КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Тема 18. Пример социологического исследования 1 страница
|
|
|
|
Здесь мы хотим показать целиком ход небольшого условного исследования. Допустим, мы хотим выяснить, существуют ли значимые связи между образованием, доходами, возрастом и другими переменными, и, в конечном счете, построить каузальную модель, о которой шла речь в теме 2 «Понятия ковариации и каузации. Каузальная модель теории».
Ниже приводится анкета, в которой представлены интересующие нас переменные. Далее идет сводная таблица данных, построенная (подчеркнем это) на основе таблицы случайных чисел (см. табл. 18.1).
| Анкета УВАЖАЕМЫЕ СОГРАЖДАНЕ! Приглашаем Вас принять участие в исследовании уровня жизни населения региона. Прочтите вопрос и обведите кружком подходящие для вас варианты ответов. Полученные сведения будут использованы только в обобщенном виде. 1. Укажите, пожалуйста, Ваш возраст 1. 40 лет и моложе 0. Старше 40 2. Ваше образование? 1. Высшее 0. Не высшее 3. Знаете ли Вы иностранные языки? 1. Владею иностранным языком 0. Не владею иностранным языком 4. Сообщите, пожалуйста, уровень Ваших доходов 1. Высокие доходы 0. Невысокие доходы 5. Степень участия в выборах 1. Участвую в каждых выборах 0. Участвую не в каждых выборах 6. Имеете ли дом за городом? 1. Имею 0. Не имею 7. Часто ли совершаете турпоездки за рубеж? 1. Часто 0. Не часто |
Таблица 18.1
Сводная таблица данных
| № анкеты | Возраст | Образование | Знание языков | Уровень доходов | Участие в выборах | Дом за городом | Турпоездки |
| Ответы 1 | |||||||
| Ответы 0 |
|
|
|
Теперь нужно свести результаты опроса в перечневую таблицу (табл. 18.2).
Таблица 18.2
Результаты опроса (перечневая таблица)
| Вопросы и варианты ответов | Абсолютные числа |
| 1. Укажите, пожалуйста, Ваш возраст 1. 40 лет и моложе 0. Старше 40 | |
| 2. Ваше образование? 1. Высшее 0. Не высшее | |
| 3. Знаете ли Вы иностранные языки? 1. Владею иностранным языком 0. Не владею иностранным языком | |
| 4. Сообщите, пожалуйста, уровень Ваших доходов 1. Высокие доходы 0. Не высокие доходы | |
| 5. Частота участия в выборах 1. Участвую в каждых выборах 0. Участвую не в каждых выборах | |
| 6. Имеете ли дом за городом? 1. Имею 0. Не имею | |
| 7. Часто ли совершаете турпоездки за рубеж? 1. Часто 0. Не часто |
|
|
|
Итак, мы получили данные всей совокупности анкет и представили их в единой таблице. Оказывается, респондентов с высокими доходами примерно на 17% больше ((27 – 23): 23 х 100), чем с невысокими доходами, а тех, кто участвует в каждых выборах, на 17% меньше тех, кто участвует не в каждых выборах. Выяснилось также, что на эти же 17% меньше тех, кто не имеет дом за городом. Но зато более или менее поровну разделились респонденты, отвечая на вопросы о возрасте, образовании, знании иностранных языков и частоте турпоездок за рубеж[38]. Таким образом, мы получили представление о картине в целом. На этом этапе обычно заканчивается описательное исследование.
Перейдем к этапу аналитического исследования. Теперь мы должны сравнить различные подгруппы выборки на предмет выяснения между ними связей. Например, можно поставить вопросы: существует ли связь между высокими доходами и частотой участия в выборах или между высокими доходами и наличием дома за городом? И если эти связи есть, то насколько они существенны?
Или, например, проверить, имеется ли связь между возрастом и высокими доходами, частотой участия в выборах или наличием дома за городом? И т. д.
