КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Методы многомерного шкалирования
|
|
|
|
В дальнейшем развитие методов психосемантики шло по линии разработки удобных пакетов прикладных программ, основанных на методах многомерного шкалирования (МШ), факторного анализа, а также специализированных методов (статистической) обработки репертуарных решеток [Франселла, Баннистер, 1987]. Примерами пакетов такого типа являются системы KELLY [Похилько, Страхов, 1990], MADONNA [Терехина, 1988], MEDIS [Алексеева, Воинов и др., 1989]. С другой стороны, специфика ряда конкретных приложений, прежде всего в инженерии знаний, требовала также развития иных (не численных) методов обработки психосемантических данных, использующих - в той или иной форме - парадигму логического вывода на знаниях. Ярким примером этого направления служит система AQUINAS [Boose et al., 1989; Boose, 1990]. Однако анализ практического применения систем обоих типов к задачам инженерии знаний приводит к выводу о несовершенстве имеющихся методик и необходимости их развития в соответствии с современными требованиями инженерии знаний. Наибольшие перспективы в этой области, по-видимому, у методов много-мерного шкалирования).
Многомерное шкалирование (МШ) сегодня - это математический инструментарий, предназначенный для обработки данных о попарных сходствах, связях или отношениях между анализируемыми объектами с целью представления этих объектов в виде точек некоторого координатного пространства. МШ представляет собой один из разделов прикладной статистики, научной дисциплины, разрабатывающей и систематизирующей понятия, приемы, математические методы и модели, предназначенные для сбора, стандартной записи, систематизации и обработки статистических данных с целью их лаконичного представления, интерпретации и получения научных и практических выводов. Традиционно МШ используется для решения трех типов задач:
1. Поиск и интерпретация латентных (то есть скрытых, непосредственно не наблюдаемых) переменных, объясняющих заданную структуру попарных расстояний (связей, близостей).
2. Верификация геометрической конфигурации системы анализируемых объектов в координатном пространстве латентных переменных.
3. Сжатие исходного массива данных с минимальными потерями в их информативности.
Независимо от задачи МШ всегда используется как инструмент наглядного представления (визуализации) исходных данных. МШ широко применяется в исследованиях по антропологии, педагогике, психологии, экономике, социологии [Дэйвисон, 1988].
В основе данного подхода лежит интерактивная процедура субъективного шкалирования, когда испытуемому (то есть эксперту) предлагается оценить сходство между различными элементами П с помощью некоторой градуированной шкалы (например, от 0 до 9, или от -2 до +2). После такой процедуры аналитик располагает численно представленными стандартизованными данными, поддающимися обработке существующими пакетами прикладных программ, реализующими различные алгоритмы формирования концептов более высокого уровня абстракции и строящими геометрическую интерпретацию семантического пространства в евклидовой системе координат.
Основной тип данных в МШ - меры близости между двумя объектами (i, j) -dij. Если мера близости такова, что самые большие значения dij соответствуют парам наиболее похожих объектов, то dij - мера сходства, если, наоборот, наименее похожим, то dij - мера различия.
МШ использует дистанционную модель различия, используя понятие расстояния в геометрии как аналогию сходства и различия понятий (рис. 5.3).
Для того чтобы функция d, определенная на парах объектов (а, b), была евклидовым расстоянием, она должна удовлетворять следующим четырем аксиомам:
d (a,b)>0,
d(a,a) = 0,
d(a,b) = d(b,a),
d(a,b)+d(b,c) > d(a,c).
Тогда, согласно обычной формуле евклидова расстояния, мера различия двух объектов i и j со значениями признака k у объектов i и j соответственно Xik и Xjk:
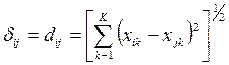
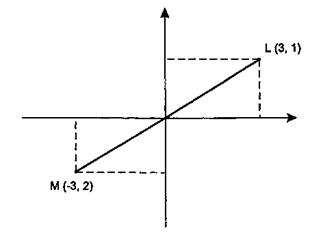
Рис. 5.3. Расстояние в евклидовой метрике
Дистанционная модель была многократно проверена в социологии и психологии [Monahan, Lockhead, 1977; Петренко, 1988, Шмелев, 1983], что дает возможность оценить ее пригодность для использования.
