КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Распределение IQ-оценок и показателей теста зрительной памяти
|
|
|
|
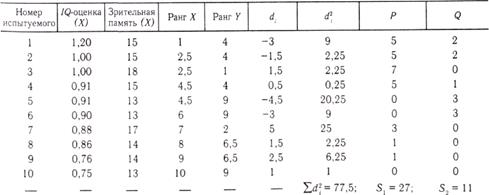
Коэффициент корреляции рангов Спирмена (rs) определяется из уравнения:
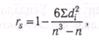
где di — разности между рангами каждой переменной из пар значений X и Y; n — число сопоставляемых пар.
Используя данные табл. 12, получаем:
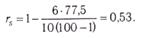
Коэффициент корреляции рангов Кендалла τ определяется следующей формулой:
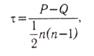
где Р и Q рассчитываются по табл. 12. Так, в восьмой графе подсчитывается, начиная с первого объекта X, сколько раз его ранг по Y меньше, чем ранг объектов, расположенных ниже. Соответственно в девятой графе (S2) фиксируется, сколько раз ранг Y больше, чем ранги, стоящие ниже его в столбце X. Подставляя эти данные в формулу, получаем:
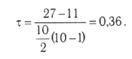
При сопоставлении приведенных коэффициентов оказывается, что коэффициент τ более информативен, чем rs, и рассчитывается проще. Поэтому на практике при расчете К. р. отдают предпочтение коэффициенту τ.
КОСА КУБИКИ — невербальный тест интеллекта. Предложен К. Косом в 1920г.
Испытуемому предлагают составить фигуры из цветных кубиков по рисункам-образцам. Тестовый материал состоит из шестнадцати кубиков с ребром 2,5 см, стороны которых окрашены в красный, белый, желтый и синий цвета. Оставшиеся две противоположные грани разделены по диагонали, причем одна окрашена в белый и красный цвета, а вторая — в синий и желтый (см. Векслера интеллекта измерения шкалы, рис. 13). В набор включены восемнадцать образцов фигур, первый из которых является тренировочным и выполняется совместно с испытуемым. Цвета рисунков-образцов соответствуют цветам кубиков, но размеры образцов вдвое меньше. Образцы размещены посередине картонной карточки, имеющей размер 10 х 7,5 см.
Задания следуют в порядке возрастающей трудности, что обеспечивается последовательной комбинацией следующих условий:
— фигуру можно построить только из одноцветных сторон кубиков;
— для построения фигуры следует использовать несколько двухцветных граней;
— фигуру можно сложить только из двухцветных сторон или из сочетания двухцветных и одноцветных, причем на образце не обозначена граница между соседними кубиками;
— образец повернут на 45°, т. е. стоит на ребре;
— для составления фигур требуется использовать все большее количество кубиков;
— образцы постепенно становятся все менее симметричными;
— увеличивается количество цветов на образце;
— образец не ограничивается рамкой, так что на краях сливается с фоном.
Образцы-рисунки испытуемому предъявляются последовательно, тестирование прекращается после пяти последовавших друг за другом неудачных решений. Успешность оценивается с нескольких позиций. Самым важным показателем является время решения отдельных заданий. В протоколе фиксируется и количество попыток при выполнении. Первичные оценки по результатам выполнения заданий переводятся в показатель умственного возраста. В более поздних модификациях оценки переводятся в IQ-показа-тели стандартные. Данные дополняются качественным анализом поведения испытуемого.
К. к. принадлежат к часто применяемым тестам и широко используются как в оригинальной, так и в сокращенных модификациях (см., напр., Векслера интеллекта измерения шкалы). Ценность теста определяется особенностями деятельности испытуемого, которая моделируется его заданиями. Испытуемый начинает выполнение задания с анализа образца, путем сопоставления фрагментов образца с гранями кубиков. Затем осуществляется генерализация выделяемого признака. Вслед за этим осуществляется переход к синтезу — констатация соответствия между образцом и собранной из кубиков фигурой. По мнению К. Коса, в ходе решения заданий задействуются все мыслительные процессы.
