КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
DQ dQ dQ
|
|
|
|
 где 0 есть Л/-мерный нулевой вектор. Допустим, что гессиан
где 0 есть Л/-мерный нулевой вектор. Допустим, что гессиан
(2.33)
dw2
это положительно определенная матрица. В этом случае вектор весов iv*
Q(w,,w2)
минимизирует среднеквадратичную погрешность реализации (2.31). Из уравнения (2.32) следует, что для этого вектора справедливо равенство
Rw' = p. (2.34)
Равенство (2.34) называется нормальным уравнением. Если det R ф 0, то его решением оказывается вектор
iv* = R 1р. (2.35)
При iv = iv* погрешность принимает минимальное значение, обозначаемое Q* и равное
Q(iv*) = Q* = E[d2(nj\ - 2w'Tp + w'T Riv*. (2.36)
Если подставить равенство (2.34) в выражение (2.36), то получим формулу для расчета минимальной среднеквадратичной погрешности реализации
Q* = E[cf2(n)] - w'Tp. (2.37)
Для нахождения оптимального вектора весов iv*, удовлетворяющего нормальному уравнению (2.34), требуется инвертировать матрицу автокорреляции R. Вместо этого можно использовать метод наискорейшего спуска (см., например, [2, 6]), который широко применяется в теории оптимизации. В этом методе предусматривается итеративный расчет последовательных приближений оптимального вектора iv*. Обозначим iv(n) приближение, рассчитанное на л-й итерации
w(n)=[w,(n),.... wN(n)]T. (2.38)
Очередные коррекции компонентов вектора весов iv(n) должны производиться в направлении, противоположном знаку компонентов вектора градиента
ЭО(иф7)) Г Э0(1У(п)) ЭО(1У(п)) 1Г
Э(»(л)) [ dw^n) '""' dwN(n) J ■ (2-39)
Алгоритм наискорейшего спуска можно представить в виде
|
|
E[d>)]\
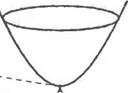
Рис. 2.8. Поверхность среднеквадратичной пофешности.
(2.40)
При подстановке формулы (2.32) в зависимость (2.40) получаем рекурсию
w(n + 1) = w(n) + [p~ Riv(n)], (2.41)
где константа ц > 0 определяет величину шага коррекции.
Можно показать (см., например, [8, 19]), что алгоритм наискорейшего спуска (2.41) сходится, т.е.
lim iv(n) = iv*, (2.42)
если шаг коррекции г) лежит в пределах
| (2.43) |
0 < Л <
где Ятах - это наибольшее собственное значение матрицы автокорреляции R.
| 2.4 Системы типа Адалайн |
30 Глава 2. Многослойные нейронные сети и алгоритмы их обучения
 Кроме того, доказано, что скорость сходимости алгоритма наискорейшего спуска зависит от отношения наименьшего и наибольшего собственных значений матрицы R. Если
Кроме того, доказано, что скорость сходимости алгоритма наискорейшего спуска зависит от отношения наименьшего и наибольшего собственных значений матрицы R. Если
Am. s -i _ (2.44)
то алгоритм наискорейшего спуска сходится быстро. Если же
(2.45)
Лпах
то алгоритм наискорейшего спуска сходится медленно. 2.4.2. Адаптивный линейный взвешенный сумматор
Применение алгоритма (2.41) предполагает знание матрицы R и вектора & В случае, когда эти величины неизвестны, следует заменить градиент (2.39) его приближением. Запишем рекурсивное выражение (2.40) в виде
w(n+1)=-w(n)-l4^M. (2.46)
Если в этой формуле заменить градиент его приближенным локальным значением (instantaneous estimate), т.е.
(2.47)
| dw(n) dw(n) ' |
то получим рекурсию вида
(2.48)
Из выражений (2.24) и (2.25) следует, что
n +1) = Щп)+i\n{ n)[d(D) - wT(n)u(n)]
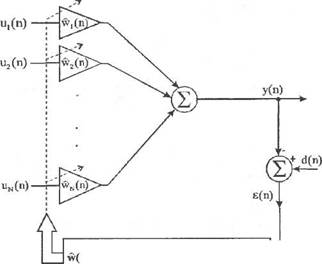
 Рис. 2.9. Адаптивный линейный взвешенный сумматор.
Рис. 2.9. Адаптивный линейный взвешенный сумматор.
Щ(п) wN(n),
2) подсистемы, предназначенной для адаптивной коррекции этих весов и реализующей алгоритм LMS.
Параметр ц в алгоритме (2.50) подбирается так (см. [27]), чтобы выполнялось условие
"' ■■' 2 --а-------------------- • (2-52)
—-----;—г- tcii/1-r-------- —- "l";-vv- (^-4У)
dw(n) dw(n)
При подстановке зависимости (2.49) в формулу (2.48) получаем
так называемый алгоритм LMS (Least Mean Square) в векторной форме
w(n + 1) = w(ri) + u(n)[d(n) - wT(n)u(n)] (2.50)
или в скалярной форме
N
wk(n + l)=wk(n) + uk(n) d(n)-^wk(n)uk(n) (2.51)
для к- 1..... N.
На рис. 2.9 представлен адаптивный линейный взвешенный сумматор, известный в литературе под названием Адалайн (Adaptive Linear Neuron). Он состоит из двух основных частей:
1) линейного взвешенного сумматора с адаптивно корректируемыми весами
где TrR обозначает след матрицы R.
|
|
|
|
|
Дата добавления: 2015-06-04; Просмотров: 497; Нарушение авторских прав?; Мы поможем в написании вашей работы!