В большинстве работ по МШ используется матричная алгебра. Геометрическая интерпретация позволяет представить абстрактные понятия матричной алгебры в конкретной графической форме. Для облегчения интерпретации решения задачи МШ к первоначально оцененной матрице координат стимулов X применяется вращение
Среди множества алгоритмов МШ широко используются различные модификации метрических методов Торгерсона [Torgerson, 1958], а также неметрические модели, например Крускала [Kruskal, 1964]
При сравнении методов МШ с другими методами анализа, теоретически применимыми в инженерии знаний (иерархический кластерный анализ [Дюран, Оделл, 1977] или факторный анализ [Иберла, 1980]), МШ выигрывает за счет возможности дать наглядное количественное координатное представление, зачастую более простое и поэтому легче интерпретируемое экспертами.
5.1.3. Использование метафор для выявления «скрытых» структур знаний
Несмотря на кажущуюся близость задач, инженерия знаний и психосемантика существенно отличаются как в теоретических основаниях, на которых они базируются, так и в практических методиках. Но главное отличие заключается в том, что инженерия знаний направлена на выявление - в конечном итоге - модели рассуждений [Поспелов, 1989], динамической или операциональной составляющей ментального пространства (или функциональной структуры поля знаний Sf), в то время как психосемантика, пытаясь представить ментальное пространство в виде евклидова пространства, позволяет делать видимой статическую структуру взаимного «расположения» объектов в памяти, в виде проекций скоплений объектов (концептуальная структура Sk).
Помимо этого следует отметить ряд недостатков методов психосемантики с точки зрения практической инженерии знаний.
1. Поскольку в основе психосемантического эксперимента лежит процедура измерения субъективных расстояний между предъявляемыми стимулами, то и результаты обработки такого эксперимента, как правило, используют геометрическую интерпретацию - евклидово пространство небольшого числа измерений (чаще всего - двумерное). Такое сильное упрощение модели памяти может привести к неадекватным базам знаний.
2. Естественность иерархии как глобальной модели понятийных структур сознания служит методологической базой ОСП. Кроме того, и в естественном языке понятия явно тяготеют к различным уровням обобщения. Однако в большинстве прикладных пакетов не предусмотрено разбиение семантического пространства на уровни, отражающие различные степени общности понятий, включенных в экспериментальный план. В результате получаемые кластеры понятий, пространственно изолированные в геометрической модели шкалирования, носят таксономически неоднородный характер и трудно поддаются интерпретации.
3. Единственные отношения, выявляемые процедурами психосемантики, - это «далеко - близко» по некоторой шкале. Для проектирования и построения баз знаний выявление отношений является на порядок более сложной задачей, чем выявление понятий. Поэтому семантические пространства, полученные в результате шкалирования и кластеризации, должны быть подвергнуты дальнейшей обработке на предмет определения отношений, особенно функциональных и каузальных.
Нельзя ожидать, что эти противоречия могут быть разрешены быстро и безболезненно, в силу того, что математический аппарат, положенный в основу всех пакетов прикладных программ по психосемантике, имеет определенные границы применимости. Однако одним из возможных путей сближения без нарушения чистоты процедуры видится расширение пространства конкретных объектов-стимулов предметной области за счет добавления некоторых абстрактных объектов из мира метафор, которые заставят эксперта-испытуемого выйти за рамки объективности в мир субъективных представлений, которые зачастую в большей степени влияют на его рассуждения и модель принятия решений, чем традиционные правильные взгляды.
Ниже описан подход, разработанный совместно с Воиновым А. В. [Voinov, Gavrilova, 1993; Воинов, Гаврилова, 1994] и позволяющий вывести эксперта за границы традиционной установки и тем самым выявить субъективные, часто скрываемые или скрытые структуры его профессионального опыта.