Имеются сведения о валидности конструктной К. к. Получена значимая корреляция с Бине—Симона умственного развития шкалой (r =0,82 у нормальных детей и r = 0,67 у слабоумных детей). Изучались связи показателей К. к. с основными тестами интеллекта, в частности Станфорд—Бине умственного развития шкалой (r = 0,77), Равена прогрессивными матрицами (r = 0,81). Обращается внимание на независимость друг от друга показателей К. к. и тестов арифметических способностей.
Наиболее широкое применение К. к. находят в клинической психодиагностике (В. М. Блейхер, И. В. Крук, 1986). По данным Л. Кошча (1976), тест весьма полезен при работе с такими разнообразными контингентами испытуемых, как творческие личности с высоким уровнем способностей и, с другой стороны, умственно отсталые лица; дети с минимальной мозговой дисфункцией, нарушением концентрации внимания, нарушением пространственной ориентировки; дети, страдающие неврозами; дети с задержкой психического развития, педагогически запущенные; больные юношеского и зрелого возраста, страдающие шизофренией. Тест может использоваться и при анализе интеллектуального потенциала здоровых лиц.
В отечественной психодиагностике К. к. используются чаще всего в том виде, как они представлены в соответствующем отдельно взятом субтесте Векслера интеллекта измерения шкалы.
КОЭФФИЦИЕНТ АЛЬФА (α) — статистический показатель, используемый при дисперсионном анализе. Предложен Л. Кронбахом (1971). Наиболее часто применяется при оценке надежности теста. Уравнение К. А. имеет следующий вид:
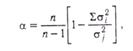
где п — количество заданий теста, 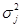 — квадрат стандартного отклонения для всего теста,
— квадрат стандартного отклонения для всего теста, 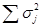 — сумма квадратов стандартных отклонений для отдельных заданий. В том случае, если в методике применяются задания дихотомического типа («да»—«нет», «правильно»—«неправильно»), может быть использована упрощенная формула:
— сумма квадратов стандартных отклонений для отдельных заданий. В том случае, если в методике применяются задания дихотомического типа («да»—«нет», «правильно»—«неправильно»), может быть использована упрощенная формула:

где 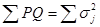 и Р — доля испытуемых, давших «ключевой» или правильный ответ, a Q = 1 - Р. Дихотомический вариант К. А. является уравнением Кьюдера—Ричардсона (см. Надежность частей теста). Применение К. А. основано на модели, предполагающей наличие большой дисперсии (а стало быть, и дискриминативности заданий теста) скорее у надежного, чем у ненадежного теста (см. Надежность факторно-дисперсионная). Таким образом, если при факторном анализе возвести в квадрат и просуммировать нагрузки выявленных факторов, можно определить надежность, поскольку нагрузки факторов представляют корреляцию теста с общими или специфическими факторами. Модель надежности факторно-дисперсионной близка к анализу надежности по внутренней согласованности.
и Р — доля испытуемых, давших «ключевой» или правильный ответ, a Q = 1 - Р. Дихотомический вариант К. А. является уравнением Кьюдера—Ричардсона (см. Надежность частей теста). Применение К. А. основано на модели, предполагающей наличие большой дисперсии (а стало быть, и дискриминативности заданий теста) скорее у надежного, чем у ненадежного теста (см. Надежность факторно-дисперсионная). Таким образом, если при факторном анализе возвести в квадрат и просуммировать нагрузки выявленных факторов, можно определить надежность, поскольку нагрузки факторов представляют корреляцию теста с общими или специфическими факторами. Модель надежности факторно-дисперсионной близка к анализу надежности по внутренней согласованности.
