КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Реализация типовых задач в MS Excel
|
|
|
|
Для расчета параметров уравнения линейной регрессии и проверки его адекватности исследуемому процессу, Microsoft Excel располагает функцией Регрессия. Для вызова этой функции необходим пакет статистического анализа. Пакет анализа представляет собой надстройку, т.е. программу, которая доступна при установке Microsoft Office или Excel. Чтобы использовать эту надстройку, необходимо сначала загрузить ее. Для этого:
‒ на вкладке Файл выберите элемент Параметры, затем пункт Надстройки;
‒ нажмите кнопку Перейти;
‒ В окне Доступные надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
Для вызова функции Регрессия необходимо выбрать команду меню Данные → Анализ данных. На экране раскроется диалоговое окно Анализ данных, в котором следует выбрать значение Регрессия, в результате чего на экране появится диалоговое окно Регрессия, представленное на рис. 8.
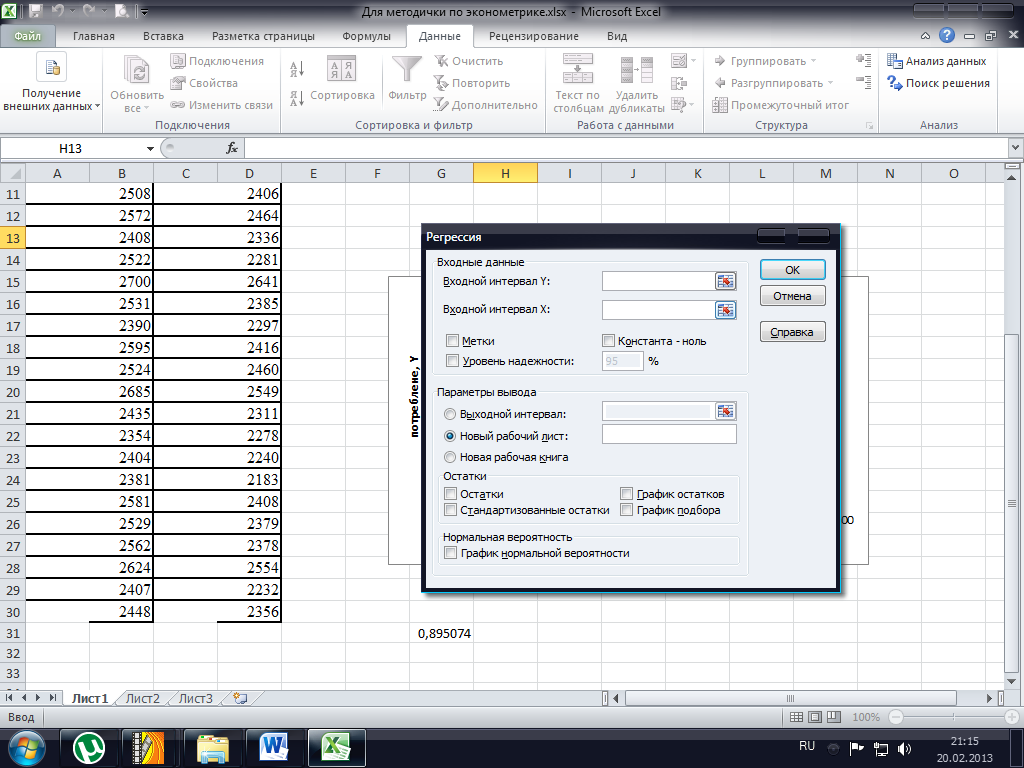
Рис. 8
В диалоговом окне Регрессия задаются следующие параметры.
1. В поле Входной интервал Y вводится диапазон ячеек, содержащих исходные данные по результативному признаку. Диапазон должен состоять из одного столбца.
2. В поле Входной интервал X вводится диапазон ячеек, содержащих исходные данные факторного признака. Максимальное число входных диапазонов (столбцов) равно 16.