Большинство результатов, полученных в когнитивной психологии, подтверждают, что у человека (в том числе и у эксперта) формальные знания о мире (в частности, о той предметной области, где он является экспертом) и его личный поведенческий опыт не могут существовать изолированно, они образуют целостную, стабильную структуру. В западной литературе за этой структурой закрепилось название «модель (или картина) мира». Принципиальным свойством модели мира является то, что ее структура не дана человеку - ее носителю - в интроспекции, она работает на существенно латентном, неосознаваемом уровне, зачастую вообще ничем не отмеченном (в символической форме) на поверхности вербального сознания.
Изучение модели мира человека является задачей когнитивной психологии, психосемантики и прочих родственных дисциплин. Что же касается эксперта как объекта пристального внимания инженерии знаний, то здесь одна из проблем, в решении которых может помочь психосемантика, связана с необходимостью (и неизбежностью) отделения опыта эксперта от его объективных знаний в процессе формализации и структурирования, последних для экспертных систем.
Строго говоря, невозможно указать ту грань, за которой знания (которые можно формализовать и извлечь) переходят в опыт (то есть в то, что остается уникальной, неотчуждаемой собственностью эксперта). Более корректно, по-видимому, говорить о неком континууме, детальность градации которого может зависеть от конкретной задачи.
Например, можно выделить следующие три уровня:
1. Знания, предназначенные для изложения или доказательства (аргументации), например, на междисциплинарном уровне или для популярной лекции (вербальные).
2. Знания, которые применяются в реальной практике, - знания еще вербализуемые, но уже нерефлектируемые.
3. Собственно опыт, то есть знания, лежащие на наиболее глубоком, неосознаваемом уровне, отвечающие за те решения эксперта, которые внешне (в том числе и для него самого) выглядят как мгновенное озарение или «инсайт», интуитивный творческий акт (интуитивные).
Классическая методика психосемантического эксперимента также не позволяет выделить из его результатов интуитивный уровень. Это видно из самой тестовой процедуры. Просят ли испытуемого оценить сходство-различие стимулов напрямую или же предлагается оценить их соответствие некоторым «конструктам» - в любом случае испытуемый вольно или невольно настраивается на необходимость доказательности своего ответа в терминах объективных свойств стимулов.
Большинство методов извлечения знаний ориентировано на верхние - вербальные или вербализируемые - уровни знания. Необходим косвенный метод, ориентированный на выявление скрытых предпочтений практического опыта или операциональных составляющих опыта. Таким методом может служить метафорический подход. Метафорический подход, впервые описанный с чисто лингвистических позиций [Black, 1962; Ricoeur, 1975], а также с позиций практической психологии [Гордон, 1987], был видоизменен для нужд инженерии знаний. Например, в экспериментах по объективному сравнению языков программирования между собой были также использованы два метафорических «мира» - мир животных и мир транспорта.
В рамках этого подхода удалось экспериментально доказать следующие тезисы:
• метафора работает как фильтр, выделяющий, посредством подбора адекватного объекта сравнения, определенные свойства основного объекта (то есть того, о котором собственно и идет речь). Эти выделяемые свойства имеют существенно операциональный характер, проявляющийся на уровне полиморфизма методов, так как метафора по самой своей сути исключает возможность сравнения объектов по их внутренним, объективным свойствам;
• метафора имеет целью скорее не сообщить что-либо о данном объекте (то есть ответить на вопрос «что это?»), а призвать к определенному отношению к нему, указать на некую парадигму, говорящую о том, как следует вести себя по отношению к данному объекту;
• субъективному сдвигу в отношении к основному объекту (например, к языку программирования) сопутствует также и сдвиг в восприятии объекта сравнения (например, к конкретному животному) в силу вышеуказанной специфики фильтруемых метафорой свойств. Поэтому объект сравнения выступает в метафоре не по своему прямому назначению, то есть это не просто «лев» как представитель фауны, а воплощение силы, ловкости и могущества;
• в том случае, когда метафора сопоставляет не единичные объекты, а некоторые их множества, в которых объекты связаны осмысленными отношениями, пространство объектов сравнения должно быть изоморфно пространству основных объектов по системе указанных отношений.
