КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Билет 6
|
|
|
|
Роль коэффициента Стьюдента в изучении параметров оперативно тактических действий пожарных подразделений. Привести примеры.
Проверять нулевую гипотезу относительно средних  1 и 2 двухвыборок можно, только если соответствующие оценки дисперсий S12 и S22 однородны. Поэтому проверке нулевой гипотезы относительно средних должна предшествовать проверка однородности оценок дисперсий этих выборок.
1 и 2 двухвыборок можно, только если соответствующие оценки дисперсий S12 и S22 однородны. Поэтому проверке нулевой гипотезы относительно средних должна предшествовать проверка однородности оценок дисперсий этих выборок.
Проверка нулевой гипотезы относительно двух выборочных средних 1 и 2 производится следующим образом.
После проверки однородности оценок дисперсий S12 и S22 находят:
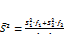 (8.28)
(8.28)
и суммарное число степеней свободы
f = f1 + f2, (8.29)
где f 1 и f 2 - число степеней свободы первой и второй выборок соответственно.
Далее рассчитывают значение величины t расч:
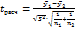 (8.30)
(8.30)
По табл. п 2 Приложения для данного числа степеней свободы f и уровня значимости q находят значение tтабл. Величина t табл показывает, какое наибольшее значение может принять величина tрасч при условии, что нулевая гипотеза о равенстве двух выборочных средних справедлива. Следовательно, если t pасч< t табл, принимают гипотезу о том, что  1 и 2 являются оценками одного и того же генерального среднего (математического ожидания) Му, то есть расхождение между 1 и 2 несущественно (незначимо).
1 и 2 являются оценками одного и того же генерального среднего (математического ожидания) Му, то есть расхождение между 1 и 2 несущественно (незначимо).
Изложенная процедура проверки нулевой гипотезы о двух выборочных средних называется проверкой по t - критерию Стьюдента.
1. Методика построения матрицы дробного многофакторного эксперимента без дублирования опытов для исследования оперативно – тактических действий пожарных подразделений.
Дробные факторные планы (ДФП), как и полные факторные планы (ПФП), предназначены для построения математической модели объекта. При заданном числе факторов ДФП содержат меньшее число опытов по сравнению с ПФП. Но эта экономия достигается ценой упрощения математической модели.
Напомним, что по результатам ПФП 2k можно оценить свободный член в математической модели, все линейные коэффициенты регрессии и все взаимодействия факторов. Однако во многих случаях учёт всех взаимодействий факторов не вызывается необходимостью. Так, при первоначальном изучении объектов широко применяются эксперименты с целью получения линейной модели. Для k варьируемых факторов такая модель имеет следующий вид: (12.1) и содержит (k + 1) коэффициент регрессии
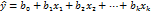 (12.1)
(12.1)
Эксперимент, позволяющий отыскать эти коэффициенты, должен содержать не менее чем (k + 1) опытов. С точки зрения экономии средств, желательно, чтобы число опытов N не слишком превышало эту величину. С этой позиции ПФП при отыскании линейной модели неудовлетворительны. В силу соотношения N = 2k число опытов ПФП существенно превосходит величину (k + 1), начиная уже с трёх факторов. Полные факторные планы неэкономичны, даже если экспериментатора интересуют помимо линейных коэффициентов регрессии некоторые (но не все) взаимодействия факторов.
Пусть, например, по результатам эксперимента с шестью факторами (k = 6) необходимо оценить свободный член, линейные коэффициенты регрессии и парные взаимодействия. Минимально необходимое для этого число опытов равно числу коэффициентов регрессии:
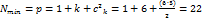 (12.2)
(12.2)
в то время как ПФП 2k шести факторов содержит N = 26 = 64 опыта.
Дробные факторные планы позволяют сократить число опытов по сравнению с ПФП в случае, если в уравнении регрессии можно заранее пренебречь некоторыми взаимодействиями факторов. Для уяснения идеи построения дробных факторных планов обратимся сначала к плану ПФП 22 с двумя факторами (табл. 12.1).
