КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Приобретение знаний из текстов
|
|
|
|
Как было указано в параграфе 4.3, даже ручные методы выявления знаний из текста крайне слабо разработаны. В тех же немногих случаях, когда применяются автоматизированные методики, речь, как правило, идет о методах лексико-семантического анализа, а также о моделях понимания текста.
Наибольшую известность имеют модели понимания на лингвистическом уровне. Системы, основанные на них, состоят в большинстве случаев из двух частей:
• первая - морфологический и синтаксический анализ;
• вторая - семантический анализ, который использует результаты работы первой части, а также словарную или справочную информацию для построения формализованного образа текста.
Говоря о семантическом анализе текста, надо иметь в виду, что всякие отношения текста с его семантикой начинаются после того, как в нашем распоряжении оказывается некоторая модель действительности. Объектами этой модели, в частности, могут являться индивиды и отношения.
Таким образом, первая проблема, возникающая при попытках автоматического извлечения знаний из текста, - это выявление свойств элементов текста для соотнесения этих элементов с объектами модели. Крайне редко эти свойства присутствуют в тексте эксплицитно, то есть явно.
Вторая особенность существующих систем анализа текста - это, как правило, необходимость использования словаря предметной области для выполнения морфологического анализа, выделения имен и словосочетаний и т. д. Однако требование предварительного создания словаря предметной области одновременно сильно осложняет задачу и уменьшает степень универсальности получаемой системы.
Понимание текста на семантическом уровне предполагает выявление не только лингвистических, но и логических отношений между языковыми объектами [Апресян, 1974]. Среди подходов к пониманию текста на семантическом уровне следует выделить модели типа «смысл - текст», в частности, модель семантик предпочтения [Wilks, 1976], модель концептуальной зависимости [Хейес-Рот и др., 1987]. В модели «смысл - текст» [Мельчук, 1974] предлагается семантическое представление на основе семантического графа и описания коммуникативной структуры текста.
В системе KRITON [Diderich, Ruchman, May, 1987] анализ текста используется для выявления хорошо структурированных знаний из книг, документов, описаний, инструкций. Основанный на контент-анализе метод протокольного анализа используется для выявления процедурных знаний. Он осуществляется в пять шагов.
1. Протокол делится на сегменты на основании пауз, которые делает эксперт в процессе записи.
2. Семантический анализ сегментов, формирование высказываний для каждого сегмента.
3. Из текста выделяются операторы и аргументы.
4. Делается попытка поиска по образцу в БЗ для обнаружения переменных в высказываниях (переменная вставляется в высказывание, если соответствующая ссылка в тексте не обнаружена).
5. Утверждения упорядочиваются в соответствии с их появлением в протоколе.
В системе ТАКТ (Tool for Acquisition of Knowledge from Text) [Kaplan, Berry-Rogghe, 1991] предполагается предварительная подготовка (разметка посредством введения явной скобочной структуры) предложений текста до начала работы текстового анализатора. В результате анализа выделяются объекты, процессы и отношения каузального характера.
4.6.5. Инструментарий прямого приобретения знаний SIMER + MIR
Программная система SIMER + MIR, разработанная в ИПС РАН под руководством Осипова Г. С. [Осипов, 1997], представляет собой совокупность программных средств для формирования модели и базы знаний предметной области. Система ориентирована преимущественно на области с неясной структурой объектов, с неполно описанным множеством свойств объектов и богатым набором связей различной «связывающей силы» между объектами.
Одна из особенностей системы состоит в том, что ее использование на заключительном этапе не предполагает участия специалистов-разработчиков экспертных систем. Это означает, что система SIMER + MIR представляет собой технологию создания систем, основанных на знаниях о предметной области, причем технологию, ориентированную на экспертов.
Архитектура. Система SIMER + MIR включает модуль прямого приобретения знаний SIMER, систему моделирования рассуждений типа аргументации MIR, программу адаптации системы MIR к базе знаний, сформированной с помощью SIMER + и программной среды поддержки базы знаний, над которой работают все названные модули. Конструкции базы знаний создаются и просматриваются с помощью языка инженера знаний FORTE, который включается в технологию в специальных случаях (рис. 4.17).