Факторно-дисперсионный метод анализа надежности находится в сильной зависимости от выбора переменных, в связи с которыми факторизуется тест. Так, если сопоставлять тест математических способностей с личностными или мотивационными переменными, то оценка надежности была бы неадекватной (практически не было бы общих факторов). С другой стороны, если бы тест факторизировался совместно с тестами общих способностей так, чтобы каждый тест мог нагружать соответствующие ему факторы, метод надежности факторно-дисперсионной мог бы быть достаточно точным. Таким образом, эта модель подходит для оценки надежности теста, факторная валидность которого известна или задана при разработке, а также тестов, связанных с ограниченным числом общих факторов.
КРИТЕРИАЛЬНО-КЛЮЧЕВОЙ ПРИНЦИП — принцип конструирования тестов на основе обнаружения (эмпирического) психологических признаков, позволяющих дифференцировать релевантные критериальные группы от контрольных. Широко используется для конструирования психодиагностических методик наряду с факторно-аналитическим принципом. Примером методик, в которых реализован К.-к. п., являются опросники эмпирические, такие как Миннесотский многоаспектный личностный опросник, «Бланк интересов» Стронга (см. Опросники интересов) и др.
Так, при разработке MMPI из первоначального банка утверждений в основные клинические шкалы включались только те, которые хорошо дифференцировали испытуемых с тем или иным клиническим диагнозом от контрольной группы здоровых людей (см. Дискриминативностъ заданий теста). В шкалы «Бланка интересов» Стронга вошли те утверждения из первоначального набора, которые реально разделяли группы лиц, являвшихся носителями определенных интересов. Иногда задания, объединенные общей шкалой в силу эмпиричности конструирования, не имеют не только теоретического, но даже интуитивного, гипотетического объяснения.
В тех случаях, когда необходимо дискриминировать группы, напр., в профотборе, К.-к. п. является достаточно эффективным.
В тестах, созданных в соответствии с К.-к. п., основное значение придается дискриминативности. Важен тот факт, что тест является дискриминативным, а не причина, по которой это происходит. В связи с использованием К.-к. п. конструирования тестов возникает ряд проблем, которые должен решать разработчик. К их числу в первую очередь следует отнести трудности в отборе критериальных групп. MMPI, например, разрабатывался, как указывалось выше, путем сопоставления больных и здоровых, однако разработка шкалы шизофрении (Sc) или паранойи (Ра) с большим успехом могла бы опираться на сопоставление группы больных с выраженными шизоидными или паранойяльными тенденциями с группой пациентов, у которых отмечаются противоположные патологические особенности, но это практически нереально. Комплектование критериальной группы больных опиралось на врачебный диагноз, который разными специалистами может восприниматься по-разному. Сложность в отборе «чистых» групп для сравнения ведет в конечном итоге к снижению надежности и валидности теста. (См. также Контрастные группы.)
Другая проблема связана со значительными трудностями, а иногда и невозможностью психологической интерпретации показателей тестов, созданных в соответствии с К.-к. п. Наиболее вероятным является то, что одна критериальная группа отличается от релевантной ей не одним, а несколькими (иногда многими) переменными. Полученные шкалы являются, таким образом, не однозначными, а мультивариантными. Следовательно, два идентичных показателя могут иметь различную интерпретацию, и не существует определенного способа по виду показателя установить, что измеряет данная шкала. Факт, что тест может дискриминировать группу X от группы Y, не говорит ничего о природе переменной, измеряемой тестом, если только мы не располагаем доказательством, что группы отличаются одна от другой лишь по одной переменной.
Результатам тестов, разработанных на основе К.-к. п., присуща известная специфичность, что также является серьезным ограничением. Например, если такой тест используется для отбора сборщиков электронной аппаратуры, он будет разрабатываться на основе конкретного критерия, связанного с выполнением работы определенного характера. Если содержание работы изменится, разработанный на основе неадекватных критериальных признаков тест станет бесполезен. В противовес этому тесты, ориентированные на базовые способности, по-прежнему могут быть использованы.
Факторный тест, относительно «чистый» по исследуемым переменным и опирающийся на теорию измеряемого конструкта, как можно ожидать, будет предпочтительней страдающих эмпиричностью тестов, созданных в соответствии с К.-к. п. Однако разработка факторно-аналитического теста является технически более сложной, трудоемкой задачей.