3. Флажок Метки устанавливается в том случае, если первая строка во входном диапазоне содержит заголовок. Если заголовок отсутствует, этот флажок следует сбросить. В последнем случае для данных выходного диапазона будут автоматически созданы стандартные названия.
4. Флажок опции Уровень надежности устанавливается в том случае, если в расположенное рядом с флажком поле необходимо ввести уровень надежности, отличный от уровня 95%, применяемого по умолчанию. Установленный в данном поле уровень надежности используется для проверки значимости коэффициента детерминации и коэффициентов регрессии. Если данный флажок сброшен, в таблице параметров уравнения регрессии генерируются две одинаковые пары столбцов для границ доверительных интервалов.
5. Флажок Константа-ноль устанавливается в том случае, когда требуется, чтобы линия регрессии прошла через начало координат (т.е. 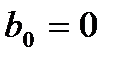 ).
).
6. Переключатель в группе Параметры вывода может быть установлен в одно из трех положений, определяющих, где должны быть размещены результаты расчета: Выходной интервал, Новый рабочий лист или Новая рабочая книга.
7. Флажок опции Остатки устанавливается в том случае, если в диапазон ячеек с выходными данными требуется включить столбец остатков.
8. Флажок опции Стандартизированные остатки устанавливается в том случае, если в диапазон ячеек с выходными данными требуется включить столбец стандартизированных остатков.
9. Флажок опции График остатков должен быть установлен, если на рабочий лист требуется вывести графики зависимости остатков от факторных признаков  .
.
10. Флажок опции График подбора должен быть установлен, если на рабочий лист требуется вывести графики точечные графики зависимости теоретических результативных значений  от факторных признаков .
от факторных признаков .
11. Флажок опции График нормальной вероятности должен быть установлен, если на рабочий лист требуется вывести точечный график зависимости наблюдаемых значений y от автоматически формируемых интервалов персентелей.
Пример. Для исследования зависимости годового объема производства Y от основных фондов X получены данные по 20-ти предприятиям.
| X | 12,5 | 17,5 | 17,5 | 17,5 | 22,5 | 22,5 | 22,5 | 22,5 | 22,5 | 27,5 | 27,5 |
| Y | 20,5 | 21,5 | 21,5 | 22,5 | 22,5 | 22,5 | 23,5 | 23,5 | 23,5 | 23,5 | 23,5 |
| 27,5 | 27,5 | 27,5 | 27,5 | 27,5 | 27,5 | 27,5 | 27,5 | 27,5 |
| 23,5 | 24,5 | 24,5 | 24,5 | 24,5 | 24,5 | 24,5 | 24,5 | 24,5 |
Результаты решения данной задачи с помощью функции Регрессия представлены на рис. 9 ‒ 11.
| ВЫВОД ИТОГОВ | |||
| Регрессионная статистика | |||
| Множественный R | 0,923584 | ||
| R-квадрат | 0,853006 | ||
| Нормированный R-квадрат | 0,84484 | ||
| Стандартная ошибка | 0,47647 | ||
| Наблюдения |
Рис. 9. Результаты расчета: регрессионная статистика
На рис. 8 представлены результаты расчета регрессионной статистики. Эти результаты соответствуют следующим статистическим показателям:
• Множественный R ‒ коэффициент корреляции R;
• R -квадрат ‒ коэффициент детерминации 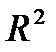 ;
;
• Нормированный R ‒ нормированное значение коэффициента корреляции;
• Стандартная ошибка ‒ стандартное отклонение для остатков;
• Наблюдения ‒ число исходных наблюдений.
На рис. 10 представлены результаты расчета дисперсионного анализа, которые используются для проверки значимости коэффициента детерминации .
| Дисперсионный анализ | ||||||
| df | SS | MS | F | Значимость F | ||
| Регрессия | 23,71358 | 23,71358 | 104,4544 | 6,38E-09 | ||
| Остаток | 4,08642 | 0,227023 | ||||
| Итого | 27,8 |
Рис. 10. Результаты расчета: дисперсионный анализ
Значения в столбцах на рис. 10 имеют следующую интерпретацию.
