КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Технология оценки тесноты связи исследуемых признаков на основе линейного коэффициента корреляции
|
|
|
|
1. Сервис – Анализ данных – Корреляция – ОК. Появляется окно «Корреляция» (рис. 14).
2. Входной интервал – диапазон ячеек таблицы со значениями признака У (В3:В7).
3. Входной интервал Х – диапазон ячеек таблицы со значениями факторного и результативного признаков (А3:В7).
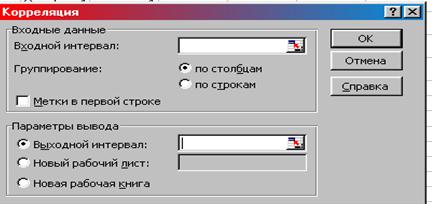 |
Рис. 14. Окно «Корреляция»
4. Группирование – по столбцам;
5. Метки в первой строке – не активизировать.
6. Выходной интервал – ячейка с параметрами D3.
7. 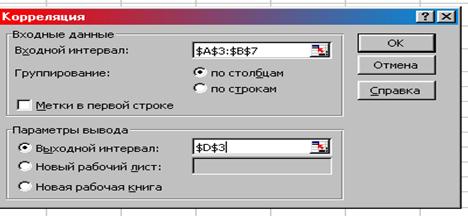 Новый рабочий лист / Новая рабочая книга – не активизировать (рис. 15) ОК.
Новый рабочий лист / Новая рабочая книга – не активизировать (рис. 15) ОК.
Рис. 15. Окно «Корреляция» с заданными параметрами
В результате работы алгоритма Excel выдает оценку тесноты связи факторного и результативного признаков (табл. 10).
Таблица 10
Значение линейного коэффициента корреляции
| Столбец 1 | Столбец 2 | |
| Столбец 1 | ||
| Столбец 2 | 0,912292 |
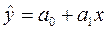 Математический аппарат корреляционного и регрессионного анализа. Простым линейным уравнением регрессии является выражение:
Математический аппарат корреляционного и регрессионного анализа. Простым линейным уравнением регрессии является выражение:
где  - теоретические расчетные значения результативного признака, полученные по уравнению регрессии; а0, а1 – независимые параметры уравнения регрессии:
- теоретические расчетные значения результативного признака, полученные по уравнению регрессии; а0, а1 – независимые параметры уравнения регрессии:
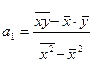 ;
; 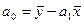 .
.
Теснота корреляционной связи между переменными х и у, которая измеряется эмпирическим корреляционным отношением 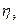 , когда
, когда 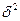 (межгрупповая дисперсия) характеризует отклонения групповых средних результативного признака от общей дисперсии:
(межгрупповая дисперсия) характеризует отклонения групповых средних результативного признака от общей дисперсии:
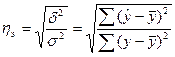
Подкоренное выражение корреляционного отношения представляет собой коэффициент детерминации (меры определенности, причинности).
Коэффициент детерминации показывает долю вариации результативного признака под влиянием вариации признака-фактора.
Кроме того, при линейной форме уравнения применяется другой показатель тесноты связи – линейный коэффициент корреляции, который находится по формуле:

Значение линейного коэффициента корреляции важно для исследования социально-экономических явлений и процессов, распределение которых близко к нормальному. Он принимает значение в интервале: - 1 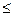 r 1.
r 1.
Отрицательное значение указывает на обратную связь, положительное на прямую. При r = 0 линейная связь отсутствует. Чем ближе коэффициент корреляции по абсолютной величине к единице, тем теснее связь между признаками. При r = 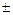 1 связь функциональная.
1 связь функциональная.
Для оценки значимости коэффициента корреляции r используют t-критерий Стьюдента, который применяется при t – распределении, отличном от нормального.
t-критерий рассчитывается по формуле:
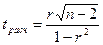
где (n-2) – число степеней свободы при заданном уровне значимости 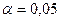 и объеме выборки n.
и объеме выборки n.
Рассмотрим следующийконкретный пример анализа маркетинговой информации. Проведем обработку результатов маркетинговых исследований с построением модели для предсказания объема реализации одного из продуктов фирмы.
