КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Генеральная совокупность и выборка. Оценки параметров
|
|
|
|
Выборочное наблюдение
Статистическое наблюдение можно организовать сплошное и не сплошное. Сплошное наблюдение предусматривает обследование всех единиц изучаемой совокупности (генеральной совокупности). Генеральная совокупность это множество физических или юридических лиц, которую исследователь изучает согласно своей задачи. Это часто экономически невыгодно, а иногда и невозможно. В связи с этим изучается только часть генеральной совокупности – выборочная совокупность.
Результаты, полученные на основе выборочной совокупности, можно распространить на генеральную совокупность, если следовать следующим принципам:
1. Выборочная совокупность должна определяться случайным образом.
2. Число единиц выборочной совокупности должно быть достаточным.
3. Должна обеспечиваться репрезентативность ( представительность) выборки. Репрезентативная выборка представляет собой меньшую по размеру, но точную модель той генеральной совокупности, которую она должна отражать.
Типы выборок
В практике применяются следующие типы выборок:
а) собственно-случайная, б) механическая, в) типическая, г) серийная, д) комбинированная.
Собственно-случайная выборка
При собственно-случайной выборке отбор единиц выборочной совокупности производится случайным образом, например, посредством жеребьевки или генератора случайных чисел.
Выборки бывают повторные и бесповторные. При повторной выборке единица, попавшая в выборку, возвращается и сохраняет равную возможность снова попасть в выборку. При бесповторной выборке единица совокупности, попавшая в выборку, в дальнейшем в выборке не участвует.
Ошибкиприсущие выборочному наблюдению, возникающие в силу того, что выборочная совокупность не полностью воспроизводит генеральную совокупность, называются стандартными ошибками. Они представляют собой среднее квадратичное расхождение между значениями показателей, полученных по выборке, и соответствующими значениями показателей генеральной совокупности.
Расчетные формулы стандартной ошибки при случайном повторном отборе следующая: 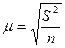 , а при случайном бесповторном отборе следующая:
, а при случайном бесповторном отборе следующая: 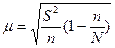 , где S2 – дисперсия выборочной совокупности, n/N – доля выборки, n, N - количества единиц в выборочной и генеральной совокупности. При n = N стандартная ошибка m = 0.
, где S2 – дисперсия выборочной совокупности, n/N – доля выборки, n, N - количества единиц в выборочной и генеральной совокупности. При n = N стандартная ошибка m = 0.
Механическая выборка
При механической выборке генеральная совокупность разбивается на равные интервалы и из каждого интервала случайным образом отбирается по одной единице.
Например, при 2%-ной доли выборки из списка генеральной совокупности отбирается каждая 50-я единица.
Стандартная ошибка механической выборки определяется как ошибка собственно-случайной бесповторной выборки.
Типическая выборка
При типической выборке генеральная совокупность разбивается на однородные типические группы, затем из каждой группы случайным образом производится отбор единиц.
Типической выборкой пользуются в случае неоднородной генеральной совокупности. Типическая выборка дает более точные результаты, потому что обеспечивается репрезентативность.
Например, учителя, как генеральная совокупность, разбиваются на группы по следующим признакам: пол, стаж, квалификация, образование, городские и сельские школы и т.д.
Стандартные ошибки типической выборки определяются как ошибки собственно-случайной выборки, с той лишь разницей, что S2 заменяется средней величиной от внутригрупповых дисперсий.
Серийная выборка
При серийной выборке генеральная совокупность разбивается на отдельные группы (серии), затем случайным образом выбранные группы подвергаются сплошному наблюдению.
Стандартные ошибки серийной выборки определяются как ошибки собственно-случайной выборки, с той лишь разницей, что S2 заменяется средней величиной от межгрупповых дисперсий.
Комбинированная выборка
Комбинированная выборка является комбинацией двух или более типов выборок.
Точечная оценка
Конечной целью выборочного наблюдения является нахождение характеристик генеральной совокупности. Так как этого невозможно сделать непосредственно, то на генеральную совокупность распространяют характеристики выборочной совокупности.