• Столбец df ‒ число степеней свободы. Для строки Регрессия число степеней свободы определяется количеством факторных признаков m, для строки Остаток ‒ числом наблюдений n и количеством переменных в уравнении регрессии m + 1: n ‒ (m + 1), а для строки Итого ‒ суммой степеней свободы для строк Регрессия и Остаток и, следовательно, равно n ‒ 1.
• Столбец SS ‒ сумма квадратов отклонений. Для строки Регрессия значение определяется как сумма квадратов отклонений расчетных данных от среднего:
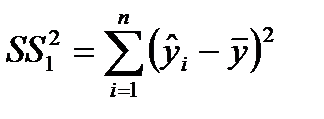 .
.
Для строки Остаток это сумма квадратов отклонений фактических данных от теоретических:
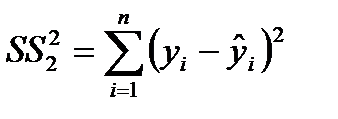 .
.
Для строки Итого это сумма квадратов отклонений расчетных данных от среднего:
 или
или 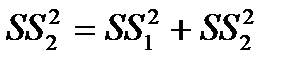 .
.
• Столбец МS содержит значения дисперсии, которые рассчитываются по формуле:
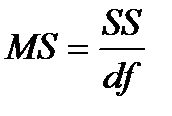 .
.
Для строки Регрессия это факторная дисперсия 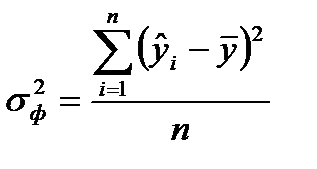 .
.
Для строки Остаток это остаточная дисперсия  .
.
• Столбец F содержит расчетное значение F -критерия Фишера Fр, вычисляемое по формуле:
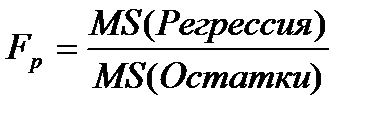 .
.
• Столбец Значимость F содержит значение уровня значимости, соответствующее вычисленному значению Fр.
На рис. 11 представлены полученные значения коэффициентов регрессии 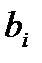 и их статистические оценки.
и их статистические оценки.
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | ||
| Y-пересечение | 17,593 | 0,578 | 30,430 | 6,23E-17 | 16,378 | 18,807 | |
| X | 0,242 | 0,024 | 10,220 | 6,38E-09 | 0,192 | 0,292 | |
Рис. 11. Результаты расчета: коэффициенты уравнения регрессии и их статистические оценки
Столбцы на рис. 11 содержат следующие значения.
• Коэффициенты ‒ значение коэффициентов ;
• Стандартная ошибка ‒ стандартные ошибки коэффициентов ;
• t -статистика ‒ расчетные значения t -критерия, вычисляемые по формуле:
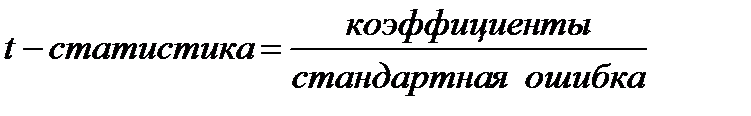 ;
;
• Р -значение ‒ значения уровней значимости, соответствующие вычисленным значениям 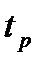 ;
;
• Нижние 95% и Верхние 95% ‒ нижние и верхние границы доверительных интервалов для коэффициентов регрессии .
Переходя к анализу полученных расчетных данных, можно построить уравнение регрессии с вычисленными коэффициентами, которое будет выражать зависимость годового объема производства от основных фондов:
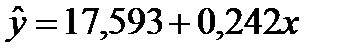 .
.