Примем обозначения. Объем выпуска, шт. - это зависимая переменная Y.В качестве независимых, объясняющих переменных выбраны: затраты на рекламу, тыс. руб. -Х 1; цена, тыс.руб.- Х2; суммарные расходы потребителя, тыс. руб.-Х3; численность персонала, чел – Х4. Построим систему показателей (факторов) и проанализируем матрицу коэффициентов парной корреляции. Статистические данные по всем переменным приведены в табл. 11.
В этом примере число статистических уровней n =7, число независимых факторов m = 4.
Таблица 11
Исходные статистические данные
| Года | Объем выпуска, шт. | Затраты на рекламы, тыс. руб. | Цена, тыс.руб. | Суммарные расходы потребителя, тыс. руб. | Численность персонала, чел. |
| Y | X1 | X2 | X3 | Х  4 4
| |
| 125 000 | 43 300 | 17 700 | |||
| 8 000 | 159 700 | 51 700 | 20 900 | 1 000 | |
| 179 749 | 54 500 | 25 400 | 1 027 | ||
| 200 157 | 56 000 | 27 100 | 1 077 | ||
| 220 565 | 60 100 | 30 500 | 1 127 | ||
| 227 456 | 64 500 | 35 000 | 1 170 | ||
| 300 000 | 68 700 | 37 500 | 1 215 |
Для проведения корреляционного анализа выполним следующие действия: данные для корреляционного анализа должны располагаться в смежных диапазонах ячеек; выбрать команду Сервис =>Анализ данных. В диалоговом окне Анализ данных выбрать инструмент Корреляция (рис. 16), а затем щелкнуть на кнопке ОК:
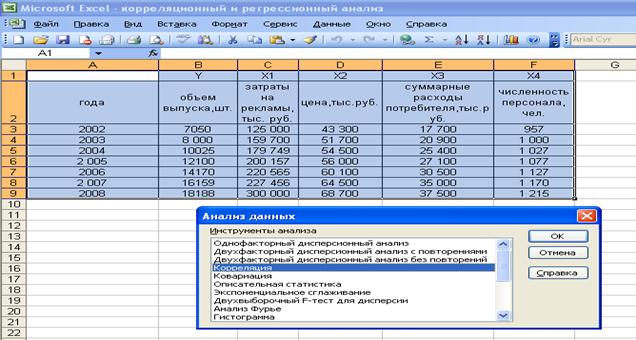
Рис. 16. Выбор инструмента корреляция
В диалоговом окне Корреляция в поле «Входной интервал» необходимо ввести диапазон ячеек, содержащих исходные данные. Если выделены и заголовки столбцов, то установить флажок «Метки в первой строке» (рис. 17); выбрать параметры вывода. В данном примере установить переключатель «Новый рабочий лист»; нажать ОК.

Рис. 17. Диалоговое окно корреляция подготовлено к выполнению
анализа данных
В итоге компьютер напечатает на экране матрицу коэффициентов парной корреляции, которая отражает тесноту связи между показателями (рис. 18).
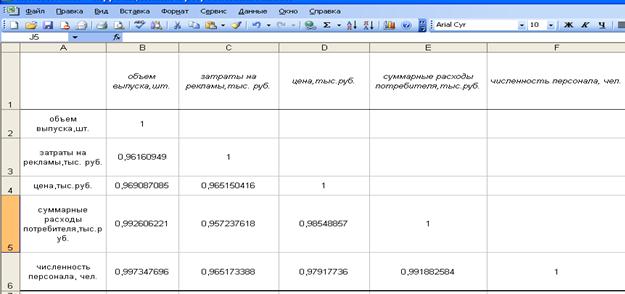
Рис. 18. Матрица коэффициентов парной корреляции
Анализ матрицы коэффициентов парной корреляции, показывает, что зависимая переменная, т.е. объем выпуска, имеет сильную связь с численностью персонала (ryx 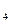 = 0,997); с суммарными расходами потребителя (ryx
= 0,997); с суммарными расходами потребителя (ryx 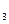 = 0,992); с ценой (ryx
= 0,992); с ценой (ryx 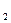 = 0, 969); с затратами на рекламу (ryx
= 0, 969); с затратами на рекламу (ryx 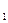 = 0,962).
= 0,962).