На эти тезисы опирается предлагаемая модификация классической методики сопоставления объектов, применяемой, например, в оценочной решетке Келли [Kelly, 1955]. При проведении эксперимента была использовала система MEDIS [Алексеева, Воинов и др., 1989; Воинов, Гаврилова, 1994]. Эта система позволяет планировать, проводить и обрабатывать данные произвольного психосемантического эксперимента. Помимо классической парадигмы многомерного шкалирования, система MEDIS включает в себя некоторые возможности теста репертуарных решеток. В частности, она позволяет работать со стимулами двух сортов - так называемыми элементами и конструктами (с единственным исключением: конструкты в системе MEDIS - в отличие от классического теста репертуарных решеток - монополярны). Естественно, выбор базового инструментария существенно повлиял на описываемую экспериментальную реализацию методики. В качестве предметной области был выбран мир языков программирования. В пространство базовых понятий (выступавших в методике в качестве элементов) было включено несколько более или менее популярных языков программирования, принадлежащих к следующим классам:
• языки искусственного интеллекта;
• традиционные процедурные языки
• так называемые «макроязыки», обычно реализуемые в оболочках операционных систем, текстовых редакторах и т. д.
В качестве метафорических пространств выбраны мир животных и мир транспорта. Объекты этих миров выступали в методике в качестве (монополярных) конструктов. На первом этапе эксперимента каждый из респондентов выполнял классическое попарное субъективное шкалирование элементов. На вопрос, «Есть ли что-либо общее между данными языками программирования», респонденту предлагалось ответить одной из следующих альтернатив.
| ДА! | Объекты очень близки | |
| Да | Между объектами есть что-то общее | |
| ??? | Неопределенный ответ | |
| Нет | Объекты различны | |
| НЕТ! | Объекты совершенно несовместимы |
Данные этого этапа (отдельно для каждого из респондентов) подвергались обработке методами многомерного шкалирования (см. выше) и представлены на рис. 5.4.
Результатом такой обработки является некоторое евклидово пространство небольшого числа измерений, в котором исходные оценки различий представлены геометрическими расстояниями между точками. Чем лучше эти расстояния соответствуют исходным различиям, тем более адекватным считается результат обработки в целом. При этом буквальное совпадение расстояний и числовых кодов ответов, естественно, не является обязательным (хотя оно и возможно в некоторых модельных экспериментах). Более важным оказывается ранговое соответствие расстояний исходным оценкам. А именно, в идеальном случае все расстояния между точками, соответствующие (например) ответам «ДА!» в исходных данных, должны быть меньше (хотя бы и на доли процента масштаба шкалы) всех расстояний, соответствующих ответам «Да», и т. д.
В реальном эксперименте идеальное соответствие невозможно в принципе, так как целью обработки является сжатие, сокращение размерности данных, что ограничивает число координатных осей результирующего пространства. Тем не менее, алгоритм шкалирования пытается - насколько это возможно - минимизировать ранговое несоответствие модели исходным данным.
Геометрическую модель шкалирования можно интерпретировать по-разному:
• во-первых, можно выяснить смысл координатных осей результирующего пространства. Эти оси по сути своей аналогичны факторам в факторном анализе, что позволяет использовать соответствующую парадигму интерпретации, детально разработанную в экспериментальной психологии. В данном случае можно считать, что выявленные факторы играют роль базовых категорий, или базовых (латентных) конструктов, с помощью которых респондент (как правило, неосознанно) упорядочивает свою картину мира (точнее, ее проекцию на данную предметную область);
• во-вторых, можно проанализировать компактные группировки стимулов в этом пространстве, отождествив их с некоторыми существенными (хотя и скрытыми от интроспекции) таксономическими единицами, реально присутствующими в модели мира эксперта. Существенно, что делается попытка интерпретировать кластеры, полученные по модели шкалирования, а не по исходным числовым кодам различий. Это вытекает из предположения, что информация, не воспроизводимая главными (наиболее нагруженными) факторами, является «шумом», сопутствующим любому (а особенно психологическому) эксперименту.
Рисунок 5.4 отражает традиционную классификацию языков программирования и легко поддается вербальной интерпретации. Например, на рисунке горизонтальная ось соответствует делению языков программирования на «языки искусственного интеллекта» (левый полюс шкалы) и «традиционные языки программирования» (правый полюс). Вертикальная ось отражает классификацию языков программирования в зависимости от уровня - языки высокого уровня (нижний полюс) и языки низкого уровня или системные языки (верхний полюс).