Принципиальная возможность определения средней арифметической генеральной совокупности по данным средней выборки доказывается теоремой Чебышева. При неограниченном увеличении n вероятность того, что отличие выборочной средней 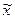 от генеральной средней
от генеральной средней 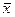 будет сколь угодно мало, стремится к 1.
будет сколь угодно мало, стремится к 1.
Это означает, что характеристика генеральной совокупности 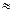 с точностью
с точностью 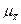 . Такая оценка называется точечной.
. Такая оценка называется точечной.
Интервальная оценка
Базисом интервальной оценки является центральная предельная теорема.
Интервальная оценка позволяет ответить на вопрос: внутри какого интервала и с какой вероятностью находится неизвестное, искомое значение параметра генеральной совокупности?
Обычно говорят о доверительной вероятности p = 1 – a, с которой будет находиться в интервале – D < < + D, где D = tкр m > 0 предельная ошибка выборки, a - уровень значимости (вероятность того, что неравенство будет неверным), tкр - критическое значение, которое зависит от значений n и a. При малой выборке n < 30 tкр задается с помощью критического значения t-распределения Стъюдента для двустороннего критиерия с n – 1 степенями свободы с уровнем значимости a (tкр (n – 1, a) находится из таблицы «Критические значения t–распределения Стъюдента», приложение 2). При n > 30, tкр - это квантиль нормального закона распределения (tкр находится из таблицы значений функции Лапласа F(t) = (1 – a)/2 как аргумент). При p = 0,954 критическое значение tкр = 2 при p = 0,997 критическое значение tкр = 3. Это означает, что предельная ошибка обычно больше стандартной ошибки в 2-3 раза.
Таким образом, суть метода выборки заключается в том, что на основании статистических данных некоторой малой части генеральной совокупности удается найти интервал, в котором с доверительной вероятностью p находится искомая характеристика генеральной совокупности (средняя численность рабочих, средний балл, средняя урожайность, среднее квадратичное отклонение и т.д.).
@ Задача 1. Для определения скорости расчетов с кредиторами предприятий корпорации в коммерческом банке была проведена случайная выборка 100 платежных документов, по которым средний срок перечисления и получения денег оказался равным 22 дням ( = 22) со стандартным отклонением 6 дней (S = 6). С вероятностью p = 0,954 определить предельнуюошибку выборочной средней и доверительный интервал средней продолжительности расчетов предприятий данной корпорации.
Решение: Предельнаяошибка выборочной средней согласно (1) равна D = 2 · 0,6 = 1,2, а доверительный интервал определяется как (22 – 1,2; 22 + 1,2), т.е. (20,8; 23,2).
§6.5 Корреляция и регрессия
Линейный коэффициент корреляции
Корреляционными называются связи, когда между результатом и фактором-признаком нет прямой функциональной зависимости, а воздействие отдельных факторов на результат проявляется лишь в среднем при массовом наблюдении фактических данных.
Например, можно изучить влияние таких факторов-признаков, как разряд рабочих или энерговооруженность на результат – производительность труда.
Линейный коэффициент корреляции определяется как:
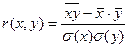 .
.
Линейный коэффициент корреляции меняется в пределах [ – 1; 1].
Линейный коэффициент корреляции является подходящим измерителем зависимости между двумя переменными, так как линейный коэффициент корреляции безразмерная величина.
Линейный коэффициент корреляции показывает степень линейной функциональной зависимости между x и y. Если r = ± 1, то между x и y существует функциональная линейная зависимость. Если r = 0, то x и y не коррелированны.
Вклад фактора x на y результат оценивается с помощью выражения r 2×100%. Считается, что x и y явно связаны, если r 2×100% > 50%.
@ Задача 1: Показать, что коэффициент корреляции для зависимости y от x равняется 1 (данные в таблице соответствуют функции y = 2x + 1).
| x | |||
| y |
Решение: = 2; 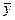 = 5;
= 5; 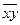 = 34/3;
= 34/3; 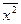 = 14/3;
= 14/3; 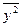 = 83/3;
= 83/3; 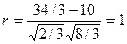 . Что и требовалось доказать.