Одним из условий регрессионной модели является предположение о линейной независимости объясняющих переменных, т.е. решение задачи возможно лишь тогда, когда столбцы и строки матрицы исходных данных линейно независимы. Для экономических показателей это условие выполняется не всегда. Линейная или близкая к ней связь между факторами называется мулътиколлинеарностьюи приводит к линейной зависимости нормальных уравнений, что делает вычисление параметров либо невозможным, либо затрудняет содержательную интерпретацию параметров модели. Считают явление мультиколлинеарности в исходных данных установленным, если коэффициент парной корреляции между двумя переменными больше 0.8. В нашем примере факторы X3 и X4 тесно связаны между собой (rх3x4 = 0,979), что свидетельствует о наличии мультиколлинеарности. Чтобы избавиться от мультиколлинеарности, в модель включим лишь один из линейно связанных между собой факторов, причем тот, который в большей степени связан с зависимой переменной.- X4. После исключения факторов Х1,X2 ,X3 получим n= 4, k = 1.
Для проведения регрессионного анализа выполняются следующие действия: выбрать команду Сервис =>Анализ данных; в диалоговом окне Анализ данных выбрать инструмент Регрессия (рис. 19), а затем щелкнуть на кнопке Ок;
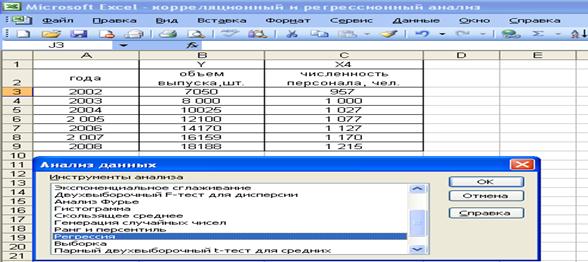
Рис. 19. Диалоговое окно анализ данных
Далее:
1) в диалоговом окне Регрессия в поле «Входной интервал Y» вводится адрес диапазона ячеек, который представляет зависимую переменную. В поле «Входной интервал Х» вводится адрес диапазона ячеек, который содержит значения независимой переменной (рис. 20);
2) установить флажок Метки в первой строке, т.к. мы выделяем заголовки столбцов.
3) Выбрать параметры вывода. В данном примере – установить переключатель «Новая рабочая книга».
4) В поле «Остатки» поставить необходимые флажки и нажать Ок.
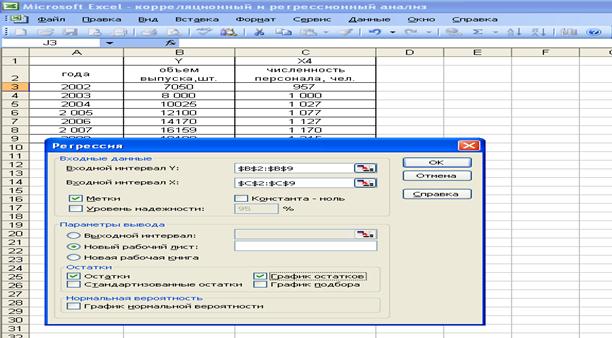
Рис. 20. Диалоговое окно Регрессия подготовлено к выполнению анализа данных
Проведемоценку качества и адекватности построенной модели (табл. 12).
Таблица 12
| Вывод итогов | |
| Регрессионная статистика | |
| Множественный R | 0,997347696 |
| R-квадрат | 0,994702427 |
| Нормированный R-квадрат | 0,993642912 |
| Стандартная ошибка | 332,4291594 |
| Наблюдения |
Пояснения к таблице 12.
| Регрессионная статистика | |||
| № | Наименование в отчете EXCEL | Принятые наименования | Формула |
| Множественный R | Коэффициент множественной корреляции, индекс корреляции |
R = 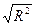
| |
| R-квадрат | Коэффициент детерминации, R2 | R2 = 1- 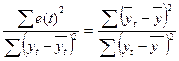
| |
| Нормированный R-квадрат | Скорректированный R2 | R2 = 1- (1- R2 ) 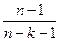
| |
| Стандартная ошибка | Стандартная ошибка оценки | Se = 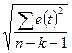
| |
| Наблюдения | Количество наблюдений,n | n |
Коэффициент парной корреляции (множественный R) показывает, что зависимость наблюдениями в выборке положительная, т.е. с увеличением численности персонала произойдет рост объема выпуска. Коэффициент детерминации, R2 =0,994702427, означает, что не менее 99,4% вариации объема выпуска (т.е. доли его изменения) объясняется вариацией численности персонала. Следовательно, численность персонала является весомым фактором, способным помочь в прогнозировании объема. Нормированный R2 показывает, насколько добавление новой переменной может улучшить качество товаров, однако в качестве диагностической величины с целью экономии трудозатрат этот фактор используется крайне редко потому, что при увеличении количества переменных и числа наблюдений его значение не всегда может меняться в сторону повышения. Стандартная ошибка дает лишь общую оценку степени точности коэффициента регрессии, но она не несет информации о том, где находится полученное отклонение: в конце или середине распределения, и поэтому, относительно неточна.