Таблица12.1
Матрица базисных функций ПФП 22 для модели (12.2)
Собственно экспериментальным планом являются только столбцы 3 и 4 табл. 12.1. Столбец х0 добавлен для вычисления коэффициента регрессии b0, а столбец x1х2 - для вычисления коэффициента b12 при произведении факторов x1 и х2. Следует отметить, что полученная матрица базисных функций удовлетворяет трём свойствам - (11.5) - (11.7). По результатам такого эксперимента можно получить модель в виде
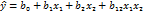 (12.3)
(12.3)
Предположим теперь, что имеется объект с тремя варьируемыми факторами x1, х2, х3, причём целью эксперимента является построение линейной модели, то есть имеются основания пренебречь всеми взаимодействиями факторов. В таком случае можно опять воспользоваться матрицей плана 22 в табл. 12.1. Потребуем, чтобы в этом эксперименте факторы x1 и х2 по-прежнему варьировались в соответствии с элементами столбцов 3 и 4, а фактор х3 варьировался так же как и взаимодействие факторов x1 х2 (столбец 5 табл. 12.1.).
Таким образом, для эксперимента с тремя факторами получен план из четырёх опытов, по результатам которого можно построить линейную модель:
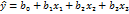 (12.4)
(12.4)
Перепишем матрицу этого плана в табл. 12.2
Таблица12.2
Планы такого типа называются дробными факторными планами (ДФП) или дробными репликами полных факторных планов. В частности, план, приведённый в табл. 12.2, называется полурепликой (или 1/2 реплики) от ПФП 22. Его обозначение 23-1. Здесь 3 - число факторов, а единица вверху символизирует тот факт, что только одно взаимодействие заменяется новым фактором. Именно такие ДФП и называются полурепликами.
В ДФП 23-1фактор х3 варьируется одинаково с парным взаимодействием x1 х2. Поэтому в уравнении регрессии нельзя отделить влияние фактора х3 от влияния взаимодействия x1 х2. Если обозначить через β истинные величины соответствующих коэффициентов регрессии, то можно сказать, что коэффициент β3 даёт совместную оценку двух истинных коэффициентов регрессии β 3 и β12: b3 → β 3 + β12 - это так называемая смешанная оценка.
Если построить столбцы х1 х3 и х2 х 3, то легко убедиться, что они совпадут со столбцами х 2 и х 1 соответственно (рекомендуется проделать это самостоятельно). Следовательно, имеем дополнительно смешанные оценки:
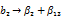 (12.5)
(12.5)
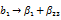 (12.6)
(12.6)
При построении данной полуреплики23-1было использовано соотношение х3 = х1 х2, которое называется генератором плана. Умножим обе его части на х3: х32= х1 х2 х3. Но 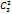 = 1, так как нормализованный фактор х3 в эксперименте равен либо +1, либо -1; следовательно, имеем 1 = х1х2 х 3.
= 1, так как нормализованный фактор х3 в эксперименте равен либо +1, либо -1; следовательно, имеем 1 = х1х2 х 3.
Такое соотношение, в левой части которого стоит 1, а в правой - некоторое произведение факторов, называется определяющим контрастом (ОК) данной реплики. С помощью ОК легко определить систему смешивания оценок, не прибегая к построению дополнительных столбцов. Для этого обе части ОК умножаются поочерёдно на х1 х2 х3. Получим х1= х2 х3. Откуда следует:
(12.7)
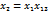 (12.8)
(12.8)
откуда ;
Отметим, что, приравняв х3 = - х1 х2, можно было получить другую полуреплику23-1. А обе эти полуреплики, взятые вместе, составят ПФП 23.
Формулы для расчёта коэффициентов регрессии ПФП остаются полностью справедливыми и для ДФП.
Обратимся к построению дробных факторных планов на основе ПФП 23. Матрица базисных функций этого плана приведена в табл. 12.3.
Таблица 12.3
Матрица базисных функций ПФП 23
Имеется несколько способов построения полуреплики с четырьмя факторами на основе этого плана в зависимости от того, каким из взаимодействий решено пренебречь. Так, пренебрегая тройным взаимодействием х1 х2 х3 и заменив соответствующий столбец фактором х 4, получим следующий план для четырёх факторов (одна из полуреплик24-1, табл. 12.4).
Для этого плана имеем генератор х4= х1х2х3. ОК равен 1 = х1х2х3= х4. Умножая OK последовательно на х1, х2, х3, х1х2, х1х3, х2х3, получаем новые генераторы: х1 = х2х3 х4; х2 = х1 х3 х4; х3 = х1 х2 х4; х1 х2 = х3 х4; х1 х3 = х2 х4; х2 х3 = х1 х4.
