КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Методика 1. Расчет описательной статистики
Рассмотрим пример анализа рынка образовательных услуг, а именно оплаты за обучение в Вузах города на экономические специальности. Вводим на рабочий лист в Microsoft Excel данные таблицы 1.
Таблица 1
Распределение группы студентов по размеру оплаты за образовательные услуги в регионе
| Стоимость образовательных услуг, тыс.руб. | Средняя стоимость образовательных услуг, тыс.руб. | Количество респондентов | |
| 14-17 | 15,5 | ||
| 17-20 | 18,5 | ||
| 20-23 | 21,5 | ||
| 23-26 | 24,5 | ||
| 26-29 | 27,5 | ||
| 29-32 | 30,5 | ||
| 32-35 | 33,5 |
 1. В меню выбираем: Сервис
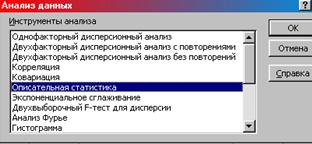
1. В меню выбираем: Сервис 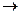 Анализ данных Описательная статистика ОК. Появляется окно «Описательная статистика» (рис. 1, 2).
Анализ данных Описательная статистика ОК. Появляется окно «Описательная статистика» (рис. 1, 2).
Рис. 1. Окно «Анализ данных»
Рис. 2. Окно «Описательная статистика»
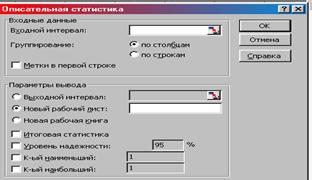
2. В данном окне выбираем команды: Входной интервал – диапазон ячеек со значениями Средняя стоимость образовательных услуг и Количество респондентов (В3:С9); Группировка – по столбцам; Итоговая статистика – активировать, Уровень надежности – активизировать; Уровень надежности – 95%; Выходной интервал – А12; ОК (рис. 3).
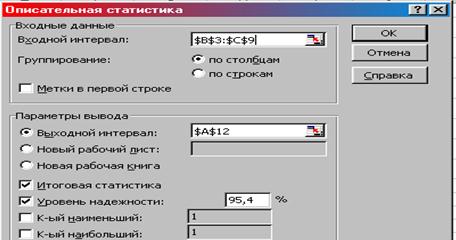 |
Рис. 3. Окно «Описательная статистка» с необходимыми командами.
При появлении окна с сообщением «Выходной интервал накладывается на имеющиеся данные» - ОК.
В результате указанных действий Microsoft Excel осуществляет вывод таблицы описательных статистик (табл. 2).
Таблица 2
Описательная статистика
| Столбец 1 | Столбец 2 | ||
| Среднее | 24,5 | Среднее | 11,42857 |
| Стандартная ошибка | 2,44949 | Стандартная ошибка | 3,524453 |
| Медиана | 24,5 | Медиана | |
| Мода | Мода | ||
| Стандартное отклонение | 6,480741 | Стандартное отклонение | 9,324826 |
| Дисперсия выборки | Дисперсия выборки | 86,95238 | |
| Эксцесс | -1,2 | Эксцесс | -1,36569 |
| Асимметричность | Асимметричность | 0,529414 | |
| Интервал | Интервал | ||
| Минимум | 15,5 | Минимум | |
| Максимум | 33,5 | Максимум | |
| Сумма | 171,5 | Сумма | |
| Счет | Счет | ||
| Уровень надежности(95,4%) | 6,1444 | Уровень надежности(95,4%) | 8,840882 |
Интерпретация терминов таблицы 2 следующая: Среднее – средняя арифметическая величина признака в выборке, вычисленная по несгруппированным данным; Стандартная ошибка – средняя ошибка выборки – среднее квадратическое отклонение выборочной средней от математического ожидания генеральной средней; Медиана – значение признака, приходящееся на середину ранжированного ряда выборочных данных; Мода – значение признака, повторяющееся в выборке с наибольшей частотой; Стандартное отклонение – генеральное среднее квадратическое отклонение, оцененное по выборке; Дисперсия выборки – генеральная дисперсия, оцененная по выборке; Эксцесс – коэффициент эксцесса, оценивающий по выборке значение эксцесса в генеральной совокупности; Ассиметричность – коэффициент ассиметрии, оценивающий по выборке величину ассиметрии в генеральной совокупности; Интервал – размах вариации в выборке; Минимум - минимальное значение признака в выборке; Максимум – максимальное значен ие признака в выборке; Сумма – суммарное значение элементов выборки; Счет – объем выборки; Уровень надежности (95,4%) – предельная ошибка выборки, оцененная с заданным уровнем надежности.