В конечном счете мы должны построить каузальную модель, связывающую переменные между собой.
Так как варианты ответов построены по принципу «либо-либо»: либо высокий доход, либо невысокий; 40 лет и моложе либо старше 40 лет, мы можем для определения связей использовать коэффициент Юла, рассмотренный в теме 15. Напоминаем, как выглядит соответствующая таблица (табл. 18.3).
Таблица 18.3
| Переменная Х | Переменная Y | Всего | |
| Y 1 | Y 2 | ||
| Х 1 | a | b | a + b |
| Х 2 | c | d | c + d |
| Всего | a + c | b + d | a + b + c + d |
|
|
|
В этой таблице соотносятся две переменные X и Y, каждая имеет по два значения: X 1 и X 2 и Y 1 и Y 2. Связь между двумя переменными в этой таблице можно определять через коэффициент Юла:
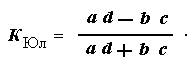
Будем действовать систематически. Сначала проверим наличие связи между возрастом и всеми остальными переменными (табл. 18.4). Она состоит из совокупности подтаблиц, построенных с учетом распределения данных в табл. 18.1.
Таблица 18.4
| Возраст | Образование | Знание языков | Уровень доходов | Участ. в выборах | Дом за городом | Турпоездки | |||||||
| КЮл | 0,067 | –0,24 | 0,17 | –0,006 | –0,006 | –0,07 |
Мы видим, что в таблице отсутствуют более или менее значимые коэффициенты связи, то есть выходящие за рамки ±0,5.
Проверим наличие связи между образованием и оставшимися переменными (см. табл. 18.5).
Таблица 18.5
| Образование | Знание языков | Уровень доходов | Участ. в выборах | Дом за городом | Турпоездки | ||||||
| КЮл | 0,13 | –0,006 | 0,687 | –0,32 | 0,24 |
Здесь мы обнаруживаем, что существуют значимая положительная связь между образованием и участием в выборах (0,687), остальные коэффициенты не являются значимыми.
Проверим наличие связи между знанием иностранных языков и остальными переменными (табл. 18.6).
Таблица 18.6
| Знание языков | Уровень доходов | Участ. в выборах | Дом за городом | Турпоездки | |||||
| КЮл | –0,15 | 0,006 | 0,17 | –0,086 |
В этой таблице отсутствуют коэффициенты, выходящие за пределы ± 0,5 между переменными. Проверим теперь, есть ли связь между уровнем доходов и остальными переменными (табл. 18.7).
|
|
|
Таблица 18.7
| Уровень доходов | Участ. в выборах | Дом за городом | Турпоездки | ||||
| КЮл | 0,09 | 0,75 | 0,69 |
Мы видим, что имеются существенные положительные связи между доходами и наличием домом за городом (0,75), а также между доходами и частотой турпоездок за рубеж (0,69).
Проверим наличие связи между частотой участия в выборах и наличием дома за городом, а также частотой турпоездок за рубеж (табл. 18.8).
Таблица 18.8
| Участ. в выборах | Дом за городом | Турпоездки | |||
| КЮл | 0,38 | 0,46 |
Нет коэффициентов, выходящих за пределы ±0,5. Нам осталось проверить, имеется ли значимая связь между оставшимися двумя переменными: наличие дома за городом и турпоездки за рубеж (табл. 18.9).
Таблица 18.9
| Дом за городом | Турпоездки | ||
| КЮл | 0,17 |
Снова коэффициент не выходит за пределы ±0,5.
Составим список пар переменных, между которыми оказались значимые связи:
1. Высшее образование и более частое участие в выборах, КЮл = 0,687.
2. Высокие доходы и более вероятное наличие дома за городом, КЮл = 0,75.
3. Высокие доходы и чаще турпоездки за рубеж, КЮл = 0,69.
Теперь нужно определиться, что считать в этих парах независимыми переменными, а что – зависимыми переменными.