Дальнейший анализ используется для определения значимости совместного вклада группы переменных (табл. 13).
Таблица 13
Расчетная таблица
| Дисперсионный анализ | |||||
| df | SS | MS | F | Значимость F | |
| Регрессия | 103749123,7 | 103749123,7 | 938,8283903 | 6,94856E-07 | |
| Остаток | 552545,7302 | 110509,146 | |||
| Итого | 104301669,4 |
Пояснения к таблице 13:
| Показатели | Df- число степеней свободы | SS- сумма квадратов | MS | F- критерий Фишера |
| Регрессия | k=1 | 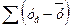 2 2
| 2 / k
| F= 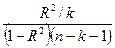
|
| Остаток | n-k-1=5 | 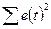
| 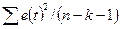
| |
| Итого | n-1=6 | 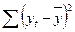
|
Для проверки значимости модели регрессии используется F- критерий Фишера. Расчетное значение F сравнивается с табличным Fтабл. Значение величины Fтабл с 1 и 5 степенями свободы (Df), при α = 0,05, равно 6,61.
F= 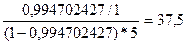 .
.
Так как F> Fтабл., то уравнение модели признается значимым.
В таблице 14содержится информация для построения зависимости общего объема выпуска от численности персонала, причем во втором столбце содержатся коэффициенты уравнения регрессии а0, и а1. В третьем столбце содержатся стандартные ошибки коэффициентов уравнения регрессии, а в четвертом - t-статистика используемая для проверки значимости коэффициентов уравнения регрессии и представляющая собой оценку коэффициента, деленную на ее стандартную ошибку.
Таблица 14
Таблица построения регрессии
| Параметры | Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | Нижние 95,0% | Верхние 95,0% |
| Y-пересечение | -35688,73138 | 1569,331 | -22,74135 | 3,0568E-06 | -39722,82738 | -31654,6 | -39722,8 | -31654,63 |
| Х - численность персонала, чел. | 44,3038584 | 1,445933 | 30,64030 | 6,94856E-07 | 40,58696 | 48,020 | 40,5869 | 48,02074 |
Линейное уравнение регрессии зависимости общего объема выпуска Y от численности персонала Х 1, полученное с помощью EXCEL, имеет вид:
Y = -35688,73138+44,3038584 Х1
Расчетные значения Y определяются путём последовательной подстановки в эту модель значений факторов X1, взятых для каждого момента времени t. Оценить качество модели, проследить степень ее точности, помогут вычисленные отклонения и предсказанные значения исследуемой переменной Y (таблица 15)
Таблица 15
Вычисленные по модели значения Y и значения остаточной компоненты
| Вывод остатка | ||
| Наблюдение | Предсказанный объем выпуска, шт. | Остатки |
| 6710,061108 | 339,9388916 | |
| 8615,12702 | -615,1270196 | |
| 9811,331196 | 213,6688036 | |
| 12026,52412 | 73,47588365 | |
| 14241,71704 | -71,71703631 | |
| 16146,78295 | 12,21705252 | |
| 18140,45658 | 47,54342456 |
Качество модели оценивается стандартным для математических моделей образом, по адекватности на основе анализа остатков регрессии. Анализ остатков позволяет получить представление, насколько хорошо подобрана сама модель и насколько правильно выбран метод оценки коэффициентов.
Независимость остатков проверяется с помощью критерия Дарбина-Уотсона.
d= 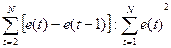
Расчет коэффициента Дарбина – Уотсона приведен на рис. 21.