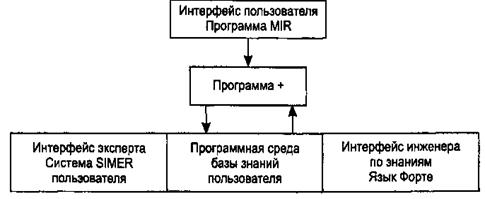
Рис. 4.17. Создание конструкции базы знаний с помощью языка FORTE
Представление и база знаний. Одним из наиболее распространенных видов экспертизы являются высказывания (сообщения) эксперта об объектах (событиях) предметной области. Эти высказывания имеют вид:
< имя объекта > < имя отношения > < имя объекта >.
Для ряда областей - медицины, экологии, политики, социологии - можно выделить формы сообщений, показанные в табл. 4.6:
Таблица 4.6. Формы сообщений
| Номер формы | Имя формы | |
| Ф1 | 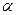 характерно для характерно для 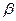
| |
| Ф2 | наблюдается при
| |
| Ф3 | отмечается при
| |
| Ф4 | есть проявление
| |
| Ф5 | есть признак
| |
| Ф6 | сопровождает
| |
| Ф7 | нередко сопровождается
| |
| Ф8 | При нередко присутствует
| |
| Ф9 | может наблюдаться при
| |
| Ф10 | обычно сопровождается
| |
| Ф11 | При как правило
| |
| Ф12 | При обычно
| |
| Ф13 | иногда сопровождается
| |
| Ф14 | часто сопровождается
| |
| Ф15 | исключает
| |
| Ф16 | приводит к
| |
| Ф17 | При возникает
| |
| Ф18 | может привести к
| |
| Ф19 | может развиваться в
| |
| Ф20 | С начинается
| |
| Ф21 | развивается при
| |
| Ф22 | может развиваться при
| |
| Ф23 | может начаться с
|
Этот список не является исчерпывающим, однако дает представление о тех когнитивных структурах, которые необходимо представлять и обрабатывать в базе знаний.
Каждая из этих форм может иметь различный смысл; уточнение смысла можно получить при рассмотрении «прямого» сообщения с «обращенным». Иными словами, если для некоторых фиксированных или справедливо сообщение формы Ф10, то необходимо попытаться установить, какое из сообщений Ф1 - Ф23 справедливо при замене на , на . Так, для сообщения «Гром наблюдается при грозе» справедливо «обращенное» сообщение «Гроза сопровождается громом», а для сообщения «Воспалительный процесс может наблюдаться при повышенной температуре» справедливо сообщение «Повышенная температура характерна для воспалительного процесса». Таким образом, смысл сообщений уточняется построением «конъюнкций» форм Ф1 - Ф23. Такие «конъюнкции» форм сообщений будут называться типами сообщений. Возможные типы сообщений приведены в табл. 4.7.
С каждым типом сообщения из табл. 4.7 связывается формальная конструкция базы знаний, то есть бинарное отношение на множестве объектов (событий). Эти конструкции можно проиллюстрировать следующим образом: если каждый объект (событие) представить в виде «двухмерного» множества, по первому измерению которого можно откладывать атрибуты этого объекта, а по второму - множества значений соответствующих атрибутов, то каждый объект представляется в виде фигуры:

Таблица 4.7. Типы сообщений
| Тип | Сообщение |
| Т1 | есть проявление , и может сопровождать
|
| Т2 | есть проявление , и сопровождается
|
| Т3 | может увеличивать возможность , и увеличивает возможность
|
| Т4 | может сопровождаться , и может быть проявлением
|
| Т5 | сопровождается , и может быть проявлением
|
| Т6 | есть проявление , и есть проявление
|
| Т7 | может увеличивать возможность , и может увеличивать возможность
|
| Т8 | может протекать с , и может протекать с
|
| Т9 | увеличивает возможность , и увеличивать возможность
|
| Т10 | сопровождается , и может сопровождает
|
| Т11 | сопровождается , и сопровождаться
|
| Т12 | исключает ,. и исключает
|
| Т13 | приводит к
|
| Т14 | может привести к
|
| Т15 | увеличивает возможность развития
|
| Т16 | может увеличить возможность развития
|
| Т17 | исключает возможность развития
|
Если считать множества всех атрибутов равновеликими, то можно рисовать прямоугольники.