Выборочный коэффициент детерминации 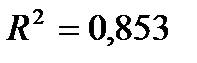 (рис. 9) показывает, что 85,3% разброса зависимой переменной y объясняется построенной регрессией . Рассчитанный уровень значимости (показатель Значимость F рис. 10)
(рис. 9) показывает, что 85,3% разброса зависимой переменной y объясняется построенной регрессией . Рассчитанный уровень значимости (показатель Значимость F рис. 10) 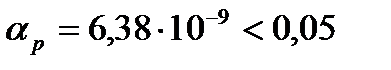 подтверждает статистическую значимость величины
подтверждает статистическую значимость величины 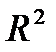 (т.е. гипотеза
(т.е. гипотеза 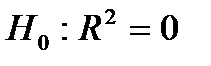 отвергается в пользу
отвергается в пользу 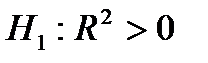 при уровне значимости
при уровне значимости 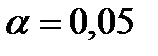 ). В этом случае говорят еще, что уравнение регрессии значимо в целом при
). В этом случае говорят еще, что уравнение регрессии значимо в целом при 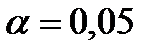 .
.
Следующим этапом является проверка значимости коэффициентов регрессии 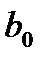 и
и 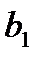 . При парном сравнении коэффициентов и их стандартных ошибок (см. рис. 11) можно сделать вывод, что вычисленные коэффициенты являются статистически значимыми (т.е. гипотезы
. При парном сравнении коэффициентов и их стандартных ошибок (см. рис. 11) можно сделать вывод, что вычисленные коэффициенты являются статистически значимыми (т.е. гипотезы 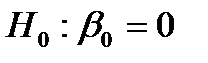 и
и 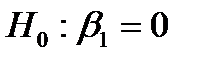 отвергаются). Этот вывод подтверждается величинами Р -значений коэффициентов, которые меньше уровня значимости . Доверительные интервалы с уровнем надежности
отвергаются). Этот вывод подтверждается величинами Р -значений коэффициентов, которые меньше уровня значимости . Доверительные интервалы с уровнем надежности 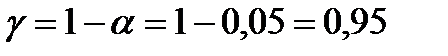 для теоретических коэффициентов
для теоретических коэффициентов 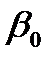 и
и 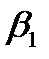 равны соответственно (16,378; 18,807) и (0,192; 0,292). Последнее означает, что, основываясь на выборочных данных, можно утверждать о попадании неизвестных параметров и в указанные интервалы с вероятностью 0,95. Заметим также, что значение 0 не принадлежит никакому из этих интервалов. Откуда можно сделать вывод о том, что гипотезы и отвергаются при уровне значимости , как и было сказано выше.
равны соответственно (16,378; 18,807) и (0,192; 0,292). Последнее означает, что, основываясь на выборочных данных, можно утверждать о попадании неизвестных параметров и в указанные интервалы с вероятностью 0,95. Заметим также, что значение 0 не принадлежит никакому из этих интервалов. Откуда можно сделать вывод о том, что гипотезы и отвергаются при уровне значимости , как и было сказано выше.
Проверка значимости коэффициента детерминации 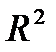 и коэффициентов регрессии и при факторном признаке подтверждает адекватность полученного уравнения.
и коэффициентов регрессии и при факторном признаке подтверждает адекватность полученного уравнения.
Дадим экономическую интерпретацию. Коэффициент регрессии 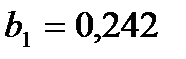 показывает, что при увеличении размера основных фондов на 1 у.е., годовой объем производства возрастает в среднем на 0,242 у.е. Коэффициент регрессии
показывает, что при увеличении размера основных фондов на 1 у.е., годовой объем производства возрастает в среднем на 0,242 у.е. Коэффициент регрессии 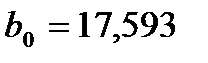 означает, что при нулевом размере основных фондов годовой объем производства ожидается (в среднем) на уровне 17,593 у.е.