Ясно, что в первом случае независимой переменной имеет смысл признать образование, потому что обратное предположение выглядело бы странным. Ведь у человека высшее образование имеется не потому, что он чаще участвует в выборах, а вот обратное предположение представляется вполне естественным.
Во втором и третьем случаях естественно будет принять в качестве независимой переменной величину доходов.
Строим каузальную модель (рис. 18.1).
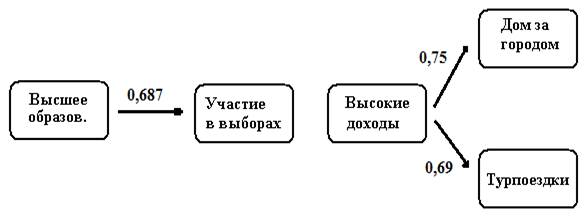
Рис. 18.1. Каузальная модель связей переменных
Получается, что модель состоит из двух самостоятельных частей. Первая показывает, что высшее образование выступает причиной более частого участия в выборах. Вторая часть указывает на то, что высокие доходы есть вероятная причина (или условие) более частых турпоездок зарубеж, а также способствуют тому, чтобы иметь дом за городом.
Конечно, если бы наши данные указывали также и на значимую связь между образованием и доходами, то мы смогли бы получить единую каузальную модель.
Сделаем в порядке эксперимента следующий шаг. Опустим планку значимости коэффициента до ±0,4. Тогда к выше сформулированному списку пар переменных добавим новую пару переменных с коэффициентами связи 0,46. Этой дополнительной парой будет более частое участие в выборах и более частые турпоездки. Наш коэффициент показывает, что между данными параметрами имеется связь, но не указывает, что здесь является причиной, а что следствием, или что является независимой переменной, а что зависимой.
Примем, что знакомство с жизнью в других странах подталкивает наших респондентов к более активному использованию дома своих избирательных прав, это означает, что в качестве независимой переменной мы принимаем частоту турпоездок за рубеж.
В результате получаем более сложную, зато единую каузальную модель (см. рис. 18.2).
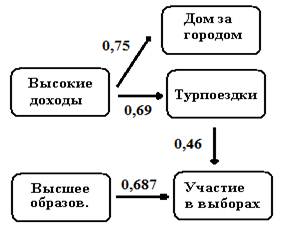
Рис. 18.2. Каузальная модель связей переменных (расширенный вариант)
Попробуем применить к модели понятия ковариация и каузация из темы 2.
Модель показывает, что между высокими доходами и, с одной стороны, наличием дома за городом, а, с другой стороны, частыми турпоездками имеется каузальная связь.
Между наличием дома за городом и частыми турпоездками имеется ковариационная связь.
Между высокими доходами и частотой участия в выборах имеется опосредованная каузальная связь.
Предлагаем читателю найти самостоятельно остальные отношения ковариации и каузации.
Мы видим, что полученная модель показывает не только соотношение между переменными, но с помощью коэффициентов мы можем сравнивать уровень вероятности той или иной связи. Так, у нас получилось, что наиболее высокая связь (0,75) имеется между высокими доходами и наличием дома за городом.
Сделаем следующее замечание. В перечневой таблице, в которую мы свели результаты нашего анкетного «опроса», все переменные приобретают значения, близкие к делению пополам на пополам. Поэтому имело смысл применение коэффициента Юла.
Но вот если бы какая-то переменная разделялась со значительным перекосом, например переменная «частота участия в выборах» принимала бы значения не 23 на 27, а 8 на 42, то в этом случае использование коэффициента Юла было бы, скорее всего, неуместным.
Поясним ситуацию. Допустим, что подтаблица соотношения возраста и участия в выборах имеет вид табл. 18.9:
Таблица 18.9
| Возраст | Участие в выборах | ||
| КЮл | –0,53 |
Формально мы получаем вроде бы вполне значимый коэффициент:
(40 – 132): (40 + 132) = –92: 172 = –0,53.