Метод 2. Расчет предельной ошибки выборки при Р=0,997
1. В меню выбираем: Сервис Анализ данных Описательная статистика ОК. Появляется окно «Описательная статистика».
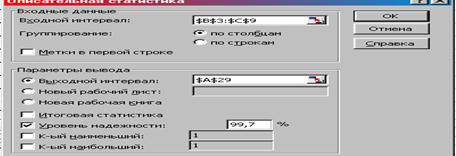 2. В данном окне выбираем команды: Входной интервал – диапазон ячеек со значениями Средняя стоимость образовательных услуг и Количество респондентов (В3:С9); Итоговая статистика – снять флажок, Уровень надежности – активизировать; Уровень надежности – 99,7%; Выходной интервал – А29; ОК (рис. 4).
2. В данном окне выбираем команды: Входной интервал – диапазон ячеек со значениями Средняя стоимость образовательных услуг и Количество респондентов (В3:С9); Итоговая статистика – снять флажок, Уровень надежности – активизировать; Уровень надежности – 99,7%; Выходной интервал – А29; ОК (рис. 4).
Рис. 4. Окно «Описательная статистка» с необходимыми командами
При появлении окна с сообщением «Выходной интервал накладывается на имеющиеся данные» - ОК.
Таблица 3
Предельная ошибка выборки
| Столбец 1 | Столбец 2 | ||
| Уровень надежности(99,7%) | 11,75814 | Уровень надежности(99,7%) | 16,91822 |
Метод 3. Расчет выборочного стандартного отклонения для признака Средняя стоимость образовательных услуг (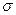 )
)
1. Установить курсор в ячейку В33 для среднего квадратического отклонения первого признака (средней стоимости образовательных услуг, тыс.руб.).
2. Вставка Функция. Открывается окно «Мастер функций шаг 1 из 2» (рис. 5).
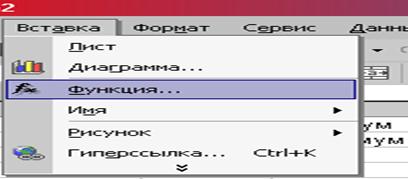 |
Рис. 5. Выбор команды «Функция»
3. Категория Статистические СТАНДОТКЛОНП ОК (рис. 6)
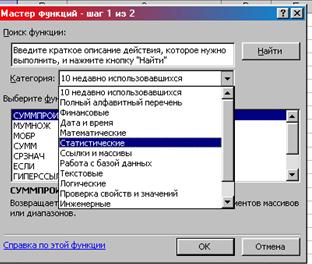 | 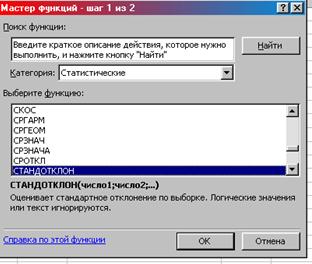 |
Рис. 6. Окно «Мастер функций шаг 1 из 2»
4. Появляется окно «Аргументы функции». Число 1 – диапазон ячеек таблицы 1, содержащих значение первого признака (В2:В9) ОК (рис. 7). В ячейке В 33 выводится значение стандартного отклонения (6,48).
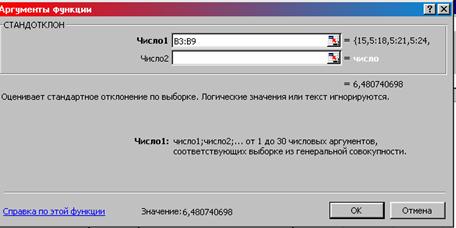 |
Рис. 7. Окно «Аргументы функции»
Метод 4. Расчет выборочной дисперсии для признака Средняя стоимость образовательных услуг ( 2)
1. Установить курсор в ячейку В34 для выборочной дисперсии первого признака (средней стоимости образовательных услуг, тыс.руб.).
2. Вставка Функция. Открывается окно «Мастер функций шаг 1 из 2»
3. Категория Статистические ДИСПР ОК (рис. 8).
4. Появляется окно «Аргументы функции». Число 1 – диапазон ячеек таблицы № 1, содержащих значение первого признака (В2:В9) ОК. В ячейке В 34 выводится значение дисперсии (42).
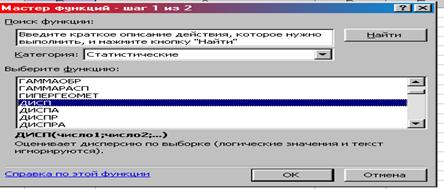 |
Рис. 8. Окно «Мастер функций шаг 1 из 2»
Метод 5. Расчет выборочного среднего линейного отклонения для признака Средняя стоимость образовательных услуг (d)
1. Установить курсор в ячейку В35 для выборочной дисперсии первого признака (средней стоимости образовательных услуг, тыс.руб.).