означает, что при нулевом размере основных фондов годовой объем производства ожидается (в среднем) на уровне 17,593 у.е.
Замечание. К экономической интерпретации коэффициента 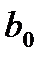 следует относится с известной долей осторожности, сообразуясь со здравым смыслом, поскольку выборочные данные находятся достаточно далеко от нуля. В ряде случаев ограничиваются интерпретацией коэффициента при объясняющей переменной.
следует относится с известной долей осторожности, сообразуясь со здравым смыслом, поскольку выборочные данные находятся достаточно далеко от нуля. В ряде случаев ограничиваются интерпретацией коэффициента при объясняющей переменной.
Дадим точечный и интервальный прогноз среднего размера годового объема производства при размере основных фондов 25 у.е. Подставив в выборочное уравнение регрессии значение x = 25, получим точечный прогноз:
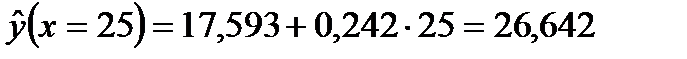 .
.
Таким образом, при размере основных фондов на уровне 25 у.е., годовой объем производства ожидается (в среднем) на уровне 26,642 у.е.
Для построения доверительного интервала для прогнозного среднего значения воспользуемся формулой (1.6):
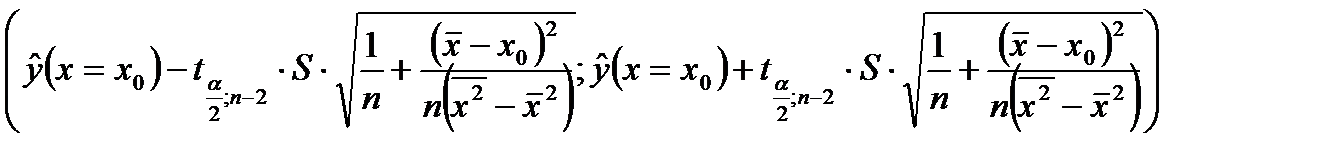 . (1.6)
. (1.6)
Имеем: n = 20; 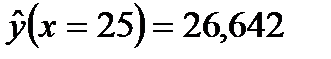 ; S = 0,476 (рис. 8);
; S = 0,476 (рис. 8);  ;
; 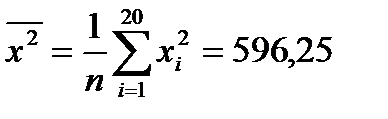 ;
; 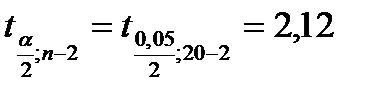 ; (из таблиц критических точек распределения Стьюдента или Excel ‒ fx ‒ статистические ‒ стьюдент.обр.2х). Подставив полученные значения в формулу (1.6), получим 95%-ный доверительный интервал для прогнозного среднего значения результативного признака Y при X = 25: (26,642 ‒ 0,231; 26,642 + 0,231). Откуда находим, что в интервал (26,411; 26,873) среднее значение годового объема производства при размере основных фондов, равным 25 у.е., попадает с вероятностью 0,95 (если ориентироваться на выборочные данные).
; (из таблиц критических точек распределения Стьюдента или Excel ‒ fx ‒ статистические ‒ стьюдент.обр.2х). Подставив полученные значения в формулу (1.6), получим 95%-ный доверительный интервал для прогнозного среднего значения результативного признака Y при X = 25: (26,642 ‒ 0,231; 26,642 + 0,231). Откуда находим, что в интервал (26,411; 26,873) среднее значение годового объема производства при размере основных фондов, равным 25 у.е., попадает с вероятностью 0,95 (если ориентироваться на выборочные данные).
|
|
|
|
|
Дата добавления: 2014-11-20; Просмотров: 1393; Нарушение авторских прав?; Мы поможем в написании вашей работы!