В результате имеем следующую систему смешивания оценок:
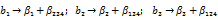
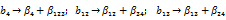
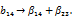
Таблица 12.4
ПФП 24– 1 х4= х1х2х3
В уравнение регрессии, построенное по результатам реализации такого плана, можно включить, кроме линейных членов, все парные взаимодействия, приведённые в плане табл. 12.3:
 (12.9)
(12.9)
Однако надо помнить о системе смешивания. К примеру, коэффициент b12 оценивает не только при β 12, но и β 34.
План в табл. 12.4, используемый для построения модели (12.9), является насыщенным, число опытов в нём N = 8 равно числу оцениваемых коэффициентов регрессии. Поэтому нет возможности проверить адекватность модели. Такую проверку можно сделать, если упростить уравнение (12.9), пренебрегая в нём дополнительно ещё некоторыми взаимодействиями.
Рассмотрим другой вариант полуреплики, приравняв, например, х4 парному взаимодействию х1 х3. Этот план приведён в табл. 12.5.
ОК такой реплики: 1 = х 1 х 3 х 4. Генераторы плана: х 1 = х 3 х 4;
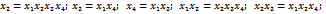
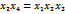
Таблица 12.5
ДФП 24- 1 х4 = х1х3
Система смешивания оценок:
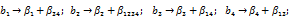
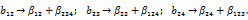
Сравнивая системы смешивания оценок для двух последних планов, можно убедиться в преимуществах плана с OK 1 = x1 х2х3 х4. Для него оценки линейных коэффициентов регрессии смешаны лишь с тройными взаимодействиями, в то время как для плана с OK 1 = x1 х3 х4 некоторые из этих оценок смешаны с парными взаимодействиями. Отсюда следует вывод: с точки зрения системы смешивания оценок, лучше выбирать реплипки, в правой части ОК которых стоит максимальное число членов.
Кроме предложенных вариантов, можно рассмотреть ещё 6 способов построения полуреплик на основе ПФП 23. Их генераторы:
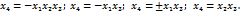
Идею построения ДФП можно развивать дальше, заменяя в планах ПФП не одно, а большее число взаимодействий новыми факторами. При замене двух взаимодействий новыми факторами получим четверть-реплики (или 1/4 реплики) ПФП. Их условное обозначение 2к- 2.
В табл. 12.6 приведён план 1/4 реплики для 5 факторов, полученный заменой в ПФП 23взаимодействий x1 х2 х3 и х2 х3 факторами х4 и х5 соответственно.
Таблица 12.6
ДФП 25 - 2
При замене в ПФП трёх взаимодействий новыми факторами получают 1/8 реплики ПФП, обозначаемые 2к-3 и т. д.
На основе ПФП 23 можно построить дробную реплику, включающую самое большее 7 варьируемых факторов. Это будет план 27 - 4, представляющий собой 1/16 реплики от ПФП 23.
В табл. 12.7 приведён этот план, построенный с помощью следующих генераторов: x4= x1x2; х5 =x1x3; х6 = х2 х3; х7 = x1x2 x3.
С помощью такого плана можно получить линейную модель
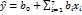 (12,10)
(12,10)
однако нельзя проверить адекватность такой модели, так как план 27-4 является насыщенным.
Насыщенные дробные факторные планы часто используют в качестве планов отсеивающего эксперимента, основная цель которых не построение адекватной модели, а выявление важнейших переменных из числа варьируемых факторов.
Таблица12.7
ДФП27 - 4
2. Понятие истинного значения измеряемой статистической величины и его определение при изучении параметров оперативно – тактических действий.
Сплошное обследование всех элементов генеральной совокупности может потребовать больших затрат средств и времени. По этой причине исследователь всегда имеет дело с выборочной статистической совокупностью, то есть с частью общей генеральной совокупности.
Однако исследователя прежде всего интересуют свойства всей генеральной совокупности. Поэтому одна из важнейших задач математической статистики заключается в определении параметров всей генеральной совокупности на основании информации, которую можно извлечь из ограниченной выборки. Поясним сказанное примером. Пусть нас интересует среднее время развертывания насосно-рукавной системы для забора воды насосной установкой мобильного средства пожаротушения расчетом из двух человек какого либо гарнизона пожарной охраны. Мы, конечно, можем провести прием зачетов от исполнителей в каждом карауле всех пожарных частей этого гарнизона пожарной охраны и таким образом совершенно точно найти среднее время развертывания двумя исполнителями заранее оговоренных условиях – генеральное среднее My.
Однако такое сплошное обследование всей генеральной совокупности потребует больших затрат средств и времени. Поэтому в практике применяют выборочный метод, с помощью этого метода среднее время находят не по всем караулам - всей генеральной совокупности, а по их небольшой части - выборке.