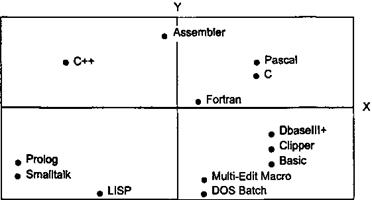
Рис. 5.4. Классификация языков программирования
Основная экспериментальная процедура - попарное сравнение некоторых объектов и выражение степени их сходства (несходства) на числовой оси или выделение пар близких объектов из предъявленной триады - сама по себе накладывает большое количество ограничений на выявляемую структуру, в частности:
1. Из-за выбора стимульного материала (выбор объектов остается за инженером по знаниям).
2. Из-за несовершенства шкалы измерений.
3. В связи с рядом допущений математического аппарата. Но главное, что полученная структура знаний чаще всего носит академический характер, то есть отражает объективно существующие, но легко объяснимые, как бы лежащие на поверхности закономерности.
Это связано с психологической установкой самого эксперимента, во время которого эксперта как бы проверяют, экзаменуют и он, естественно, стремится давать правильные ответы.
На следующем этапе эксперимента респонденту предлагалось сопоставить каждый из языков программирования с каждым из метафорических персонажей. Как и на первом этапе, пары предъявлялись в равномерно-случайном порядке (аналогичном расписанию кругового турнира в спортивных играх). Инструкция для сопоставления выглядела следующим образом:
Попробуйте оценить выразительную силу данной метафоры: «ЛИСП - это слон» или «C++ - это яхта».
|
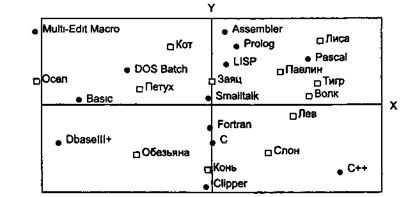
Результирующая таблица числовых кодов оценок (идентичная оценочной решетке Келли) была также обработана методами многомерного шкалирования программы МЕДИС. Результаты представлены на рис. 5.5 и 5.6.
Рис. 5.5. Метафорическая классификация языков программирования (мир животных)
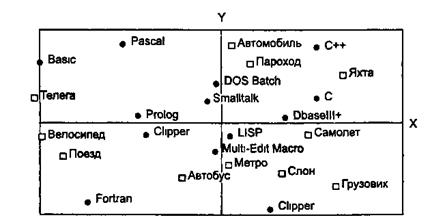
Рис. 5.6. Метафорическая классификация языков программирования (мир транспорта)
При интерпретации удалось выявить такие латентные понятия и структуры, как «степень изощренности языка» (шкала X рис. 5.5), «сила» (шкала Y рис. 5.5), «универсальность» (шкала Y рис. 5.6), «скорость» (шкала X рис. 5.6) и др.
Кроме этого, полученные рисунки позволили выявить скрытые предпочтения эксперта и существенные характеристики объектов, выступавших в виде стимулов - «силу» языка С («слон»); скорость C++ («яхта»); «старомодность» Фортрана («телега») и пр.
В применении к реальному процессу извлечения знаний это обстоятельство становится принципиальным, так как позволяет на самом деле отделить те знания, благодаря которым эксперт является таковым (уровень В), от общезначимых, банальных (для экспертов в данной предметной области) знаний (уровень А), которые возможно и не стоят того, чтобы ради них создавать собственно экспертную систему.
Однако можно ожидать, что во многих (если не в большинстве) случаях выявленные латентные структуры могут полностью перевернуть представления инженера по знаниям о предметной области и позволить ему существенно углубить базу знаний. Введение мира метафор - это некая игра, а игра раскрепощает сознание эксперта и, как все игровые методики извлечения знаний (п. 4.2), является хорошим катализатором трудоемких серий интервью с экспертом, без которых сегодня невозможна разработка промышленных интеллектуальных систем.
|
|
|
|
|
Дата добавления: 2015-07-02; Просмотров: 2204; Нарушение авторских прав?; Мы поможем в написании вашей работы!