2. Вставка Функция. Открывается окно «Мастер функций шаг 1 из 2»
3. Категория Статистические СРОТКЛ ОК.
4. Появляется окно «Аргументы функции». Число 1 – диапазон ячеек таблицы № 1, содержащих значение первого признака (В2:В9) ОК. В ячейке В 35 выводится значение дисперсии (5,14).
Метод 6. Расчет коэффициента вариации по признаку Средняя стоимость образовательных услуг (V)
1. Установить курсор в ячейку В36 для выборочной дисперсии первого признака (средней стоимости образовательных услуг, тыс.руб.).
2. В активизированную ячейку ввести формулу = В33 / В 14 * 100. Enter. (рис. 9).
 3. В ячейке В 36 рассчитывается значение коэффициента вариации (26,452).
3. В ячейке В 36 рассчитывается значение коэффициента вариации (26,452).
Рис. 9. Ввод формулы для вычисления коэффициента вариации
Таблица 4
Расчетные значения описательных параметров выборочной совокупности
| Стандартное отклонение | 6,480741 |
| Дисперсия | |
| Среднее линейное отклонение | 5,142857 |
| Коэффициент вариации | 26,452 |
Для вычисления показателей статистики используются следующие формулы:
Мода – представляет собой значение изучаемого признака повторяющееся с наибольшей частотой.
Мода рассчитывается по формуле:
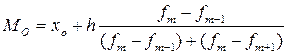 |
где хо – нижняя граница модального интервала; h – величина модального интервала; fm – частота модального интервала; fm-1 – частота интервала, предшествующего модальному; fm+1 – частота интервала, следующего за модальным.
Медиана – значение признака, приходящееся на середину ранжированной совокупности.
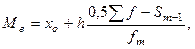 Медиана находится по формуле:
Медиана находится по формуле:
где хо – нижняя граница интервала, который содержит медиану; h – величина медианного интервала; fm – частота медианного интервала; 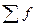 - сумма частот или число членов ряда; Sm-1 – сумма накопленных частот интервалов, предшествующих медианному.
- сумма частот или число членов ряда; Sm-1 – сумма накопленных частот интервалов, предшествующих медианному.
Средняя арифметическая взвешенная рассчитывается по формуле:
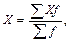 |
где: 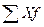 - сумма произведений величин признаков на их частоты; - сумма частот.
- сумма произведений величин признаков на их частоты; - сумма частот.
Размах вариации представляет собой разность между максимальной и минимальной величиной признака.
R = Xmax – Xmin;
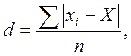 Среднее линейное отклонение представляет собой среднюю из абсолютных значений отклонений отдельных вариантов от их средней, которое рассчитывается по формуле:
Среднее линейное отклонение представляет собой среднюю из абсолютных значений отклонений отдельных вариантов от их средней, которое рассчитывается по формуле:
где хi – значение показателя; Х – среднее арифметическое значение; n – сумма частот.
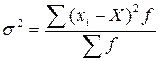 Дисперсия – это средний квадрат отклонений значений признака от их средней величины. Дисперсия находится по формуле:
Дисперсия – это средний квадрат отклонений значений признака от их средней величины. Дисперсия находится по формуле:
Среднеквадратическое отклонение определяется как квадратный корень из дисперсии: 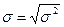
Коэффициент вариации измеряет относительную колеблемость (относительно среднего уровня).
Определяем коэффициент вариации по формуле:
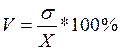 |
Если значение рассчитанного V < 33%, то совокупность по рассчитанному признаку можно считать однородной.
Средняя ошибка выборки маркетинговых исследований показывает среднюю величину всех возможных расхождений выборочной и генеральной средней.
Величина средней квадратической стандартной ошибки простой случайной повторной выборки определяется по формуле:
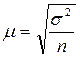
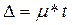 Предельная ошибка выборки характеризуется наибольшим расхождением между характеристиками генеральной и выборочной совокупности рассчитывается по формуле:
Предельная ошибка выборки характеризуется наибольшим расхождением между характеристиками генеральной и выборочной совокупности рассчитывается по формуле:
где t – коэффициент доверия, зависящий от вероятности, с которой гарантируется предельная ошибка выборки. Ф (t) = Р/2 = 0,95 / 2 = 0,475, т.е. по таблице Лапласа t = 1,96.
|
|
Дата добавления: 2014-12-26; Просмотров: 1502; Нарушение авторских прав?; Мы поможем в написании вашей работы!