Допустим, для простоты, что весь гарнизон состоит из девяти пожарных частей, которые при развертывания насосно-рукавной системы для забора воды из водоисточника показали следующие результаты 40, 32, 50, 46, 26, 30, 22, 36 и 48 с. Легко подсчитать, что генеральное среднее Му этой статистической совокупности равно 36,6 с.
Проведем теперь выборочное измерение времени выполнения упражнения по трем произвольно взятым группам исполнителей. Для этого выберем какие-либо три результата (например, первые три) и найдем их среднее значение 1:
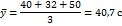
Если бы мы возьмём следующие три измерения - 46, 26, 30, - то получили бы уже другое значение выборочного среднего: 2 = 34,0 с. В первом случае ошибка - разность между выборочным средним и действительным значением среднего времени - равнялась 1 -М у = 40,7- 36,6 = 4,1 с;во втором 2-Му = 34,0 -36,6 = - 2,6 с.
Как видим, определение генерального среднего по выборочному производится с ошибкой. Каждое из возможных выборочных значений 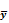 (в качестве обследуемых мы могли взять произвольным образом любые три измерения) находится как среднее арифметическое трех случайных величин. Соответственно выборочное среднее также является случайной величиной. Эта случайная величина в ту или иную сторону отклоняется от истинного среднего значения генеральной совокупности.
(в качестве обследуемых мы могли взять произвольным образом любые три измерения) находится как среднее арифметическое трех случайных величин. Соответственно выборочное среднее также является случайной величиной. Эта случайная величина в ту или иную сторону отклоняется от истинного среднего значения генеральной совокупности.
Точно так же и другие выборочные параметры (например, выборочная дисперсия) являются случайными величинами. Их отклонения от генеральной совокупности случайны. Следовательно, можно указать только вероятность того или иного отклонения и тем самым охарактеризовать численно надежность (достоверность) полученного результата. Вероятность р нахождения истинного значения параметра генеральной совокупности в некоторых пределах называется доверительной вероятностью. Пределы, соответствующие доверительной вероятности, называют доверительными границами, а образуемый ими интервал - доверительным интервалом.
Техника нахождения доверительного интервала для генерального среднего несложна. При выборке объема n< 120 закон распределения ошибки - разности между генеральным и выборочным средним - описывается известной функцией распределения, называемой t -распределением Стьюдента. Используя свойства этого распределения, можно всегда вычислить вероятность отклонения выборочного среднего от генерального на данную величину. Соответственно можно найти и доверительный интервал.
Для расчета доверительного интервала необходимо. Найти выборочное среднее у и оценку дисперсииs2.Задаться уровнем значимости q. Уровнем значимости называют вероятность ошибки, которой допустимо пренебречь в данном исследовании. В нашем случае ошибка будет заключаться в том, что генеральное среднее Му не будет лежать внутри найденного интервала. Поэтому q = 1 -р. Обычно в технологических расчетах величину доверительной вероятности р берут в пределах от 0,9 до 0,99.
Для данного уровня значимости q и числа степеней свободы f = n - 1 из Приложения 4находят величину tqf. Расчет доверительного интервала производится по формуле:
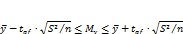 (8.15)
(8.15)
П ример. В результате серии экспериментов из n = 30 испытаний были получены следующие значения: = 28,2 с, S2 = 36. Требуется определить доверительные границы для среднего значения, соответствующие 95%-ной доверительной вероятности.
Решение. Для доверительной вероятности р = 0,95 уровень значимости q = 1 - - 0,95 = 0,05. Число степеней свободы f = 30 - 1 = 29. Из Приложения находим для данных значений q и f значение tqf = 2,04. Подставляя полученные результаты в формулу (8.15), получаем 28,2 - 2,04  1,09 ≤ Мy ≤ 28,2 + 2,04 1,09, или, окончательно, 26,02 ≤ My ≤ 30,42.
1,09 ≤ Мy ≤ 28,2 + 2,04 1,09, или, окончательно, 26,02 ≤ My ≤ 30,42.
Таким образом, с вероятностью 0,95среднее значение заключено между 26,02 с и 30,42 с. То есть из 100 выполненных произвольных экспериментов 95 будут иметь среднее время, лежащее в найденном интервале.
|
|
|
|
|
Дата добавления: 2014-11-25; Просмотров: 788; Нарушение авторских прав?; Мы поможем в написании вашей работы!