Но само деление общего числа 50 респондентов в соотношении 8 к 42, при котором меньшая часть, число 8, дробится на еще меньшие части, в нашем примере на 2 и 6, увеличивает вероятность того, что формула даст случайный результат, который поэтому реально не будет значимым.
Здесь надо исходить из правила: чем больше величина числа в наименьшей ячейке, тем более вероятность, что коэффициент будет статистически значимым. В идеале наименьшее число в ячейках должно быть 25–30. С этой точки зрения наше исследование не является надежным, так как в ячейках у нас встречаются числа гораздо меньше 25. Извинением может считаться то, что наше исследование является условным, и задача состояла лишь в том, чтобы показать общий ход действий[39].
И разумеется, если бы переменные принимали больше значений, чем два (или-или), то в этом случае пришлось использовать более сложные коэффициенты, в частности те, которые тоже были рассмотрены нами в теме 15.
Еще одно замечание. Вернемся к табл. 18.4. Рассмотрим ячейки, которые выражают соотношение возраста и участия в выборах, а также возраста и частоты турпоездок. Даже не подсчитывая коэффициенты по формуле, можно определить, что они будут незначительными. Потому что уже «на глаз» видно, что произведения по диагонали в обоих случаях будут близкими по величине, а значит, и разность этих произведений будет близкой к нулю.
Вообще, с нарастанием опыта подсчета коэффициента Юла приходит понимание, в каком случае имеет смысл выяснять его точную величину по формуле, а в каком не имеет смысла это делать, потому что и так ясно, без подсчетов, что коэффициент будет незначимым.
Таблицы
Таблица 1
Таблица случайных чисел
_______________________________________________________________________
| 10097 37542 08422 99019 12807 | 32533 04805 68953 02529 99970 | 76520 64894 19645 09376 80157 | 13586 74296 09303 70715 36147 | 34673 24805 23209 38311 64032 | 54876 24037 02560 31165 36653 | 80959 20636 15953 88676 98951 | 09117 10402 34764 74397 16877 | 39292 00822 35080 04436 12171 | 74945 91665 33606 27659 76833 | ||||
| 66065 31060 85269 63573 73796 | 74717 10805 77602 32135 45753 | 34072 45571 02051 05325 03529 | 76850 82406 65692 47048 64778 | 36697 35303 68665 90553 35808 | 36170 42614 74818 57548 34282 | 65813 86799 73053 28468 60935 | 39885 07439 85247 28709 20344 | 11199 23403 18623 83491 35273 | 29170 09732 88579 25624 88435 | ||||
| 98520 11805 83452 88685 99594 | 17767 05431 99634 40200 67348 | 14905 39808 06288 86507 87517 | 68607 27732 98083 58401 64969 | 22109 50725 13746 36766 91826 | 40558 68248 70078 67951 08928 | 60970 29405 18475 90364 93785 | 93433 24201 40610 76493 61368 | 50500 52775 68711 29609 23478 | 73998 67851 77817 11062 34113 | ||||
| 65481 80124 74350 69916 09893 | 17674 35635 99817 26803 20505 | 17468 17727 77402 66252 14225 | 50950 08015 77214 29148 68514 | 58047 45318 43236 36936 46427 | 76974 22374 00210 87203 56788 | 73039 21115 45521 76621 96297 | 57186 78253 64237 13990 78822 | 40218 14385 96286 94400 54382 | 16544 53763 02655 56418 14598 | ||||