Рис. 21. Расчет коэффициента Дарбина – Уотсона
Если d >2, то возникает предположение об отрицательной автокорреляции в остатках и тогда с критическими значениями сравнивается не d, а 4- d и делаются аналогичные выводы. В нашем случае значение d =2,63, т.е. можно предположить отрицательную автокорреляцию в остатках.
Построим график остатков с добавление тренда на 2 периода вперед (рис. 22). Анализ остатковпозволяет получить представление, насколько хорошо подобрана сама модель и насколько правильно выбран метод оценки коэффициентов. График остатковпоказывает, что отклонений от модели наблюдения нет.
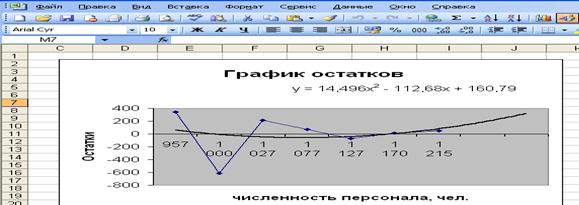
Рис. 22. График остатков
Для наглядного сравнения истинных и предсказанных по модели величин необходимо построить график подбора (рис. 23).
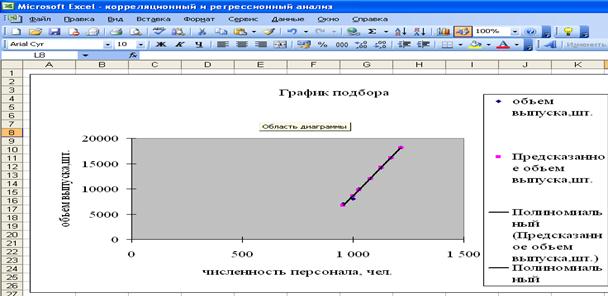
Рис. 23. График подбора
Рассчитанный по модели объем выпуска, достаточно близко отражает колебания реальной величины, одновременно сглаживая её резкие изменения. Графическое изображение наблюдаемого и предсказанного объемов реализации, доказывает точность полученной модели, что позволит её использовать в целях прогнозирования объемов выпуска товара. Было бы весьма интересно оценить прогнозную силу модели на практике, но в любом случае, предприятию совершенно нельзя придерживаться какой-либо единственной точки зрения или рекомендации, поскольку наиболее успешным результатом станет лишь объединение их максимального числа.
3. Построение математических трендовых моделей маркетинговых процессов в среде табличного процессора Microsoft Excel 3.1. Технология построения тренда через Мастер диаграмм Трендовая модель адекватна изучаемому процессу и отражает тенденциюего развития во времени при значениях R2, близких к 1. Для построения линии тренда необходимо выделить временные ряды X и Y и выбрать в меню кнопку Мастер диаграмм. Будет выведено окно Мастера диаграмм – Шаг 1 (рис. 24), в левой части которого приведены возможные для построения типы диаграмм, а в правой – их разновидности.Выбираем для построения Точечную диаграмму в виде плавной линии с узловыми точками. Затем переходим к следующему шагу построения – щелкаем ЛКМ по кнопке Далее. Рис. 24. Выбор вида диаграммыШаг 2. В этом окне указывается источник данных для построения диаграммы (столбцы или строки) и их диапазоны (рис. 25).
Рис. 24. Выбор вида диаграммыШаг 2. В этом окне указывается источник данных для построения диаграммы (столбцы или строки) и их диапазоны (рис. 25).  Рис. 25. Выбор источника данных для построение диаграммыПроверяем порядок размещения исходных данных – переключатель рядов данных должен находиться в поле В столбцах. Переходим к следующему шагу построения диаграммы – нажимаем кнопку Далее.Шаг 3. В окне Параметры диаграммы (рис. 11) в полях Ось X и Ось Y следует ввести названия осей, а в поле Название диаграммы ввести заголовок диаграммы. Затем следует щелкнуть ЛКМ по закладкам Оси, Линии сетки, Легенда, Подписи данных и указать маркерами в квадратных полях необходимые параметры оформления диаграммы (рис. 26).