Не нужно противопоставлять К.-к. п. конструирования тестов факторно-аналитическому принципу; следует помнить, что при подборе первичного банка заданий разработчики исходят, как правило, из описания некоего свойства, конструкта, являющегося объектом измерения. С другой стороны, разработанный по К.-к. п. тест в последующем может пройти процедуру факторизации.
«Эмпиричность» таких тестов в значительной степени сглаживается и последующей процедурой определения валидности конструктной.
Для методик, созданных в соответствии с К.-к. п., наибольшее значение имеют эмпирические модели определения надежности (см. Надежность ретестовая, Надежность параллельных форм, Надежность частей теста).
КРИТЕРИЙ χ2 (критерий согласия Пирсона) — характеристика распределения, используемая для проверки статистических гипотез. Под статистическим критерием подразумевается правило, обеспечивающее с определенной вероятностью принятие истинной или отклонение ложной гипотезы. В качестве критериев в математической статистике применяют определенные случайные величины, являющиеся функциями изучаемых случайных величин и чисел степеней свободы. Одним из наиболее часто применяемых является К. χ 2, представляющий собой сумму квадратов отклонений эмпирических частот (р) от теоретических или ожидаемых (р'), отнесенную к теоретическим частотам:
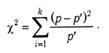
При полном совпадении эмпирических и ожидаемых частот S (р - р') = 0. При несовпадении производится сравнение эмпирической величины χ 2 с его критическим значением, определенным по таблицам (см. Приложение III, табл. 3). Нулевая гипотеза, которая предполагает, что расхождение между эмпирическими частотами и математическим ожиданием носит случайный характер и между вычисленными и эмпирическими частотами разницы нет, опровергается, если  для принятого уровня значимости (α) и числа степеней свободы (df). В качестве примера проанализируем с помощью К. χ 2 распределение частот выбора ответа на закрытый пункт теста (см. Задачи закрытого типа). Предлагаемые варианты неправильных ответов должны быть примерно равновероятны. При обследовании 100 человек, отвечающих на проверяемый пункт неверно, результаты распределились следующим образом (табл. 14).
для принятого уровня значимости (α) и числа степеней свободы (df). В качестве примера проанализируем с помощью К. χ 2 распределение частот выбора ответа на закрытый пункт теста (см. Задачи закрытого типа). Предлагаемые варианты неправильных ответов должны быть примерно равновероятны. При обследовании 100 человек, отвечающих на проверяемый пункт неверно, результаты распределились следующим образом (табл. 14).
Таблица 14
Распределение ошибочных ответов на репертуар закрытого задания теста у 100 обследованных
| Показатель | Выбор ответа | ||||
| а | b | с | d | е | |
| Частота в опыте (р) | |||||
| Ожидаемая частота при равновероятном выборе (р') | |||||
| Отклонение (р - р') | |||||
Вычисление 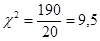
|
Степень свободы для данного случая df - п - 1 = 4 (где n — число вариантов ответа). По табл. 3 Приложения III для α = 0,01 и df = 4 находим 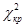 = 3,28, Полученное значение χ2 = 9,5 меньше табличного. Следовательно, при решении задачи может быть принята гипотеза о примерно равновероятном распределении выбора ответов а, b, с, d, е. При повторных случайных выборках вероятность ложного вывода составит 1 %.
= 3,28, Полученное значение χ2 = 9,5 меньше табличного. Следовательно, при решении задачи может быть принята гипотеза о примерно равновероятном распределении выбора ответов а, b, с, d, е. При повторных случайных выборках вероятность ложного вывода составит 1 %.
В качестве другого примера рассмотрим проверку нормальности распределения тестовых оценок (см. Оценка типа распределения). Исходные данные приведены в табл. 15, 16.
Таблица 15
|
|
|
|
|
Дата добавления: 2015-06-04; Просмотров: 773; Нарушение авторских прав?; Мы поможем в написании вашей работы!