| 91499 80336 44104 12550 63606 | 14523 94598 81949 73742 49329 | 68479 26940 85157 11100 16505 | 27686 36858 47954 02040 34484 | 46162 70297 32979 12860 40219 | 83554 34135 26575 74697 52563 | 94750 53140 57600 96644 43651 | 89923 33340 40881 89439 77082 | 37089 42050 22222 28707 07207 | 20048 82341 06413 25815 31790 | ||||
| 61196 15474 94557 42481 23523 | 90446 45266 28573 16213 78317 | 26457 95270 67897 97344 73208 | 47774 79953 54387 08721 89837 | 51924 59367 54622 16868 68935 | 33729 83848 44431 48767 91416 | 65394 82396 91190 03071 26252 | 59593 10118 42592 12059 29663 | 42582 33211 92927 25701 05522 | 60527 59466 45973 46670 82562 | ||||
| 04493 00549 35963 59808 46058 | 52494 97654 15307 08391 85236 | 75246 64051 26898 45427 01390 | 33824 88159 09354 26842 92286 | 45862 96119 33351 83609 77281 | 51025 63896 35462 49700 44077 | 61962 54692 77974 13021 93910 | 79335 82391 50024 24892 83647 | 65337 23287 90103 78565 70617 | 12472 29529 39333 20106 42941 | ||||
| 32179 69234 19565 45155 94664 | 00597 61406 41430 14938 31994 | 87379 20117 01758 19476 36168 | 25241 45204 75379 07246 10851 | 05567 15956 40419 43667 34888 | 07007 60000 21585 94543 81553 | 86743 18743 66674 59047 01540 | 17157 92423 36806 90033 35456 | 85394 97118 84962 20826 05014 | 11838 96338 85207 69541 51176 | ||||
| 98086 33185 80951 79752 18633 | 24826 16232 00406 49140 32537 | 45240 41941 96382 71961 98145 | 28404 50949 70774 28296 06571 | 44999 89435 20151 69861 31010 | 08896 48581 23387 02591 24674 | 39094 88695 25016 74852 05455 | 73407 41994 25298 20539 61427 | 35441 37548 94624 00387 77938 | 31880 73043 61171 59579 91936 | ||||
| 74029 54178 11664 48324 69074 | 43902 45611 49883 77928 94138 | 77557 80993 52079 31249 87637 | 32270 37143 84827 64710 91976 | 97790 05335 59381 02295 35584 | 17119 12969 71539 36870 04401 | 52527 56127 09973 32307 10518 | 58021 19255 33440 57546 21615 | 80814 36040 88461 15020 01848 | 51748 90324 23356 09994 76938 |
Источник: Мангейм Дж. Б., Рич Р. К. Политология. Методы исследования: пер. с англ.; предисл. А. К. Соколова. М.: Изд–во «Весь Мир», 1997. 544 с. Приложение А. Таблица А.1.
Таблица 2
Размер выборки с доверительным интервалом в 95%
| Размер генеральной совокупности | Ошибка выборки | |||||
| ± 1% | ± 2% | ± 3% | ± 4% | ± 5% | ± 10% | |
| + | + | + | ||||
| 1 000 | + | + | + | |||
| 1 500 | + | + | ||||
| 2 000 | + | + | ||||
| 2 500 | + | 1 250 | ||||
| 3 000 | + | 1 364 | ||||
| 3 500 | + | 1 458 | ||||
| 4 000 | + | 1 538 | ||||
| 4 500 | + | 1 607 | ||||
| 5 000 | + | 1 667 | ||||
| 6 000 | + | 1 765 | ||||
| 7 000 | + | 1 842 | ||||
| 8 000 | + | 1 905 | ||||
| 9 000 | + | 1 957 | ||||
| 10 000 | 5 000 | 2 000 | 1 000 | |||
| 15 000 | 6 000 | 2 143 | 1 034 | |||
| 20 000 | 6 667 | 2 222 | 1 053 | |||
| 25 000 | 7 143 | 2 273 | 1 064 | |||
| 50 000 | 8 333 | 2 381 | 1 087 | |||
| 100 000 | 9 091 | 2 439 | 1 099 | |||
| → ∞ | 10 000 | 2 500 | 1 111 |
|
|
|
|
|
Дата добавления: 2014-12-27; Просмотров: 813; Нарушение авторских прав?; Мы поможем в написании вашей работы!