Рис. 25. Выбор источника данных для построение диаграммыПроверяем порядок размещения исходных данных – переключатель рядов данных должен находиться в поле В столбцах. Переходим к следующему шагу построения диаграммы – нажимаем кнопку Далее.Шаг 3. В окне Параметры диаграммы (рис. 11) в полях Ось X и Ось Y следует ввести названия осей, а в поле Название диаграммы ввести заголовок диаграммы. Затем следует щелкнуть ЛКМ по закладкам Оси, Линии сетки, Легенда, Подписи данных и указать маркерами в квадратных полях необходимые параметры оформления диаграммы (рис. 26).  Рис. 26. Установка параметров диаграммыШаг 4. На последнем этапе работы Мастера диаграмм следует выбрать место размещения диаграммы – на имеющемся, т. е. на листе, где размещены исходные данные, или же отдельном – Диаграмма1. Для лучшего визуального восприятия целесообразно поместить диаграмму на отдельном листе (рис. 27).
Рис. 26. Установка параметров диаграммыШаг 4. На последнем этапе работы Мастера диаграмм следует выбрать место размещения диаграммы – на имеющемся, т. е. на листе, где размещены исходные данные, или же отдельном – Диаграмма1. Для лучшего визуального восприятия целесообразно поместить диаграмму на отдельном листе (рис. 27). 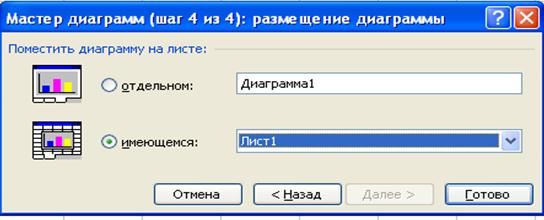 Рис. 27. Выбор листа для расположения диаграммыДля завершения построения диаграммы следует нажать ЛКМ на кнопку Готово. Полученная диаграмма показана на рис. 28.
Рис. 27. Выбор листа для расположения диаграммыДля завершения построения диаграммы следует нажать ЛКМ на кнопку Готово. Полученная диаграмма показана на рис. 28. 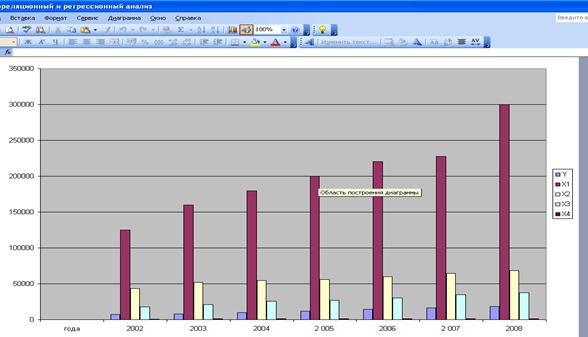 Рис. 28. Динамика процесса продаж по годамДля построения линии тренда необходимо выделить левой кнопкой мыши временной ряд и выбрать в контекстном меню (вызывается щелчком правой клавиши мыши) команду Добавить линию тренда. Будет вызвано диалоговое окно Линия тренда, содержащее вкладку Тип (рис. 29), на которой задается тип тренда: линейный; логарифмический; полиномиальный (от 2-й до 6-й степени включительно); степенной; экспоненциальный; скользящее среднее (с указанием периода сглаживания от 2 до 15).
Рис. 28. Динамика процесса продаж по годамДля построения линии тренда необходимо выделить левой кнопкой мыши временной ряд и выбрать в контекстном меню (вызывается щелчком правой клавиши мыши) команду Добавить линию тренда. Будет вызвано диалоговое окно Линия тренда, содержащее вкладку Тип (рис. 29), на которой задается тип тренда: линейный; логарифмический; полиномиальный (от 2-й до 6-й степени включительно); степенной; экспоненциальный; скользящее среднее (с указанием периода сглаживания от 2 до 15). 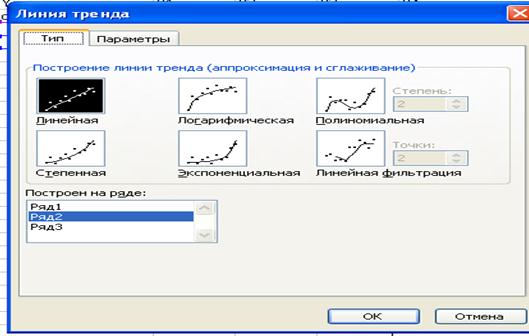 Рис. 29. Виды трендовых моделейВкладка Параметры (рис. 30) предназначена для задания параметров линии тренда:Имя тренда - имя линии тренда, располагается в легенде диаграммы. Возможны следующие варианты задания имени тренда:- автоматическое — Microsoft Excel именует линию тренда, основываясь на выбранном типе тренда и ряде динамики, с которым она ассоциирована, например Линейный (Ряд 1);-другое - вводится уникальное имя тренда, максимальная длина которого составляет 256 символов;- Прогноз вперед на - количество периодов, на которое линия тренда проектируется в будущее, т. е. в направлении от оси Y;- Прогноз назад на - количество периодов, на которое линия тренда проектируется в прошлое, т. е. в направлении к оси Y;- Пересечение кривой с осью Y в точке — точка, в которой линия тренда пересекает ось Y;- Показывать уравнение на диаграмме - на диаграмме будет показано уравнение линии тренда;- Поместить на диаграмму величину достоверности аппроксимации (R2);- на диаграмме будет показано значение коэффициента детерминации.