Тогда типу сообщения Т1 можно поставить в соответствие диаграмму (пересечение и всюду далее заштриховано).

В качестве примера приведем интерпретации некоторых диаграмм. Так, диаграмму, соответствующую сообщению типа Т3, можно интерпретировать следующим образом: для всякого примера объекта качестве примера приведем интерпретации некоторых диаграмм. Так, диаграмму, соответствующую сообщению типа Т3, можно интерпретировать следующим образом: для всякого примера объекта найдутся такие примеры объекта , в которых равны совпадающие имена и значения атрибутов.
Для остальных типов сообщений получим диаграммы, представленные в табл. 4.8.
Таблица 4.8. Диаграммы для различных типов сообщений
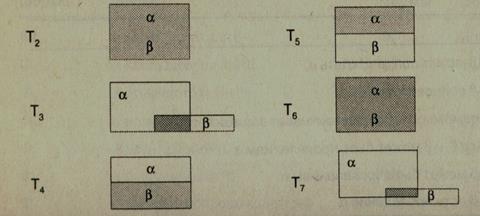
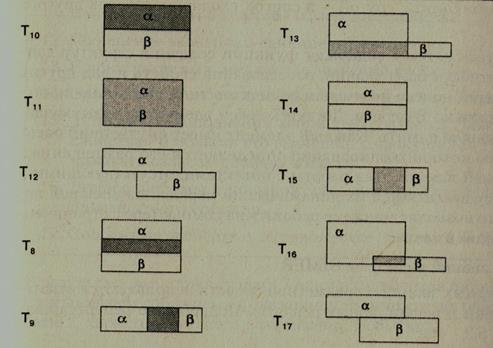
Для сообщения типа Т8: для всякого имени атрибута примера объекта найдется совпадающее с ним имя атрибута из примера объекта , и наоборот; при этом соответствующие значения атрибутов равны. Найдутся такие примеры объекта , в которых равны совпадающие имена и значения атрибутов.
Каждой из изображенных диаграмм можно дать такую теоретико-множественную интерпретацию, связав с каждым из типов сообщений Тi, некоторое бинарное отношение Rk примеров объектов (при k = i).
Способ представления с определенными так отношениями называется неоднородной семантической сетью.
В реализации базы знаний основными элементами структур данных являются элементы «вершина», «элемент кортежа», «атрибут», «цепь», «стрелка». Элемент «вершина» соответствует объекту (событию), он содержит имя, списки входных и выходных «стрелок» и список типа «элемент кортежа». Список «элементов кортежа» соответствует совокупности атрибутов события.
Для обеспечения простого способа определения указателя «вершины» существуют элементы типа «цепь». Элемент типа «цепь» содержит указатель на «вершину» и указатель на следующий элемент типа «цепь». Указатель на первый элемент списка «цепь» входит в описание элемента типа «атрибут». «Атрибут» характеризуется также именем, множеством значений и единицей измерения.
Отношения на множестве объектов реализованы в элементах типа «стрелка». Каждый такой элемент содержит имя, сорт, вес, тип веса, указатель на «вершину» и указатель на следующий элемент типа «стрелка». Отношения на двух объектах описываются парой элементов типа «стрелка», один из которых входит в список входящих стрелок одного объекта, другой - в список входящих стрелок другого объекта.
Процедурная компонента системы содержит функции создания структур данных, поддержки корректности базы знаний, наследования свойств и ряд других функций. Для обеспечения поиска по именам элементов типа «вершина» и «атрибут» в системе реализовано В-дерево. Доступ ко всем элементам базы осуществляется через виртуальную память. Каждый элемент имеет внутренний идентификатор, по значению которого однозначно определяется его размещение в оперативной или внешней памяти. Для работы с объектами, отсутствующими в оперативной памяти, осуществляется их динамический перенос из внешней памяти в оперативную. Это позволяет системе работать на компьютере с ограниченным объемом оперативной памяти.
|
|
|
|
|
Дата добавления: 2015-07-02; Просмотров: 520; Нарушение авторских прав?; Мы поможем в написании вашей работы!