. Что и требовалось доказать.
Линейное регрессионное уравнение
Регрессионный анализ является одним из основных методов современной математической статистики. Однофакторный регрессионный анализ позволяет найти зависимость между двумя переменными.
Пусть мы имеем n наблюдений (xi, yi, i = 1,2,…n), где xi - значения независимого (факторного) переменного (например, доходы населения), а yi - значения зависимого (результативного) переменного (например, расходы). Графически эти данные задаются n точками в двумерной системе координат YOX (рис. 6.1).
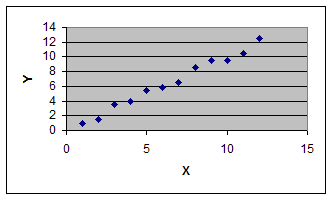
Рис.6.1. Наблюдения (xi, yi)
Нашей задачей является нахождение зависимости y от x по данным (xi, yi), т.е. «подгонка» этих точек какой-то функцией y = f(x).
Простейшая модель зависимости y = f(x) это линейная модель, когда y = a + bx, где a и b неизвестные параметры. Для этой модели задача регрессии решается до конца, а полученные результаты являются базовым для регрессии других, в частности, нелинейных моделей.
В этой модели переменная x детерминированная (без случайных ошибок) величина, а наблюдаемые yi, как правило, отличаются от y = a + bx. Они случайные величины, поэтому выражение для yi пишется в виде yi = a + bxi + e i, где e i - случайные ошибки (отклонения yi от y). Причины возникновения случайных ошибок e i различные: а) так называемый «человеческий фактор»; б) не учет всех факторов; в) неправильный выбор модели и т.д.
Это уравнение называется однофакторным линейным регрессионным уравнением.
Метод наименьших квадратов
Параметры a и b можно найти разными методами, но наилучшим методом является метод наименьших квадратов (МНК). Суть МНК заключается в том, что требуется, чтобы сумма квадратов случайных ошибок была минимальной, чтобы y = f(x) наиболее близко находилась бы к точкам (xi, yi):
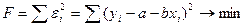 .
.
Решения для a и b называются оценками и определяются через ковариацию x, y и дисперсию x:
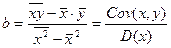 ,
, 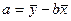 .
.
Поставляя оценки a и b в линейное уравнение, находим регрессию ŷ = a + bx.
Утверждение, что a и b являются наилучшими оценками, а регрессия наилучшей «подгонкой», доказывается теоремой Гаусса-Маркова.
Теорема Гаусса-Маркова. В предположениях модели yi = a + bxi + e i, xi - детерминированная величина, M( e i) = 0, D( e i) = s2, M( e i e j) = 0, i¹j, оценки a и b, полученные методом наименьших квадратов, имеют наименьшую дисперсию в классе всех линейных несмещенных оценок.
@ Задача 1. По данным таблицы найти неизвестные параметры регрессионного уравнения y = a + bx:
| x | ||||
| y |
Решение: n = 4; Σx = 10; Σy = 26; Σxy = 80; Σ x 2 = 30; = 2,5; = 6,5; = 7,5; 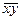 = 20; D(x) = 7,5 – 6,25 = 1,25; b = (20 – 2,5·6,5)/(7,5 – 6,25) = 3; a =6,5 – 2,5·3 = – 1.
= 20; D(x) = 7,5 – 6,25 = 1,25; b = (20 – 2,5·6,5)/(7,5 – 6,25) = 3; a =6,5 – 2,5·3 = – 1.
В итоге получаем: ŷ = – 1 + 3x.
Качество оценки: коэффициент детерминации
После построения уравнения регрессии возникает вопрос о качестве оценки.
|
|
|
|
|
Дата добавления: 2014-12-27; Просмотров: 1281; Нарушение авторских прав?; Мы поможем в написании вашей работы!