектор начальных вероятностей при t = 0 записать в виде
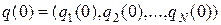 ,
,
то вектор распределения вероятностей в момент времени t запишется в виде
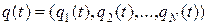 ,
,
который можно определить по формуле
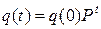 . (13)
. (13)
Распределение вероятностей Хt в произ
|
|
|
|
|
Дата добавления: 2014-10-15; Просмотров: 14834; Нарушение авторских прав?; Мы поможем в написании вашей работы!