Рис. 29. Виды трендовых моделейВкладка Параметры (рис. 30) предназначена для задания параметров линии тренда:Имя тренда - имя линии тренда, располагается в легенде диаграммы. Возможны следующие варианты задания имени тренда:- автоматическое — Microsoft Excel именует линию тренда, основываясь на выбранном типе тренда и ряде динамики, с которым она ассоциирована, например Линейный (Ряд 1);-другое - вводится уникальное имя тренда, максимальная длина которого составляет 256 символов;- Прогноз вперед на - количество периодов, на которое линия тренда проектируется в будущее, т. е. в направлении от оси Y;- Прогноз назад на - количество периодов, на которое линия тренда проектируется в прошлое, т. е. в направлении к оси Y;- Пересечение кривой с осью Y в точке — точка, в которой линия тренда пересекает ось Y;- Показывать уравнение на диаграмме - на диаграмме будет показано уравнение линии тренда;- Поместить на диаграмму величину достоверности аппроксимации (R2);- на диаграмме будет показано значение коэффициента детерминации. 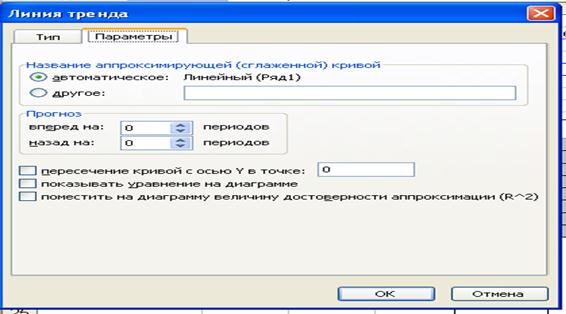 Рис. 30. Окно установки параметров линии трендаУчитывая сущность технологического процесса и характер изменения данных, выбираем линии тренда в виде полинома 2 или 3 степени. Щелкнув по закладке Параметры, устанавливаем маркеры в поле Показать уравнение на диаграмме и поле Показать на диаграмме величину достоверности аппроксимации. В окончательном виде диаграмма с планками погрешностей по оси Y представлена на рис. 31.
Рис. 30. Окно установки параметров линии трендаУчитывая сущность технологического процесса и характер изменения данных, выбираем линии тренда в виде полинома 2 или 3 степени. Щелкнув по закладке Параметры, устанавливаем маркеры в поле Показать уравнение на диаграмме и поле Показать на диаграмме величину достоверности аппроксимации. В окончательном виде диаграмма с планками погрешностей по оси Y представлена на рис. 31. 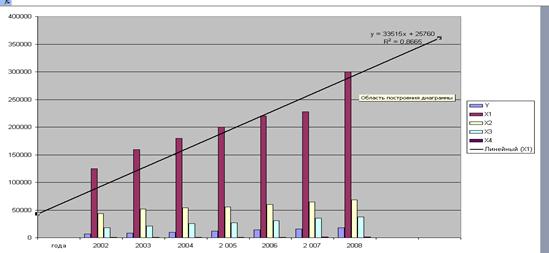 Рис. 31. Диаграмма, линейный тренд и его уравнение
Рис. 31. Диаграмма, линейный тренд и его уравнение|
|
|
|
|
Дата добавления: 2014-12-26; Просмотров: 940; Нарушение авторских прав?; Мы поможем в написании вашей работы!